兩周前,做的一個項目需要模擬一批用戶評價數據,如果想讓數據看著真實點,那就得使用隨機的用戶昵稱和頭像啊。要是頭像或者昵稱全都差不多,那別人一看就看出來這是做的數據了。
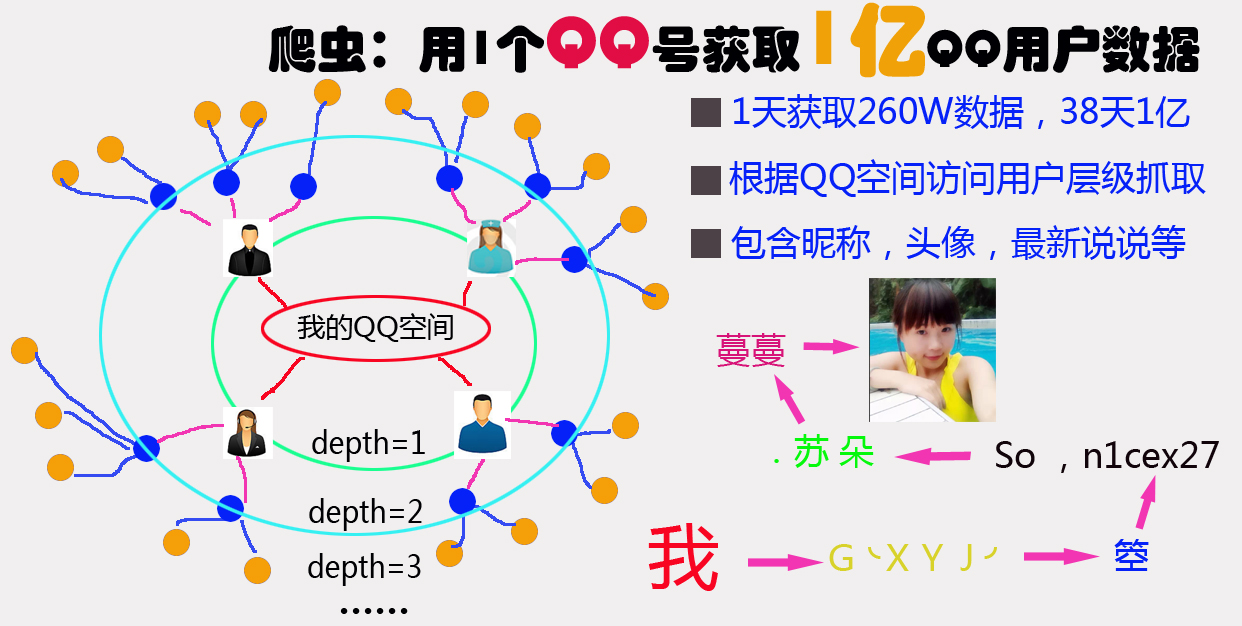
於是乎我就寫了個從我QQ空間開始的蜘蛛網式的爬蟲程序,程序斷斷續續的運行了兩周。總共爬到了騰訊3000萬QQ數據,其中有300萬包含用戶(QQ號,昵稱,空間名稱,會員級別,頭像,最新一條說說內容,最新說說的發表時間,空間簡介,性別,生日,所在省份,城市,婚姻狀況)的詳細數據。
目前已經爬到我的第7圈好友(depth=7)共3000萬數據,目前的瓶頸在家裡的網速和電腦的配置上。 最快的時候爬取速度達到一天500W新Q數據。
沒圖,我說個毛線啊!
