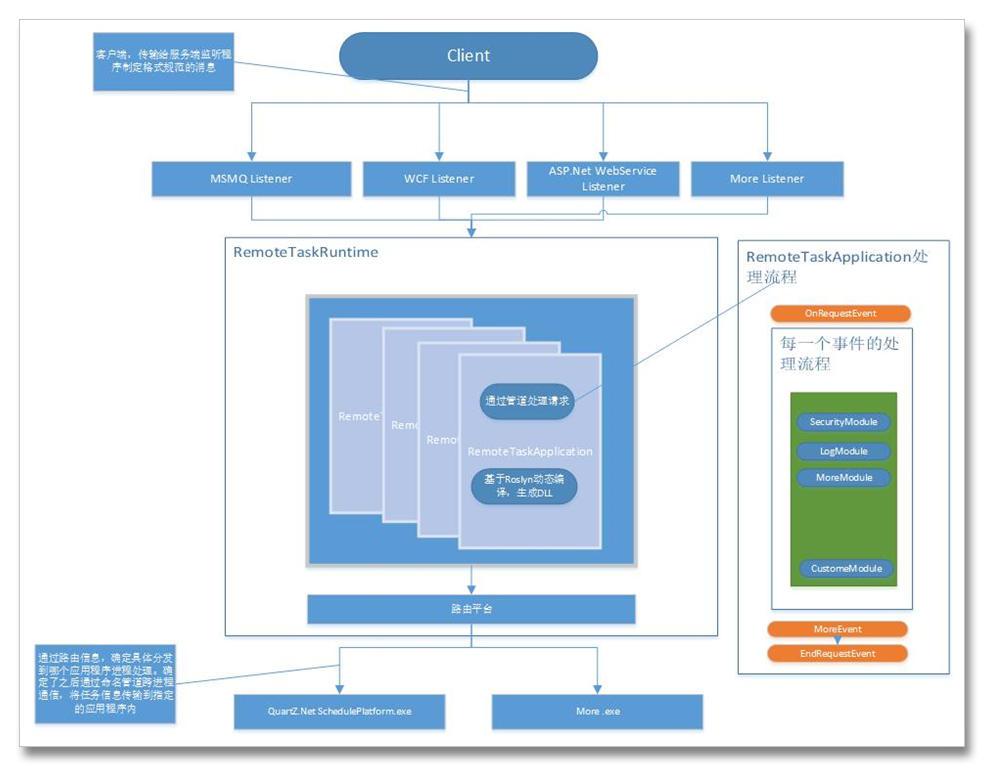
了解Dictionary的開發人員都了解,和List相比,字典添加會慢,但是查找會比較快,那麼Dictionary是如何實現的呢?
下面的代碼我看看Dictionary在構造時都做了什麼:
private void Initialize(int capacity)
{
int prime = HashHelpers.GetPrime(capacity);
this.buckets = new int[prime];
for (int i = 0; i < this.buckets.Length; i++)
{
this.buckets[i] = -1;
}
this.entries = new Entry<TKey, TValue>[prime];
this.freeList = -1;
}
我們看到,Dictionary在構造的時候做了以下幾件事:
其中this.buckets主要用來進行Hash碰撞,this.entries用來存儲字典的內容,並且標識下一個元素的位置。
我們以Dictionary<int,string> 為例,來展示一下Dictionary如何添加元素:
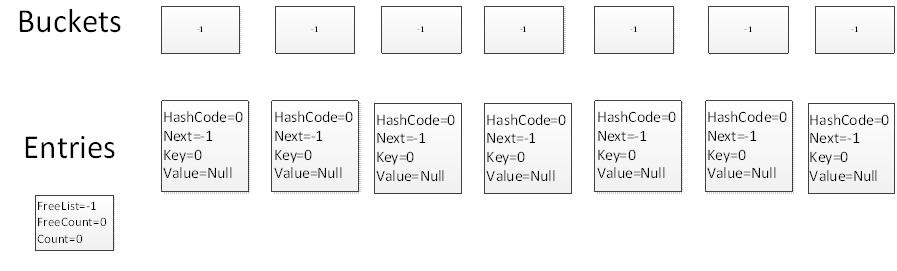
首先,我們構造一個:
