從內部剖析C# 集合之--List<T>,
今天來討論一下C# list<T> 的一些機制,有什麼不對的錯誤的地方請各位即使支出,不甚感激。。
List<T> 簡介
一,List<T> 是非線程安全集合
我在看List<T>源碼時找到SynchronizedList這個類,從這個名字上及從他的代碼實現來看其就是一個線程安全的集合,但是不清楚這個SynchronizedList和List<T> 是如何配合實現線程安全的,或是這個方法只是給FCL類庫使用? 哪位知道的話可以解惑一下。。

![]()
[Serializable()]
internal class SynchronizedList : IList<T>
{
private MyList<T> _list;
private Object _root;
internal SynchronizedList(MyList<T> list)
{
_list = list;
_root = ((System.Collections.ICollection)list).SyncRoot;
}
public int Count
{
get
{
lock (_root)
{
return _list.Count;
}
}
}
public bool IsReadOnly
{
get
{
return ((ICollection<T>)_list).IsReadOnly;
}
}
public void Add(T item)
{
lock (_root)
{
_list.Add(item);
}
}
public void Clear()
{
lock (_root)
{
_list.Clear();
}
}
public bool Contains(T item)
{
lock (_root)
{
return _list.Contains(item);
}
}
public void CopyTo(T[] array, int arrayIndex)
{
lock (_root)
{
_list.CopyTo(array, arrayIndex);
}
}
public bool Remove(T item)
{
lock (_root)
{
return _list.Remove(item);
}
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
lock (_root)
{
return _list.GetEnumerator();
}
}
IEnumerator<T> IEnumerable<T>.GetEnumerator()
{
lock (_root)
{
return ((IEnumerable<T>)_list).GetEnumerator();
}
}
public T this[int index]
{
get
{
lock (_root)
{
return _list[index];
}
}
set
{
lock (_root)
{
_list[index] = value;
}
}
}
public int IndexOf(T item)
{
lock (_root)
{
return _list.IndexOf(item);
}
}
public void Insert(int index, T item)
{
lock (_root)
{
_list.Insert(index, item);
}
}
public void RemoveAt(int index)
{
lock (_root)
{
_list.RemoveAt(index);
}
}
}
View Code
2,List<T>內部數據結構比較簡單,沒有hashtable和Dictionary那樣用到哈希算法,其內部默認的數組長度是4,最大支持長度為2146435071,List<T>沒有類似Hashtable的裝載因子概念,也可以理解為List<T>的裝載因子是1,當執行add方法時,都要判斷當前list容量和已使用的容量是否相等,如果相等則進行擴容,擴容的規則是當前容量的兩倍。
3,list內部添加的元素是順序的,內部有一個_size變量,每次執行add時,_size加一。
二,關於List<T>和Dictionary 的性能比較。
雖然他們之前可比性不是太強,但這裡還是就常用的添加,查找,刪除方法做一個比較。
1) 添加新元素
從理論上來說List<T>的ADD()要比Dictionary快,因為List<T>少了hash計算。從實際試驗上來看也確實這樣。
![]()
static void Main(string[] args)
{
for (int i = 0; i < 10; i++)
{
List<int> myList = new List<int>();
Dictionary<int, int> myDict = new Dictionary<int, int>();
Stopwatch swatch = new Stopwatch();
swatch.Restart();
for (int j = 0; j < 100000; j++)
{
myList.Add(j);
}
swatch.Stop();
Console.WriteLine("myList:" + swatch.ElapsedTicks);
swatch.Restart();
for (int j = 0; j < 100000; j++)
{
myDict.Add(j, j);
}
swatch.Stop();
Console.WriteLine("myDict:" + swatch.ElapsedTicks);
Console.WriteLine("------------------------------");
}
Console.ReadKey();
}
View Code
執行結果:
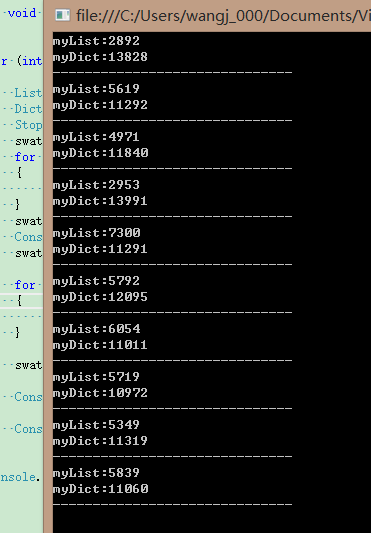
從上圖可知,List<T> 要比Dictionary快一個數量級。
2)查找元素
Dictionary的查找要比list快多了,極端情況下會快幾個數量級,
通過前面的文章我們知道Dictionary是先計算key的hash值,然後通過hash值進行索引定位,而list是先for循環,然後在與傳入的表達式值進行比較,如下代碼:
![]()
