上一篇文章裡我簡述了使用Keys作為Redis搜索的方式,確實感受到了社區的力量,寫文章好處多。首先謝謝各位前輩的指導,我知道了拿Redis作為搜索是個錯誤的方向。本來這篇文章我覺得確實沒必要發了,但是想想既然錯了,那就將錯就錯,寫出來給初學者一些思考吧。
本篇我將會講講,分詞建立key索引和redis scan命令兩種方式。
注意:這兩種方式的搜索也不一定可行,具體場景要具體測試衡量,拿Redis做搜索要深思熟慮並且測試,甚至是要直接回避的。
另外,上篇評論也建議大家看一看,前輩們給了很多經驗總結,有一些同學可能沒明白。這些點我先整理下:
1. 我采用了StactkExchange.Redis,而不是ServiceStack.Redis。對於後者我覺得是個好工具,但是4.0開始收費了,3.9功能不是特別全,一些地方存在不足。
2. 有同學建議GetAll之類的方式,我覺得對於緩存應該還是不要StringSet(list)\StringGet(list)的方式吧,畢竟數據量大了,序列化反序列化就費時。這點不知道大家怎麼看?我個人覺得每條記錄應該是一個key-value,這個value應該是避免存成整個集合的,否則效率何在?
3. 上一篇中的Keys模糊匹配,請大家在實際運用的時候忽略掉。因為Keys會引發Redis鎖,並且增加Redis的CPU占用,情況是很惡劣的。
這種方式是我實踐過後,結合上篇的前輩給的觀點覺得唯一比較可行且符合redis特性的方式,不過最終效率上還是比不過內存。
詳細的實現思路清看Redis作者博客(參考資料1),這裡的例子還是基於UserName,英文,並且只針對詞組做了長度為3的分詞,其他場景請自行擴展。
首先基於AutoComplete的字母搜索,那麼我們需要對所有的Name做一個分詞,即:
abc => (a, ab, abc)
形成一個Set的集合形式:
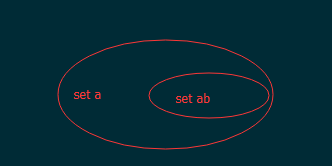
那麼輸入a,我們就直接取set a裡的內容,輸入ab就直接取ab集合的內容。那麼我們開始轉換,首先我們需要對User表的姓名進行分詞:
var redis = ConnectionMultiplexer.Connect("localhost");
var db = redis.GetDatabase();
for (var i = 1; i < 4; i++)
{
var data = dbCon.Lookup<string, int>(string.Format(@"select words, id from (
select Row_number() over (partition by words order by name) as rn,id,words from (
select id, SUBSTRING(name, 1, {0}) as words, name from User
) as t
) t2 where rn <= {1} and words != '' and words is not null", i, 20));
data.ForEach((key, item) =>
{
db.SetAdd("capqueen:Cache:user:" + key.ToLower(), item.Select<int, RedisValue>(j => j).ToArray());
});
}
第一步:采用SQL,分組排序篩選出每個分詞的前20條數據,這裡使用的是OrmLite的語法。
第二部:存入RedisSet,注意這裡其實只是做了一個索引,並不保存具體的User內容,效果如下:
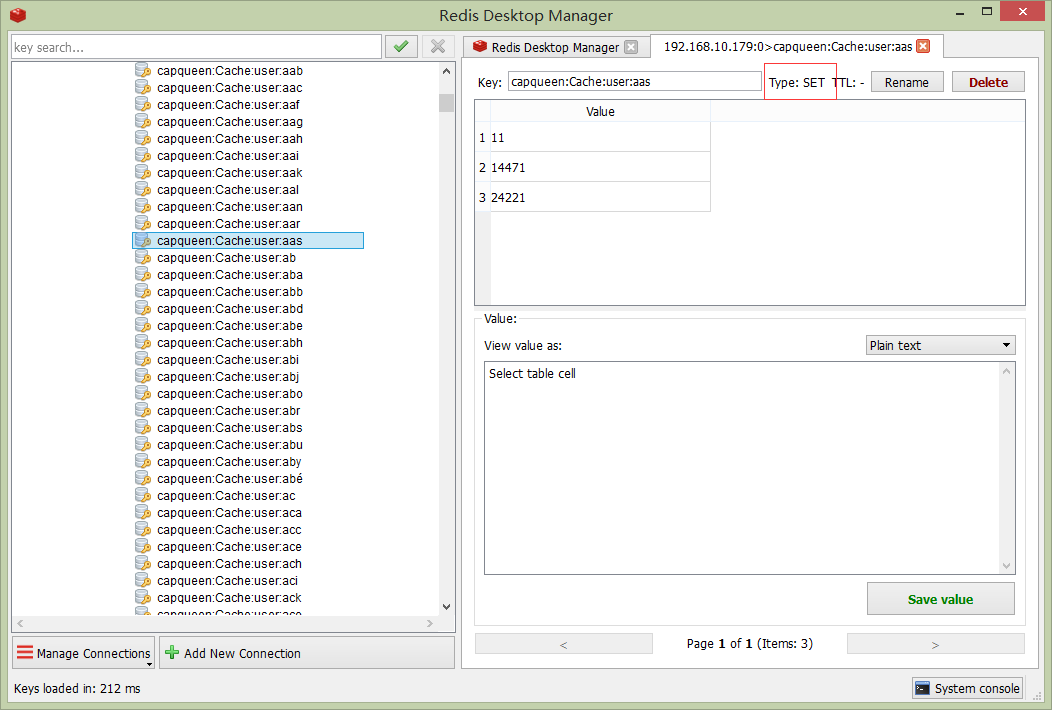
接著搜索的時候我們可以實現如下:
public List<User> SearchWords(string keywords)
{
var redis = ConnectionMultiplexer.Connect("localhost");
var db = redis.GetDatabase();
var result = db.SetMembers("capqueen:Cache:user:" + keywords.ToLower());
var users = new List<User>();
if (result.Any())
{
//轉換成ids
var ids = result.ToList().Select<RedisValue, RedisKey>(i => i.ToString());
//按照keys獲取value ,事先已經存好了Users
var values = db.StringGet(ids.ToArray());
//構造List Json以加速解析
var portsJson = new StringBuilder("[");
values.ToList().ForEach(item =>
{
if (!string.IsNullOrWhiteSpace(item))
{
portsJson.Append(item).Append(",");
