本文會闡述六個重要的概念:堆、棧、值類型、引用類型、裝箱和拆箱。本文首先會通過闡述當你定義一個變量之後系統內部發生的改變開始講解,然後將關注點轉移到存儲雙雄:堆和棧。之後,我們會探討一下值類型和引用類型,並對有關於這兩種類型的重要基礎內容做一個講解。
本文會通過一個簡單的代碼來展示在裝箱和拆箱過程中所帶來的性能上的影響,請各位仔細閱讀。

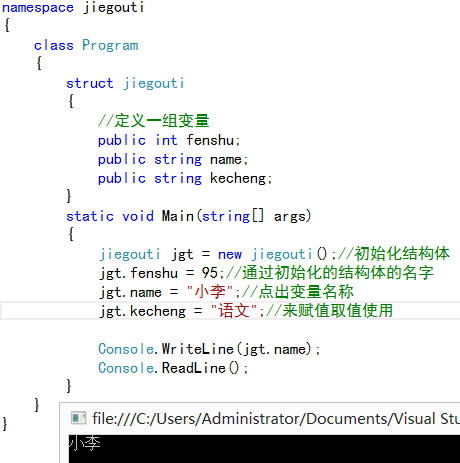
當你在一個.NET應用程序中定義一個變量時,在RAM中會為其分配一些內存塊。這塊內存有三樣東西:變量的名稱、變量的數據類型以及變量的值。
上面簡單闡述了內存中發生的事情,但是你的變量究竟會被分配到哪種類型的內存取決於數據類型。在.NET中有兩種可分配的內存:棧和堆。在接下來的幾個部分中,我們會試著詳細地來理解這兩種類型的存儲。
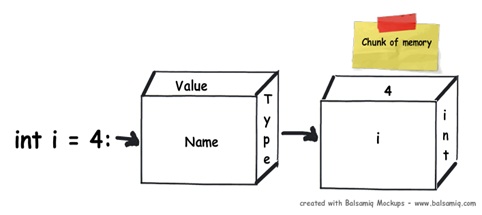
為了理解棧和堆,讓我們通過以下的代碼來了解背後到底發生了什麼。
1 2 3 4 5 6 7 8 9 10 11public void Method1()
{
// Line 1
int i=4;
// Line 2
int y=2;
//Line 3
class1 cls1 = new class1();
}
代碼只有三行,現在我們可以一行一行地來了解到底內部是怎麼來執行的。
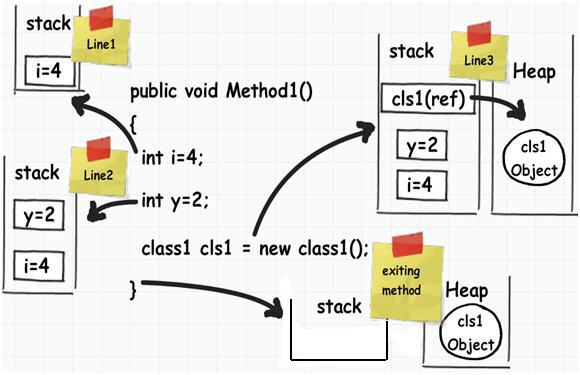
現在我們許多的開發者朋友一定很好奇為什麼會有兩種不同類型的存儲?我們為什麼不能將所有的內存塊分配只到一種類型的存儲上?
如果你觀察足夠仔細,基元數據類型並不復雜,他們僅僅保存像 ‘int i = 0’這樣的值。對象數據類型就復雜了,他們引用其他對象或其他基元數據類型。換句話說,他們保存其他多個值的引用並且這些值必須一一地存儲在內存中。對象類型需要的是動態內存而基元類型需要靜態內存。如果需求是動態內存的話,那麼它將會在堆上為其分配內存,相反,則會在棧上為其分配。
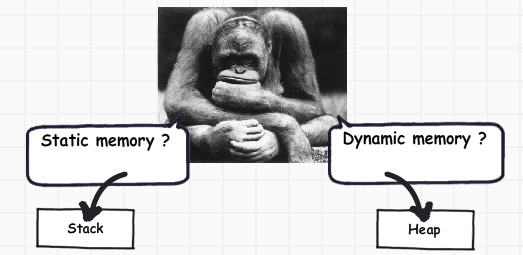
既然我們已經了解了棧和堆的概念了,是時候了解值類型和引用類型的概念了。值類型將數據和內存都保存在同一位置,而一個引用類型則會有一個指向實際內存區域的指針。
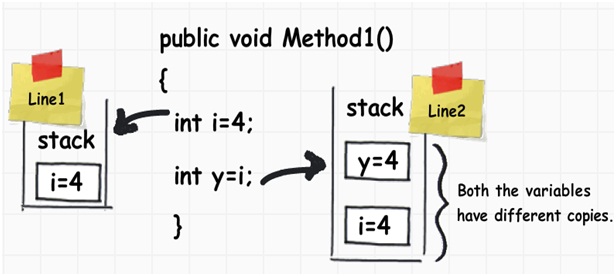
通過下圖,我們可以看到一個名為i的整形數據類型,它的值被賦值到另一個名為j的整形數據類型。他們的值都被存儲到了棧上。
當我們將一個int類型的值賦值到另一個int類型的值時,它實際上是創建了一個完全不同的副本。換句話說,如果你改變了其中某一個的值,另一個不會發生改變。於是,這些種類的數據類型被稱為“值類型”。