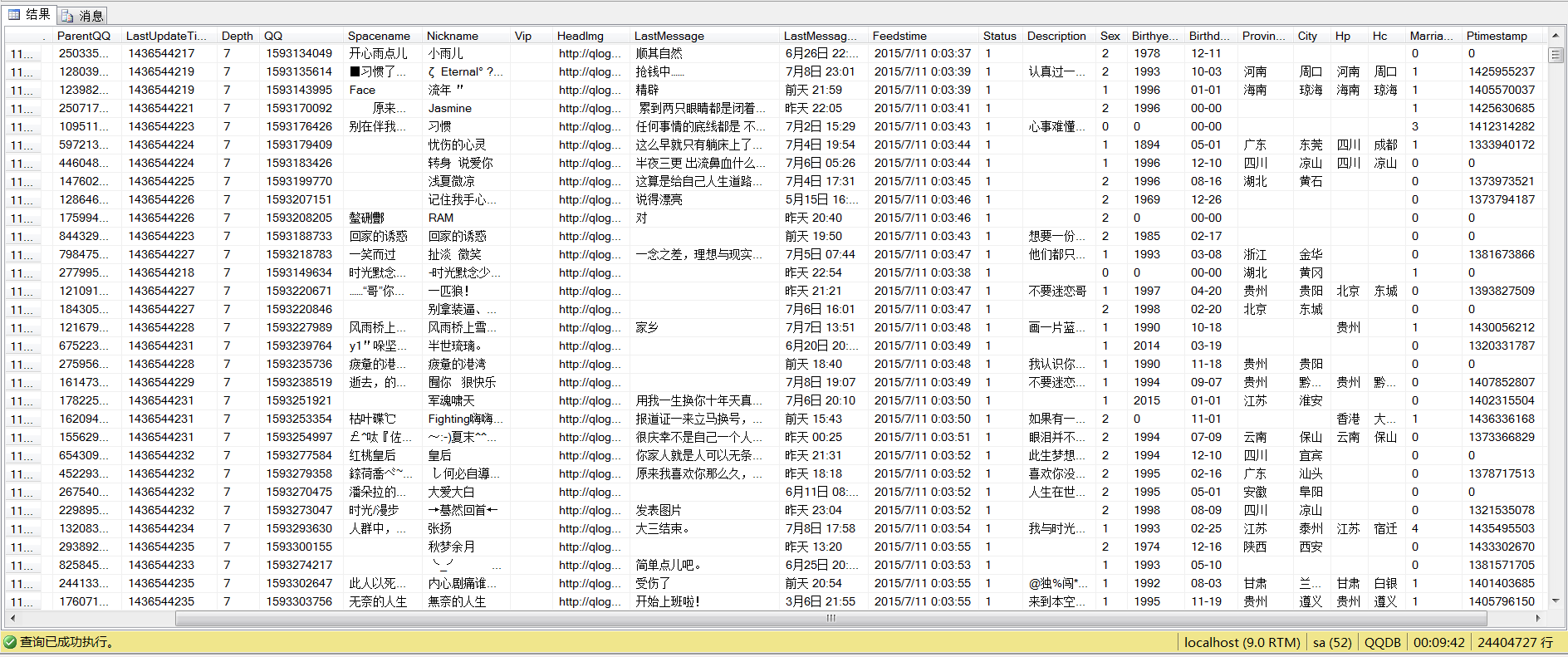
目前數據量為2G左右。
再看看,我根據這份數據生成的一些有趣的統計圖(數據量太大了一次加載到內存中直接報內存不夠了,所以下面的統計數據只取了depth值小數據較完整約80W的數據):
內存已經爆了,不能怪我。 誰贊助台服務器吧

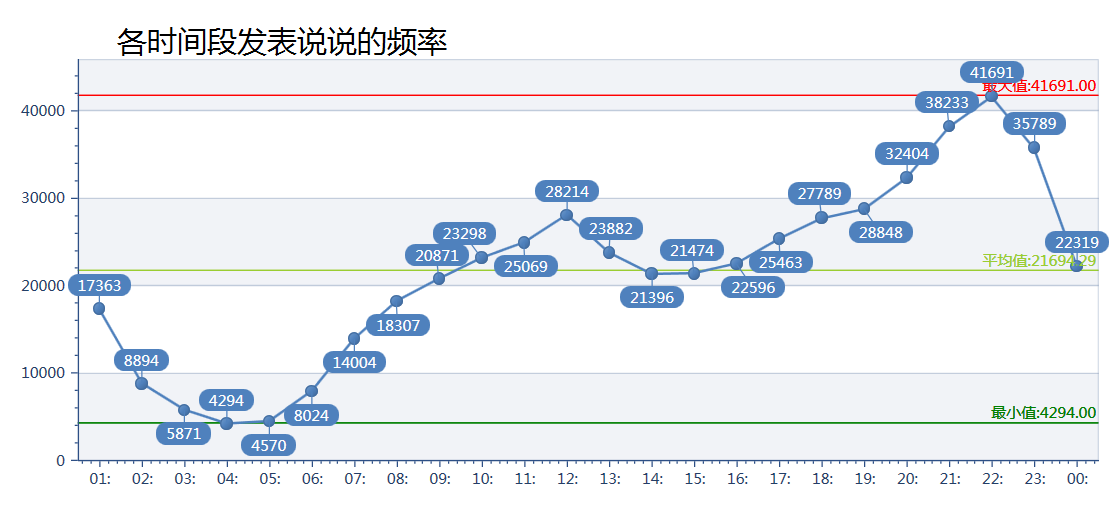
1、大家一般都在啥時候發說說呢?
