在推薦系統眾多方法中,基於用戶的協同過濾推薦算法是最早誕生的,原理也較為簡單。該算法1992年提出並用於郵件過濾系統,兩年後1994年被 GroupLens 用於新聞過濾。一直到2000年,該算法都是推薦系統領域最著名的算法。
本文簡單介紹基於用戶的協同過濾算法思想以及原理,最後基於該算法實現園友的推薦,即根據你關注的人,為你推薦博客園中其他你有可能感興趣的人。
俗話說“物以類聚、人以群分”,拿看電影這個例子來說,如果你喜歡《蝙蝠俠》、《碟中諜》、《星際穿越》、《源代碼》等電影,另外有個人也都喜歡這些電影,而且他還喜歡《鋼鐵俠》,則很有可能你也喜歡《鋼鐵俠》這部電影。
所以說,當一個用戶 A 需要個性化推薦時,可以先找到和他興趣相似的用戶群體 G,然後把 G 喜歡的、並且 A 沒有聽說過的物品推薦給 A,這就是基於用戶的系統過濾算法。
根據上述基本原理,我們可以將基於用戶的協同過濾推薦算法拆分為兩個步驟:
1. 找到與目標用戶興趣相似的用戶集合
2. 找到這個集合中用戶喜歡的、並且目標用戶沒有聽說過的物品推薦給目標用戶
通常用 Jaccard 公式或者余弦相似度計算兩個用戶之間的相似度。設 N(u) 為用戶 u 喜歡的物品集合,N(v) 為用戶 v 喜歡的物品集合,那麼 u 和 v 的相似度是多少呢:
Jaccard 公式:
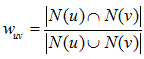
余弦相似度:
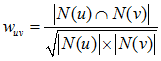
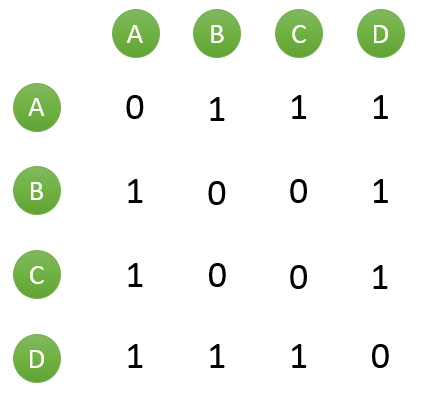
假設目前共有4個用戶: A、B、C、D;共有5個物品:a、b、c、d、e。用戶與物品的關系(用戶喜歡物品)如下圖所示:

如何一下子計算所有用戶之間的相似度呢?為計算方便,通常首先需要建立“物品—用戶”的倒排表,如下圖所示:

然後對於每個物品,喜歡他的用戶,兩兩之間相同物品加1。例如喜歡物品 a 的用戶有 A 和 B,那麼在矩陣中他們兩兩加1。如下圖所示:
計算用戶兩兩之間的相似度,上面的矩陣僅僅代表的是公式的分子部分。以余弦相似度為例,對上圖進行進一步計算:

到此,計算用戶相似度就大功告成,可以很直觀的找到與目標用戶興趣較相似的用戶。
首先需要從矩陣中找出與目標用戶 u 最相似的 K 個用戶,用集合 S(u, K) 表示,將 S 中用戶喜歡的物品全部提取出來,並去除 u 已經喜歡的物品。對於每個候選物品 i ,用戶 u 對它感興趣的程度用如下公式計算:
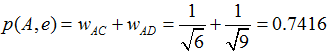
其中 rvi 表示用戶 v 對 i 的喜歡程度,在本例中都是為 1,在一些需要用戶給予評分的推薦系統中,則要代入用戶評分。
舉個例子,假設我們要給 A 推薦物品,選取 K = 3 個相似用戶,相似用戶則是:B、C、D,那麼他們喜歡過並且 A 沒有喜歡過的物品有:c、e,那麼分別計算 p(A, c) 和 p(A, e):
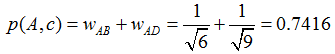
看樣子用戶 A 對 c 和 e 的喜歡程度可能是一樣的,在真實的推薦系統中,只要按得分排序,取前幾個物品就可以了。
在社交網絡的推薦中,“物品”其實就是“人”,“喜歡一件物品”變為“關注的人”,這一節用上面的算法實現給我推薦 10 個園友。
由於只是為我一個人做用戶推薦,所以沒必要建立一個龐大的用戶兩兩之間相似度的矩陣了,與我興趣相似的園友只會在這個群體產生:我關注的人的粉絲。除我自己之外,目前我一共關注了23名園友,這23名園友一共有22936個唯一粉絲,我對這22936個用戶逐一計算了相似度,相似度排名前10的用戶及相似度如下:
這10名相似用戶一共推薦了25名園友,計算得到興趣度並排序:
只需要按需要取相似度排名前10名就可以了,不過看起來整個列表的推薦質量都還不錯!
項亮:《推薦系統實踐》
本文地址:http://www.cnblogs.com/technology/p/4467895.html