作為軟件開發人員,我們的生活是快節奏的,我們采用的是敏捷軟件開發方法,迭代式的開發我們軟件功能,開發完成提交測試,通過了QA的測試後被部署到生產環境,然後可怕的事情在生產環境裡發生了,生產環境的壓力超過了我們的設計值,也就是說過載了,這種情況經常發生在調用遠程服務,因為沒有做過載保護,導致請求的資源阻塞在服務器上等待從而耗盡系統或者服務器資源,很多時候剛開始的時候只是系統出現了局部的,小規模的故障,然而由於種種原因,故障的范圍越來越大,最終導致了全局性的後果,墨菲定律在軟件裡面特別靈驗。俗話說就是"任何會出錯的,一定會出錯",我們如何來解決這個問題呢,這就有一個設計模式叫做熔斷器,可以用來解決過載保護問題。
我們在日常生活中有一種經常會碰到的現象,如果家裡用電負載過大,比如開了很多家用電器,就會"自動跳閘",此時電路就會斷開。在以前更古老的一種方式是"保險絲",當負載過大,或者電路發生故障或異常時,電流會不斷升高,為防止升高的電流有可能損壞電路中的某些重要器件或貴重器件,燒毀電路甚至造成火災。保險絲會在電流異常升高到一定的高度和熱度的時候,自身熔斷切斷電流,從而起到保護電路安全運行的作用。這個自動跳閘的裝置就是電路熔斷器,通常是用電磁鐵切斷電路而不是燃燒掉,熔斷器可以重復使用。我們在軟件中模仿電路熔斷器的組件模式就是CircuitBreaker。
在大型的分布式系統中,通常需要調用或操作遠程的服務或者資源,這些遠程的服務或者資源由於調用者不可以控的原因比如網絡連接緩慢,資源被占用或者暫時不可用等原因,導致對這些遠程資源的調用失敗。這些錯誤通常在稍後的一段時間內可以恢復正常。但是,在某些情況下,由於一些無法預知的原因導致結果很難預料,遠程的方法或者資源可能需要很長的一段時間才能修復。這種錯誤嚴重到系統的部分失去響應甚至導致整個服務的完全不可用。在這種情況下,采用不斷地重試可能解決不了問題,相反,應用程序在這個時候應該立即返回並且報告錯誤。
通常,如果一個服務器非常繁忙,那麼系統中的部分失敗可能會導致 "連鎖失效"(cascading failure)。比如,某個操作可能會調用雲端的服務,這個service會設置一個超時的時間,如果響應時間超過了該時間就會拋出一個異常。但是這種策略會導致並發的請求調用同樣的操作會阻塞,一直等到超時時間的到期。這種對請求的阻塞可能會占用寶貴的系統資源,如內存,線程,數據庫連接等等,最後這些資源就會消耗殆盡,使得其他系統不相關的部分所使用的資源也耗盡從而拖累整個系統。在這種情況下,操作立即返回錯誤而不是等待超時的發生可能是一種更好的選擇。只有當調用服務有可能成功時我們再去嘗試。
熔斷器設計模式
馬丁大叔總結的熔斷器模式http://martinfowler.com/bliki/CircuitBreaker.html ,熔斷器模式可以防止應用程序不斷地嘗試執行可能會失敗的操作,使得應用程序繼續執行而不用等待修正錯誤,或者浪費CPU時間去等到長時間的超時產生。熔斷器模式也可以使應用程序能夠診斷錯誤是否已經修正,如果已經修正,應用程序會再次嘗試調用操作。
熔斷器模式就像是那些容易導致錯誤的操作的一種代理。這種代理能夠記錄最近調用發生錯誤的次數,然後決定使用允許操作繼續,或者立即返回錯誤。
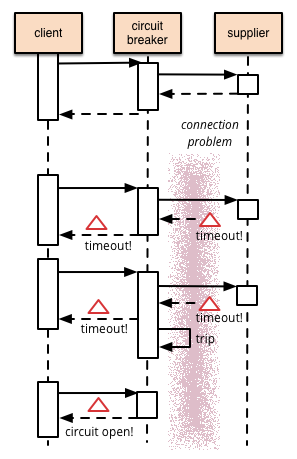
熔斷器可以使用狀態機來實現,內部模擬以下幾種狀態。
各個狀態之間的轉換如下圖:
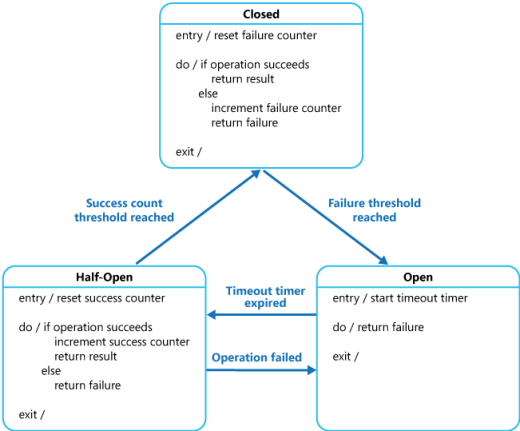