從圖中看出一天最冷門的時候是凌晨4點,這時全國正在睡覺的人最多。 大家最亢奮的是晚上10點到11點,人們都喜歡睡前看看別人的空間,發條說說。中午12點左右也有一波小高峰
一會我再統計張中國人習慣幾點起床,幾點吃飯,幾點睡覺的圖吧
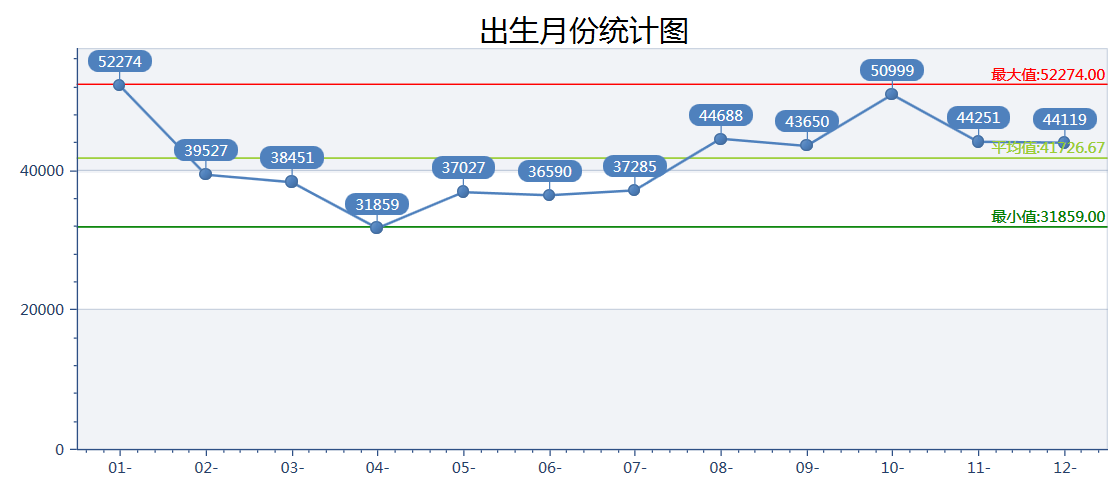
2、中國人都喜歡在幾月生小孩呢?
最熱門的是1月份和10月份,最冷門的是4月份。10月份生小孩的多好理解,一年忙差不多了,天氣也不冷不熱正是生小孩的好時候。 但1月份最高且和2月落差很大有點不好理解,那麼冷的天生不怕凍嗎? 我估計是1月份也快過年了,以前沒聚一起的好不容易聚一起了,就容易沖動,沖動就啪啪啪。 4月份生日的最少也好理解,中國人不喜歡4這個數字呗。 大數據有意思吧!! 我覺得太好玩了,後面還有很多呢。
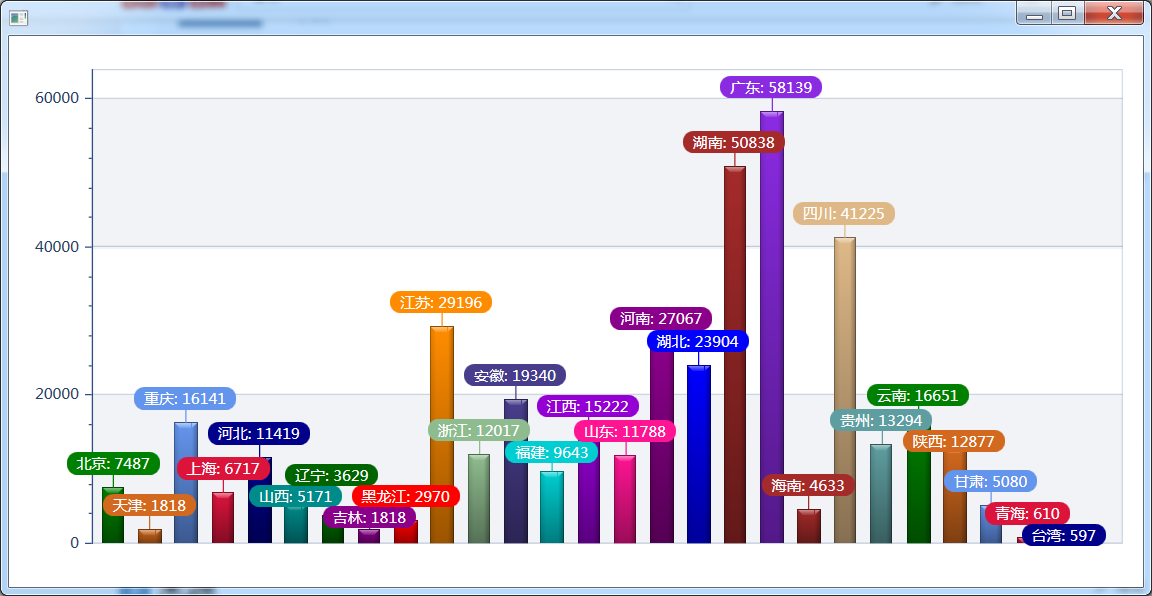
3、這是我目前爬取的用戶所在地分布
你能猜出我是哪的了嗎?前四名分別為:廣東,湖南,四川,江蘇。 沒錯,我就是湖南的! 湖南人在廣東打工的超級多,這也能理解為什麼廣東排名第一了。江蘇是我上學的地方,有點琢磨不透的是四川和我非情非故的居然排第3名,我的朋友們,你們是誰播的種?站出來! 還有一種可能,四川人交際能力全國第一,我平時在重慶小面吃飯,四川人確實特別,說話語速那個快啊,聲調那個高啊。受不了!