當我們創建一個對象並且將此對象賦值給另外一個對象時,他們彼此都指向了如下圖代碼段所示的內存中同一塊區域。因此,當我們將obj賦值給obj1時,他們都指向了堆中的同一塊區域。換句話說,如果此時我們改變了其中任何一個,另一個都會受到影響,這也說明了他們為何被稱為“引用類型”。
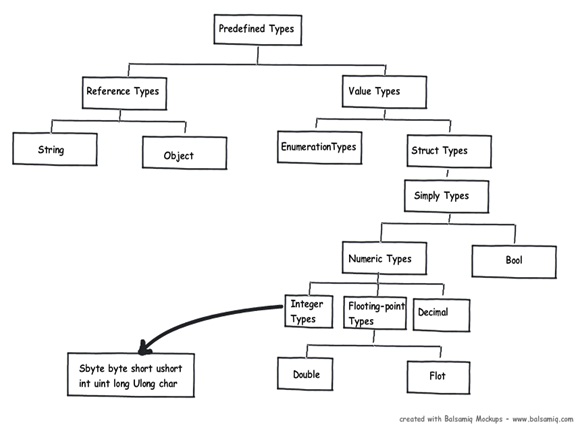
在.NET中,變量是存儲到棧還是堆中完全取決於其所屬的數據類型。比如:‘String’或‘Object’屬於引用類型,而其他.NET基元數據類型則會被分配到棧上。下圖則詳細地展示了在.NET預置類型中,哪些是值類型,哪些又是引用類型。
現在,你已經有了不少的理論基礎了。現在,是時候了解上面的知識在實際編程中的使用了。在應用中最大的一個意義就在於:理解數據從棧移動到堆的過程中所發生的性能消耗問題,反之亦然。
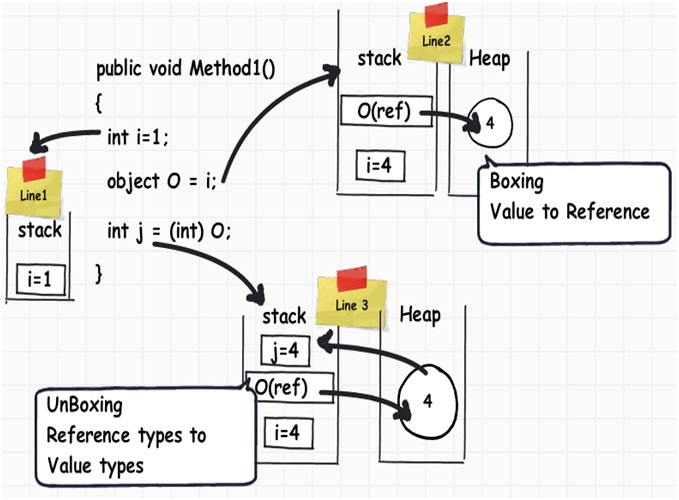
考慮一下以下的代碼片段,當我們將一個值類型轉換為引用類型,數據將會從棧移動到堆中。相反,當我們將一個引用類型轉換為值類型時,數據也會從堆移動到棧中。
不管是在從棧移動到堆還是從堆中移動到棧上都會不可避免地對系統性能產生一些影響。
於是,兩個新名詞橫空出世:當數據從值類型轉換為引用類型的過程被稱為“裝箱”,而從引用類型轉換為值類型的過程則被成為“拆箱”。
如果你編譯一下上面這段代碼並且在ILDASM(一個IL的反編譯工具)中對其進行查看,你會發現在IL代碼中,裝箱和拆箱是什麼樣子的。下圖則展示了示例代碼被編譯後所產生的IL代碼。
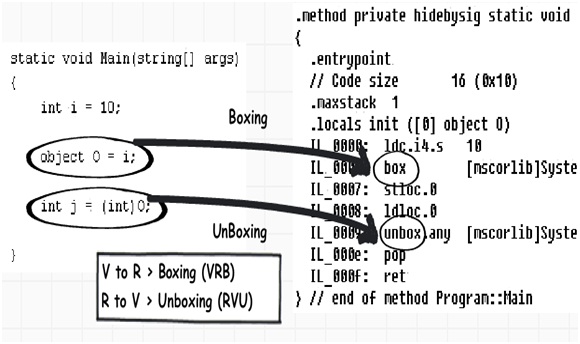
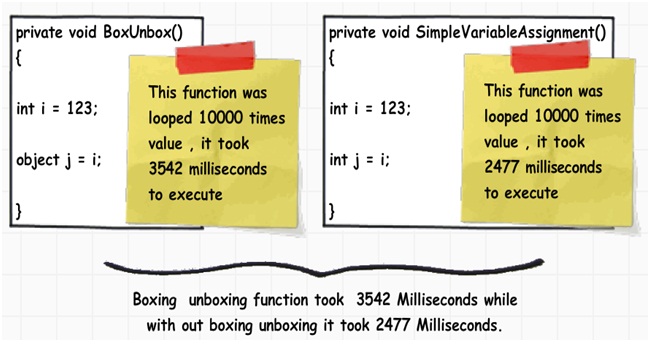
為了弄明白到底裝箱和拆箱會帶來怎樣的性能影響,我們分別循環運行10000次下圖所示的兩個函數方法。其中第一個方法中有裝箱操作,另一個則沒有。我們使用一個Stopwatch對象來監視時間的消耗。
具有裝箱操作的方法花費了3542毫秒來執行完成,而沒有裝箱操作的方法只花費了2477毫秒,整整相差了1秒多。而且,這個值也會因為循環次數的增加而增加。也就是說,我們要盡量避免裝箱和拆箱操作。在一個項目中,如果你需要裝箱和裝箱,請仔細考慮它是否是絕對必不可少的操作,如果不是,那麼盡量不用。
雖然以上代碼段沒有展示拆箱操作,但其效果同樣適用於拆箱。你可以通過寫代碼來實現拆箱,並且通過Stopwatch來測試其時間消耗。
原文出處: Shivprasad koirala