Dictionary<int, string> test = new Dictionary<int, string>(6);
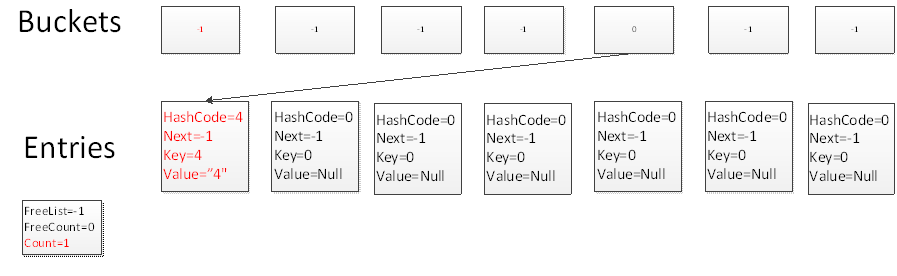
根據Hash算法: 4.GetHashCode()%7= 4,因此碰撞到buckets中下標為4的槽上,此時由於Count為0,因此元素放在Entries中第0個元素上,添加後Count變為1
根據Hash算法 11.GetHashCode()%7=4,因此再次碰撞到Buckets中下標為4的槽上,由於此槽上的值已經不為-1,此時Count=1,因此把這個新加的元素放到entries中下標為1的數組中,並且讓Buckets槽指向下標為1的entries中,下標為1的entry之下下標為0的entries。
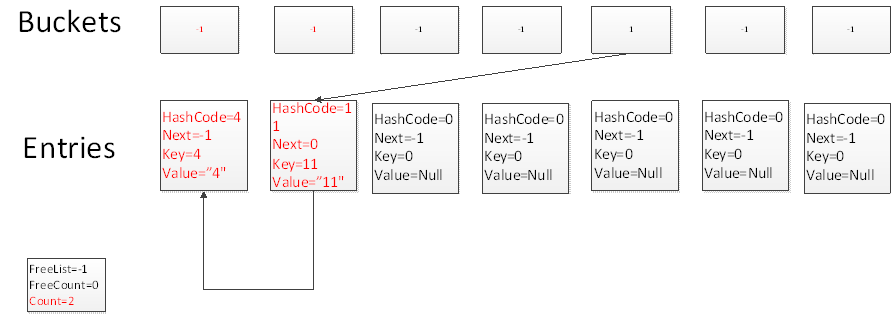
我們添加18,讓HashCode再次碰撞到Buckets中下標為4的槽上,這個時候新元素添加到count+1的位置,並且Bucket槽指向新元素,新元素的Next指向Entries中下標為1的元素。此時你會發現所有hashcode相同的元素都形成了一個鏈表,如果元素碰撞次數越多,鏈表越長。所花費的時間也相對較多。
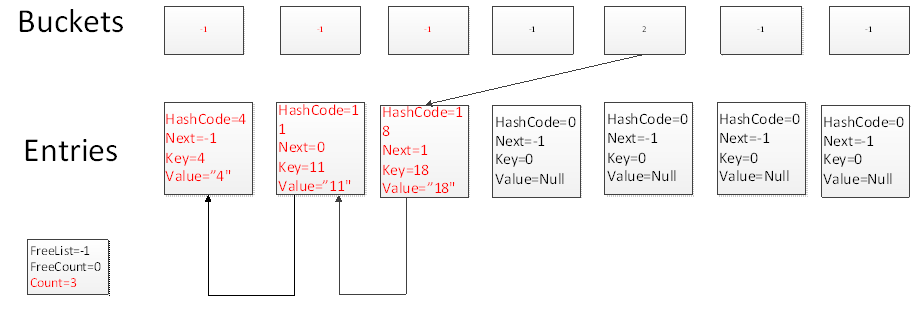