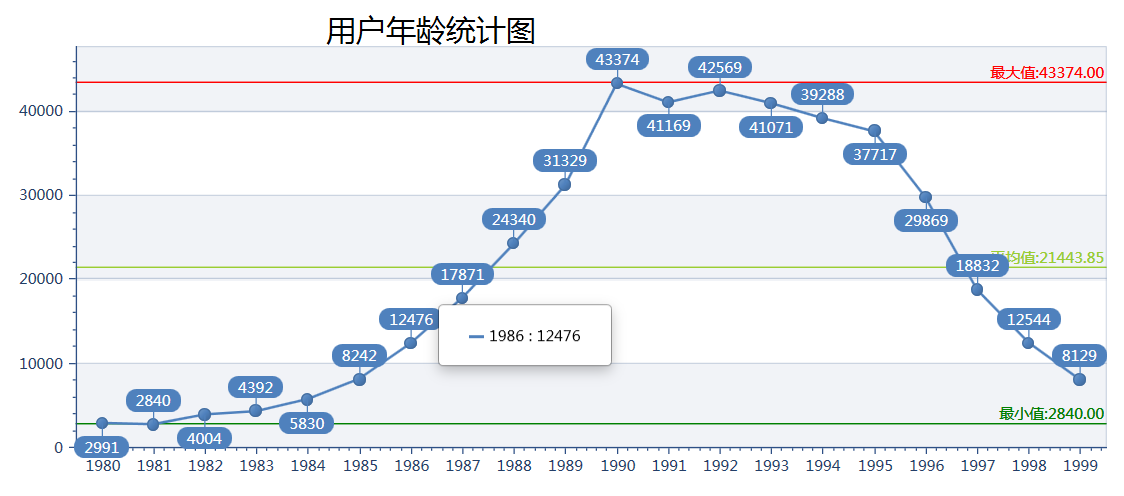
4、數據人群的年齡分布
一不小心就暴漏了我的年齡,沒錯。我就是那個最高值的1990年;從目前的數據來看,無論是分布地區以及年齡階段與我的關聯還非常大,隨著數據量的不斷增加這種關聯會逐漸變小,統計圖也會逐漸接近全國用戶的真實情況。真想弄幾台服務器分布式搞起,估計一周就能爬上億的簡單數據。 單靠我的筆記本和家裡超爛的網速達到這個目標還很遠。
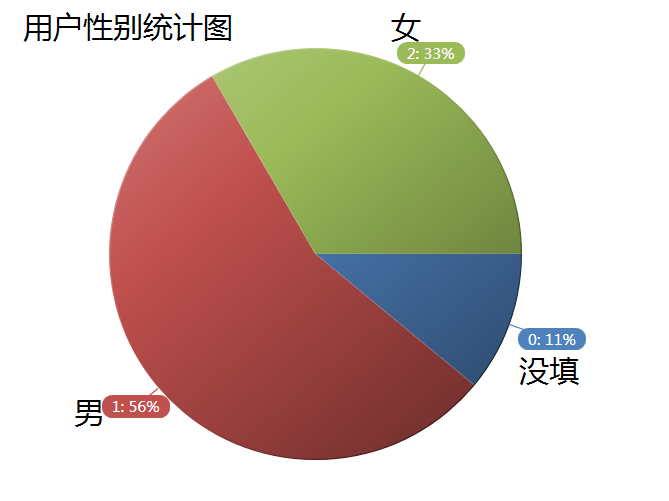
5、數據人群性別分布
男比女足足多了23%的人數,我分析認為實際差距應該是不大的,但女生在設置QQ空間訪問權限時普遍要比男生的高。所以我爬取的數據中男生居多。