public T Find(Predicate<T> match) {
if( match == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.match);
}
Contract.EndContractBlock();
for(int i = 0 ; i < _size; i++) {
if(match(_items[i])) {
return _items[i];
}
}
return default(T);
}
View Code
接下來我們來測試兩種極端情況下的性能比較:
情況一:
![]()
static void Main(string[] args)
{
for (int i = 0; i < 10; i++)
{
List<int> myList = new List<int>();
Dictionary<int, int> myDict = new Dictionary<int, int>();
Stopwatch swatch = new Stopwatch();
for (int j = 0; j < 10000000; j++)
{
myList.Add(j);
}
swatch.Start();
var myListResult = myList.Find(p =>
{
return p == 9999999;
});
swatch.Stop();
Console.WriteLine("myList:" + swatch.ElapsedTicks);
for (int j = 0; j < 10000000; j++)
{
myDict.Add(j, j);
}
swatch = new Stopwatch();
swatch.Start();
var myDictResult = myDict[9999999];
swatch.Stop();
Console.WriteLine("myDict:" + swatch.ElapsedTicks);
Console.WriteLine("------------------------------");
}
Console.ReadKey();
}
View Code
結果: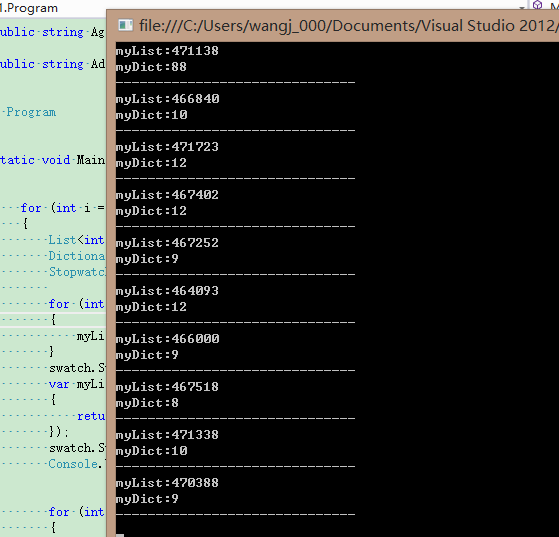
情況二:
![]()
static void Main(string[] args)
{
for (int i = 0; i < 10; i++)
{
List<int> myList = new List<int>();
Dictionary<int, int> myDict = new Dictionary<int, int>();
Stopwatch swatch = new Stopwatch();
for (int j = 0; j < 10000000; j++)
{
myList.Add(j);
}
swatch.Start();
var myListResult = myList.Find(p =>
{
return p == 0;
});
swatch.Stop();
Console.WriteLine("myList:" + swatch.ElapsedTicks);
for (int j = 0; j < 10000000; j++)
{
myDict.Add(j, j);
}
swatch = new Stopwatch();
swatch.Start();
var myDictResult = myDict[0];
swatch.Stop();
Console.WriteLine("myDict:" + swatch.ElapsedTicks);
Console.WriteLine("------------------------------");
}
Console.ReadKey();
}
View Code
結果: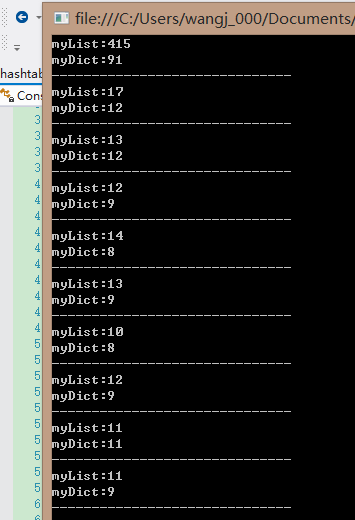
我們看到第二種極端情況下 List<T> 反而比Dictionary快,結合前面的文章,想必各位已經知道的其中的原因,
3)移除元素
List<T>的Remove 方法在移除元素時先計算元素的索引值,然後把索引值傳給RemoveAt方法移除元素。所以通過這個就知道移除元素時也是Dictionary完爆List<T>,其他的不多說了,直接上源碼上圖。
![]()
static void Main(string[] args)
{
for (int i = 0; i < 10; i++)
{
MyList<int> myList = new MyList<int>();
Dictionary<int, int> myDict = new Dictionary<int, int>();
Stopwatch swatch = new Stopwatch();
for (int j = 0; j < 10000000; j++)
{
myList.Add(j);
}
swatch.Start();
myList.Remove(55555);
swatch.Stop();
Console.WriteLine("myList:" + swatch.ElapsedTicks);
for (int j = 0; j < 10000000; j++)
{
myDict.Add(j, j);
}
swatch = new Stopwatch();
swatch.Start();
var myDictResult = myDict.Remove(55555);
swatch.Stop();
Console.WriteLine("myDict:" + swatch.ElapsedTicks);
Console.WriteLine("------------------------------");
}
Console.ReadKey();
}
View Code
運行結果:
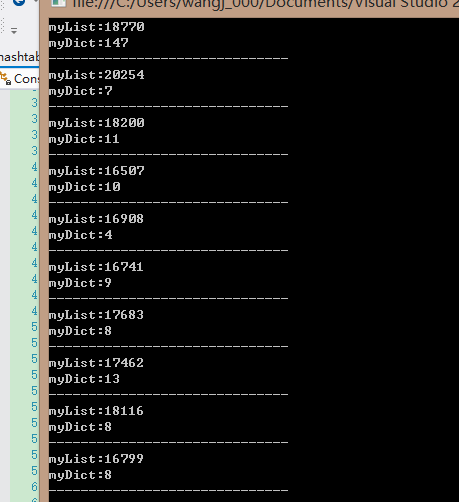
我個人認為導致他們在插入和刪除元素的性能相差如此之大的最根本原因是:Dictionary用到的hash,而List沒有,即使Dictionary的hash計算有一定的性能損耗,但整體性能還是完爆List.
下一節來介紹ArrayList的實現,實際上ArrayList和list可比性更強些。