}
});
portsJson.Append("]");
users = JsonConvert.DeserializeObject<List<User>>(portsJson.ToString());
}
}
經過實際的測試,這樣的寫法比前面的Keys確實好了不少,但是性能還是差強人意的。
這種方法是我在查閱了Redis的文檔之後,發現的,但是也就是試驗一下,估計也不能用做生產環境大規模查詢。
Scan根據數據結構的不同分為了SCAN\HSCAN\SSCAN\ZSCAN,具體的信息請看文檔。我們這裡采用了ZSCAN:
ZSCAN key cursor [MATCH pattern] [COUNT count]
這裡cursor是搜索的迭代的一個游標,具體還沒弄明白,pattern就是匹配規則 count就是記錄條數
由於我使用的是StackExchange.Redis,它提供的zscan方法是:
IEnumerable SortedSetScan(RedisKey key, RedisValue pattern = null, int pageSize = 10, long cursor = 0, int pageOffset = 0, CommandFlags flags = CommandFlags.None);
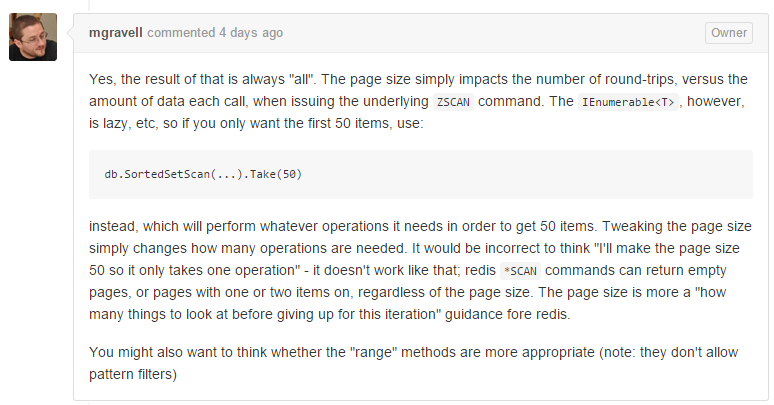
用過之後,我發現了這裡的pageSize/pageOffset貌似沒有效果,為此我還特地上github為作者留了言,他給我一些解釋:
https://github.com/StackExchang, 我的英語比較差,請湊合看。
public void CreateTerminalCache(List<User> users)
{
if (users == null) return;
var db = ConnectionMultiplexer.GetDatabase();
var sourceData = new List<KeyValuePair<RedisKey, RedisValue>>();
//構造集合數據
var list = users.Select(item =>
{
var value = JsonConvert.SerializeObject(item);
//構造原始數據
sourceData.Add(new KeyValuePair<RedisKey, RedisValue>("capqueen:users:" + item.Id, value));
//構造數據
return new SortedSetEntry(item.Name, item.Id);
});
//添加進有序集合,采用name - id
db.SortedSetAdd("capqueen:users:index", list.ToArray());
//添加港口數據key-value
db.StringSet(sourceData.ToArray(), When.Always, CommandFlags.None);
}
然後搜索的時候如下:
public List<User> GetUserByWord(string words)
{
var db = ConnectionMultiplexer.GetDatabase();
//搜索
var result = db.SortedSetScan("capqueen:users:index", words + "*", 10, 1, 30, CommandFlags.None).Take(30).ToList();
var users = new List<User>();
if (result.Any())
{
//轉換成ids
var ids = result.ToList().Select<SortedSetEntry, RedisKey>(i => i.ToString());
//按照keys獲取value
var values = db.StringGet(ids.ToArray());
//構造List Json以加速解析
var portsJson = new StringBuilder("[");
values.ToList().ForEach(item =>
{
if (!string.IsNullOrWhiteSpace(item))
{
portsJson.Append(item).Append(",");
}
});
portsJson.Append("]");
users = JsonConvert.DeserializeObject<List<User>>(portsJson.ToString());
}
return users;
}
總的來說,通過這麼一些列的研究和前輩們的指導,我對Redis有了一些了解。AutoComplete的場景是真的不適合使用Redis,可以說目前Redis用來做一些搜索可能還早,期待以後會有相關功能吧。上一篇文章裡,有些前輩給的 意見很好,希望大家也可以學習一下。