6、下面系列圖是根據一些“關鍵字”在說說中出現的頻率統計出來的,相當有意思。
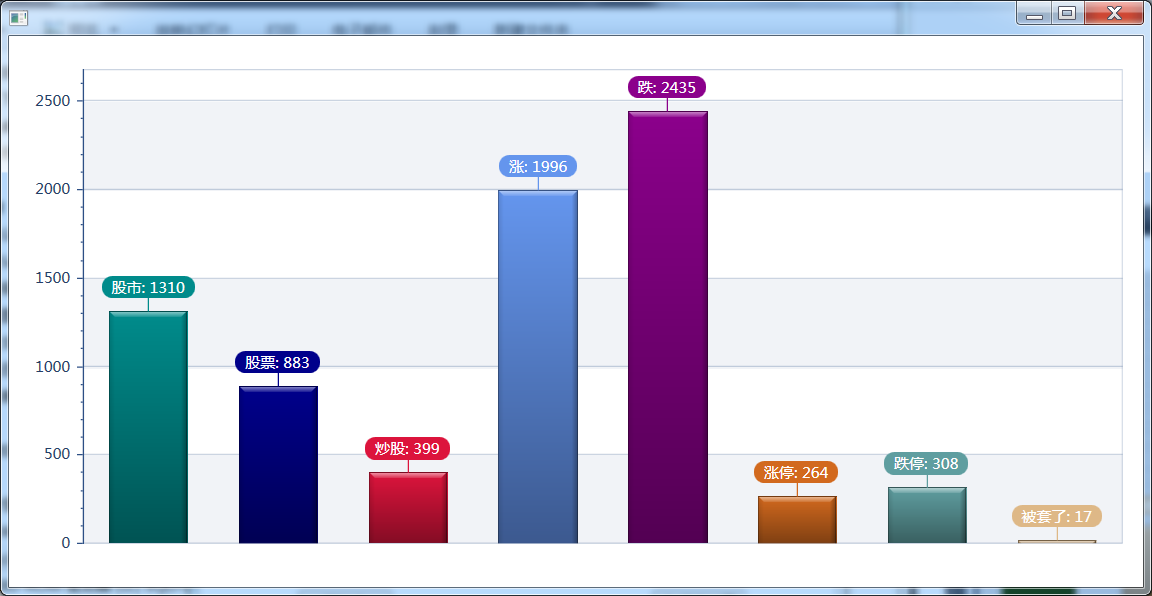
6.1 圖說股市
在知乎“能利用爬蟲技術做到哪些很酷很有趣很有用的事情?” 有一個google實習的哥們@Emily L爬了400億條tweet也做了很多有趣的分,其中提到一篇關於利用twitter上人的心情來預測股市的論文(http://battleofthequants.net/wp-content/uploads/2013/03/2010-10-15_JOCS_Twitter_Mood.pdf)很有意思。另附我在該問題下的答案“用爬蟲監測她(他)的知乎動態”,僅做技術玩樂,求別再噴我猥瑣了。