在Close狀態下,錯誤計數器是基於時間的。在特定的時間間隔內會自動重置。這能夠防止由於某次的偶然錯誤導致熔斷器進入斷開狀態。觸發熔斷器進入斷開狀態的失敗阈值只有在特定的時間間隔內,錯誤次數達到指定錯誤次數的阈值才會產生。在Half-Open狀態中使用的連續成功次數計數器記錄調用的成功次數。當連續調用成功次數達到某個指定值時,切換到閉合狀態,如果某次調用失敗,立即切換到斷開狀態,連續成功調用次數計時器在下次進入半斷開狀態時歸零。
實現熔斷器模式使得系統更加穩定和有彈性,在系統從錯誤中恢復的時候提供穩定性,並且減少了錯誤對系統性能的影響。它通過快速的拒絕那些試圖有可能調用會導致錯誤的服務,而不會去等待操作超時或者永遠不會不返回結果來提高系統的響應事件。如果熔斷器設計模式在每次狀態切換的時候會發出一個事件,這種信息可以用來監控服務的運行狀態,能夠通知管理員在熔斷器切換到斷開狀態時進行處理。
可以對熔斷器模式進行定制以適應一些可能會導致遠程服務失敗的特定場景。比如,可以在熔斷器中對超時時間使用不斷增長的策略。在熔斷器開始進入斷開狀態的時候,可以設置超時時間為幾秒鐘,然後如果錯誤沒有被解決,然後將該超時時間設置為幾分鐘,依次類推。在一些情況下,在斷開狀態下我們可以返回一些錯誤的默認值,而不是拋出異常。
上述內容來自在MSDN的一篇文章Circuit Breaker Pattern。文章中列出了要考慮的因素:
在實現熔斷器模式的時候,以下這些因素可能需要考慮:
熔斷器使用場景
應該使用該模式來:
不適合的場景
有很多類庫都實現了熔斷器設計模式,這裡我們介紹一個叫做Polly的項目。它是一個非常整潔的包,為我們提供很多種熔斷器。它涵蓋了大多數的異常處理像重試,重試並等待的策略,Polly使用起來也非常簡單,下面是Polly的使用方法:
// Break the circuit after the specified number of exceptions
// and keep circuit broken for the specified duration
var policy = Policy
.Handle<DivideByZeroException>()
.CircuitBreaker(2, TimeSpan.FromMinutes(1));
var result = poilcy.Execute(() => DoSomething());
如果DoSomething() 引發了DivideByZeroException 2次熔斷器斷開一分鐘。使用起來非常的簡單吧,更詳細的請參看文章 《Circuit Breaking With Polly》http://blog.jaywayco.co.uk/circuit-breaking-with-polly/ ,微軟已經在一些核心組件裡考慮了重試,有一個例子就是EF 6可以非常方便的實現重試策略,具體可以參看文章《Entity Framework Connection Resiliency and Polly》http://blog.jaywayco.co.uk/entity-framework-connection-resiliency/ 。
在應用系統中,我們通常會去調用遠程的服務或者資源(這些服務或資源通常是來自第三方),對這些遠程服務或者資源的調用通常會導致失敗,或者掛起沒有響應,直到超時的產生。在一些極端情況下,大量的請求會阻塞在對這些異常的遠程服務的調用上,會導致一些關鍵性的系統資源耗盡,從而導致級聯的失敗,從而拖垮整個系統。熔斷器模式在內部采用狀態機的形式,使得對這些可能會導致請求失敗的遠程服務進行了包裝,當遠程服務發生異常時,可以立即對進來的請求返回錯誤響應,並告知系統管理員,將錯誤控制在局部范圍內,從而提高系統的穩定性和可靠性。