再次添加元素19,此時Hash碰撞到另外一個槽上,但是元素仍然添加到count+1的位置。
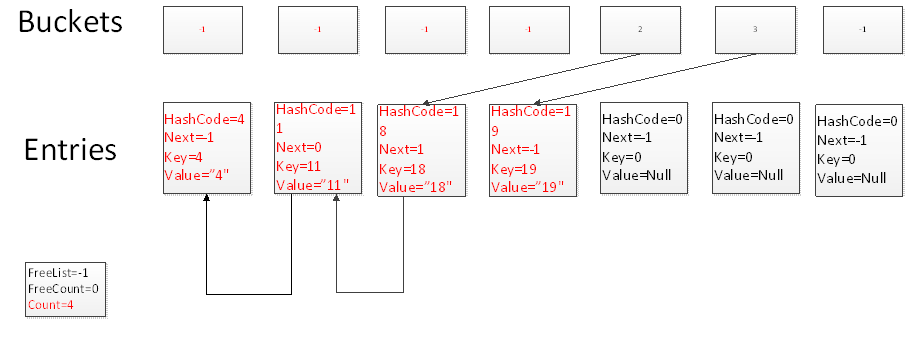
我們刪除元素時,通過一次碰撞,並且沿著鏈表尋找3次,找到key為4的元素所在的位置,刪除當前元素。並且把FreeList的位置指向當前刪除元素的位置,FreeCount置為1

刪除Key為18的元素,仍然通過一次碰撞,並且沿著鏈表尋找2次,找到當前元素,刪除當前元素,並且讓FreeList指向當前元素,當前元素的Next指向上一個FreeList元素。
此時你會發現FreeList指向了一個鏈表,鏈表裡面不包含任何元素,FreeCount表示不包含元素的鏈表的長度。
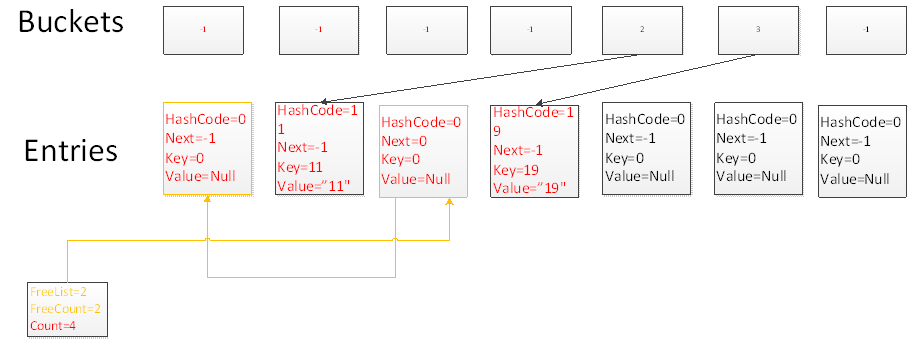
再添加一個元素,此時由於FreeList鏈表不為空,因此字典會優先添加到FreeList鏈表所指向的位置,添加後FreeCount減1,FreeList鏈表長度變為1
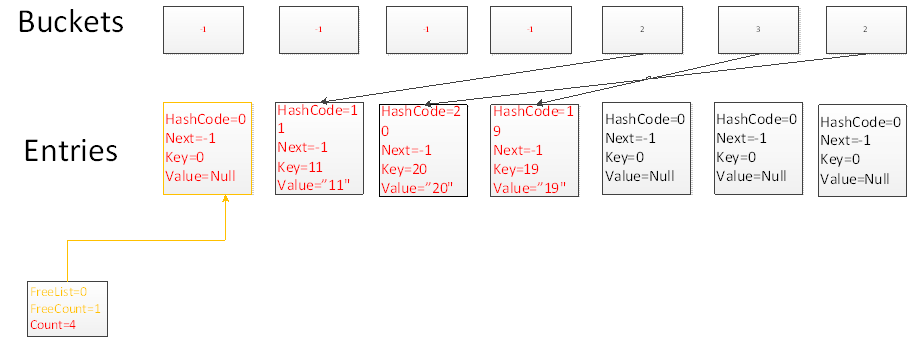
通過以上試驗,我們可以發現Dictionary在添加,刪除元素按照如下方法進行:
好吧,熬了半宿,今天先寫到這了,如果看了有所收獲就幫忙頂一下,有問題歡迎拍磚。