如果當我們擁有海量的QQ空間最新說說,和sina微博數據。我想,用它們來做一些股市或者其它方面的分析預測是可行的,准確度應該也是非常高的。我接下來可能會考慮去做這件有趣的事情。
將股票中的關鍵字做海量數據分析,比如會得出當日討論股票排行榜。進而能得到海量討論股票的用戶,再通過市場的實際反饋找出股票上漲及下跌的正相關因子,再對這些海量用戶進行分析計算得出最靠譜股票推薦大神排行榜。對這些用戶分級,分優先度及抓取密度來拿數據。用這些數據分析出哪些是靠譜的股票肯定靠譜。
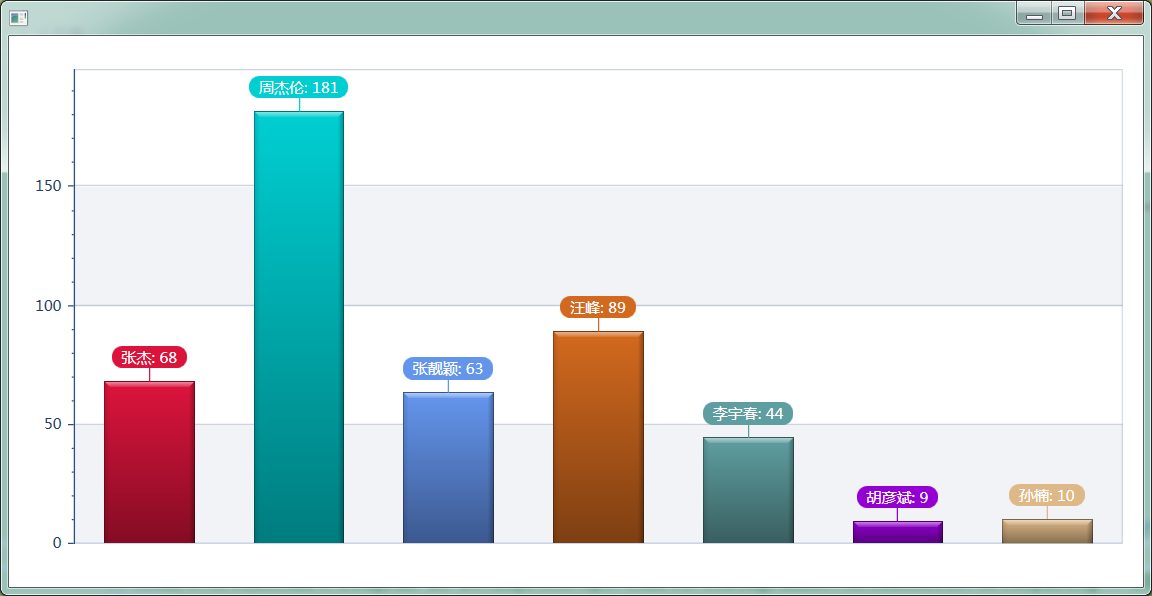
6.2 群眾討論最多的明星排行榜,還是很靠譜的。
另附我抓的明星QQ號吧,純屬娛樂,自辯真假。有些空間確實有很多生活私照。
張傑QQ:419998 花千骨的趙麗穎QQ:427794 謝娜QQ:500746 楊冪QQ:456773 范冰冰QQ:88597 周傑倫QQ:332661
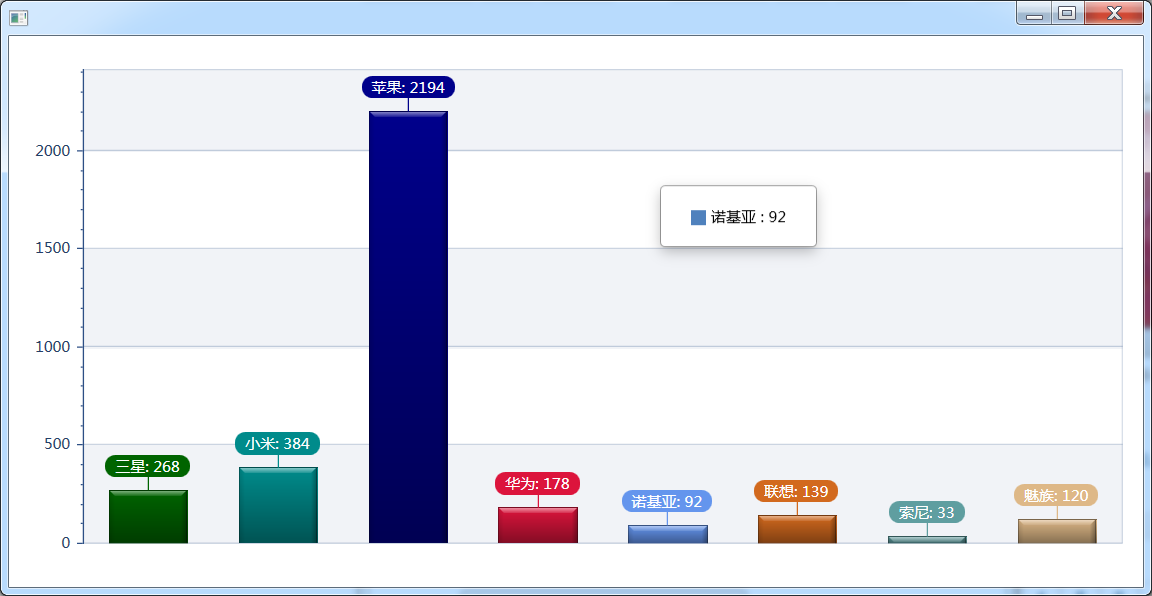
6.3 最為用戶喜愛的手機品牌
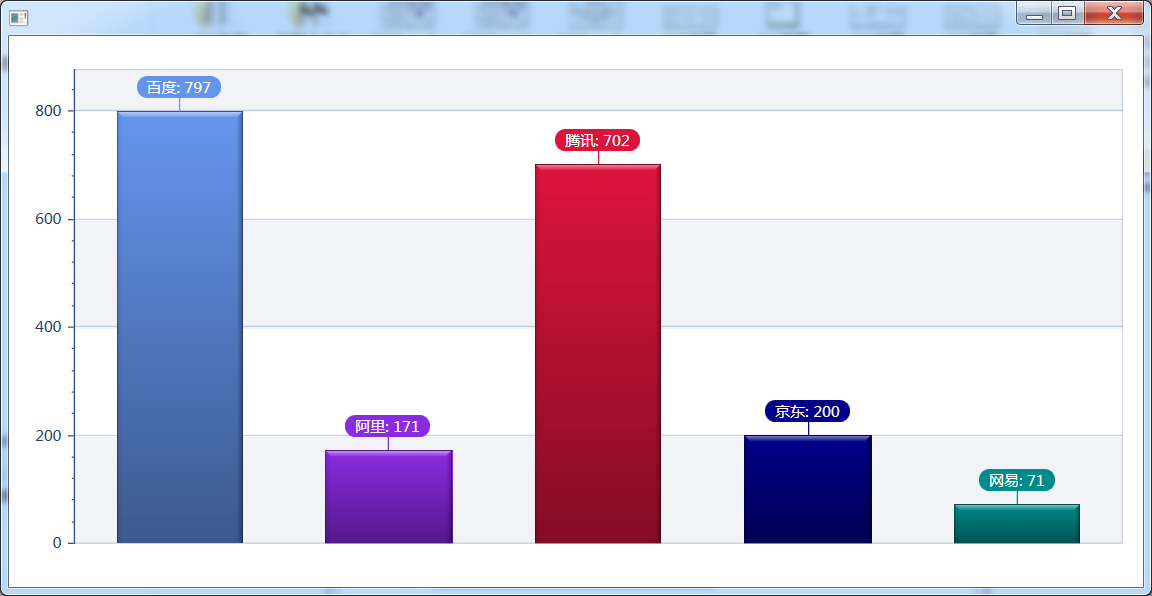
6.4 人們最喜歡談論的互聯網公司,阿裡之所以這麼低估計是大家都喜歡叫它淘寶或者天貓吧。 取這麼多名字,自討苦吃。
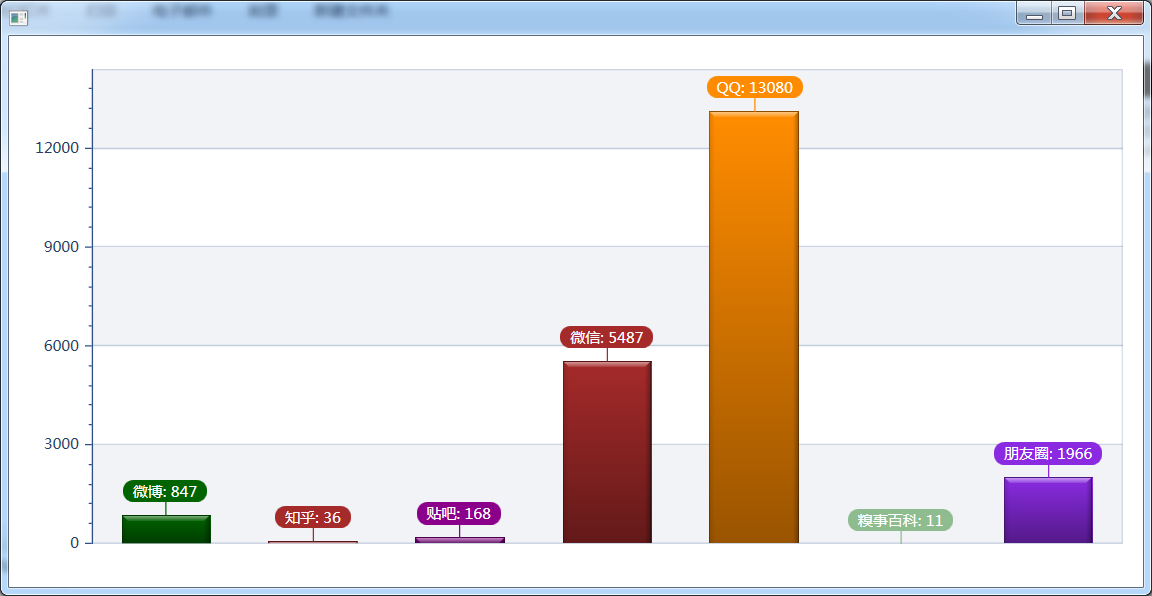
6.5 QQ空間中討論的最為頻繁的社交平台排行榜。
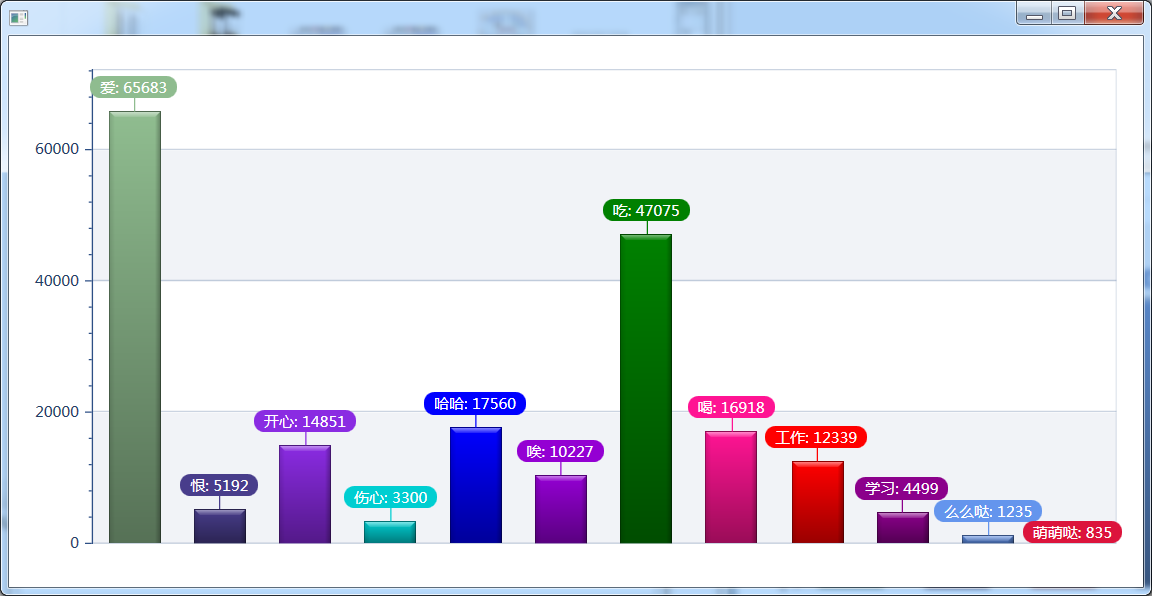
6.6 生活的統計圖
愛>恨; 開心>傷心; 笑聲>歎氣聲; 吃貨很多; 誰特麼說中國不幸福了,這滿滿的都是正能量數據啊。
好了,其實還可以做很多其它的分析。如果大家有什麼有趣的數據分析想知道的,那就給我留言吧。
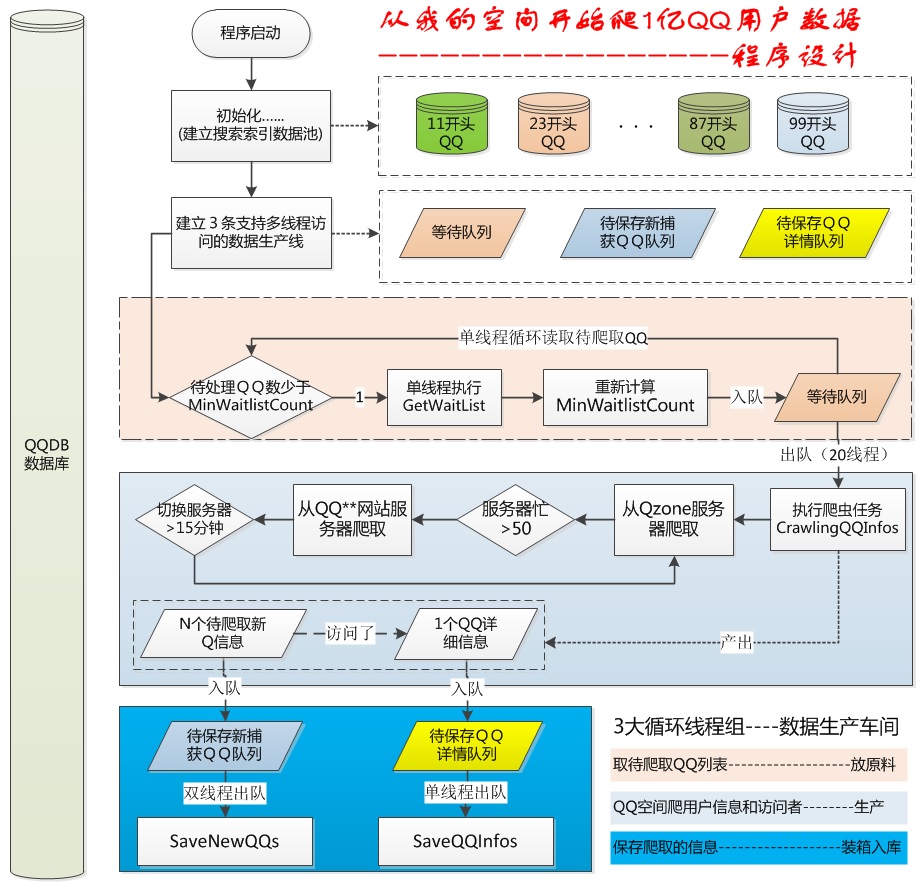
技術不多說了,程序不難,多線程數據庫操作卻是把我搞苦了。還好,現在程序差不多穩定了。過程也是很有意思的,有空我再寫個程序升級過程中的那些趣事吧。我覺得一個美妙的程序一定是高度模擬現實的,就像飛機模仿蜻蜓,雷達模仿蝙蝠一樣。 這次的程序設計就是模擬的工廠的生產線。附個設計圖吧
另外廣泛征集大家的聰明點子, 能否用這些數據做一個有趣的網站,app。 有趣或者能賺點小錢都行,只要不違法。
歡迎大家提出好的建議,不甚感激,歡迎轉載。 如有需要聯系([email protected])