首先通過圖表比較不同排序算法的時間復雜度和穩定性。
排序方法
平均時間
最壞情況
最好情況
輔助空間
穩定性
直接插入排序O(n2)
O(n2)
O(n)
O(1)
是 冒泡排序O(n2)
O(n2)
O(n)
O(1)
是 簡單選擇排序O(n2)
O(n2)
O(n2)
O(1)
是 希爾排序 -O(nlog2n)~O(n2)
O(nlog2n)~O(n2)
O(1)
否 快速排序O(nlog2n)
O(n2)
O(nlog2n)
O(log2n)
否 堆排序O(nlog2n)
O(nlog2n)
O(nlog2n)
O(1)
否 2-路歸並排序O(nlog2n)
O(nlog2n)
O(nlog2n)
O(n)
是 基數排序 O(d(n + rd)) O(d(n + rd)) O(d(n + rd)) O(rd) 是注:1. 算法的時間復雜度一般情況下指最壞情況下的漸近時間復雜度。
2. 排序算法的穩定性會對多關鍵字排序產生影響。
下面通過C#代碼說明不同的排序算法
插入排序
時間復雜度:平均情況—O(n2) 最壞情況—O(n2) 輔助空間:O(1) 穩定性:穩定
插入排序是在一個已經有序的小序列的基礎上,一次插入一個元素。當然,剛開始這個有序的小序列只有1個元素,就是第一個元素。比較是從有序序列的末尾開始,也就是想要插入的元素和已經有序的最大者開始比起,如果比它大則直接插入在其後面,否則一直往前找直到找到它該插入的位置。如果碰見一個和插入元素相等的,那麼插入元素把想插入的元素放在相等元素的後面。所以,相等元素的前後順序沒有改變,從原無序序列出去的順序就是排好序後的順序,所以插入排序是穩定的。
C# 代碼 復制
void InsertSort(SqList &L) {
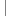
if (LT(L.r[i].key, L.r[i-1].key)) {
}
} // InsertSort
希爾排序(shell)
時間復雜度:理想情況—O(nlog2n) 最壞情況—O(n2) 穩定性:不穩定
希爾排序是按照不同步長對元素進行插入排序,當剛開始元素很無序的時候,步長最大,所以插入排序的元素個數很少,速度很快;當元素基本有序了,步長很小,插入排序對於有序的序列效率很高。所以,希爾排序的時間復雜度會比o(n^2)好一些。由於多次插入排序,我們知道一次插入排序是穩定的,不會改變相同元素的相對順序,但在不同的插入排序過程中,相同的元素可能在各自的插入排序中移動,最後其穩定性就會被打亂,所以shell排序是不穩定的。
冒泡排序
時間復雜度:平均情況—O(n2) 最壞情況—O(n2) 輔助空間:O(1) 穩定性:穩定
冒泡排序就是把小的元素往前調或者把大的元素往後調。比較是相鄰的兩個元素比較,交換也發生在這兩個元素之間。所以,如果兩個元素相等,我想你是不會再無聊地把他們倆交換一下的;如果兩個相等的元素沒有相鄰,那麼即使通過前面的兩兩交換把兩個相鄰起來,這時候也不會交換,所以相同元素的前後順序並沒有改變,所以冒泡排序是一種穩定排序算法。
C# 代碼 復制
快速排序
時間復雜度:平均情況—O(nlog2n) 最壞情況—O(n2) 輔助空間:O(log2n) 穩定性:不穩定
快速排序有兩個方向,左邊的i下標一直往右走,當a[i] <= a[center_index],其中center_index是中樞元素的數組下標,一般取為數組第0個元素。而右邊的j下標一直往左走,當a[j] > a[center_index]。如果i和j都走不動了,i <= j, 交換a[i]和a[j],重復上面的過程,直到i>j。 交換a[j]和a[center_index],完成一趟快速排序。在中樞元素和a[j]交換的時候,很有可能把前面的元素的穩定性打亂,比如序列為 5 3 3 4 3 8 9 10 11, 現在中樞元素5和3(第5個元素,下標從1開始計)交換就會把元素3的穩定性打亂,所以快速排序是一個不穩定的排序算法,不穩定發生在中樞元素和a[j]交換的時刻。
C# 代碼 復制
選擇排序
時間復雜度:平均情況—O(n2) 最壞情況—O(n2) 輔助空間:O(1) 穩定性:不穩定
選擇排序是給每個位置選擇當前元素最小的,比如給第一個位置選擇最小的,在剩余元素裡面給第二個元素選擇第二小的,依次類推,直到第n-1個元素,第n個元素不用選擇了,因為只剩下它一個最大的元素了。那麼,在一趟選擇,如果當前元素比一個元素小,而該小的元素又出現在一個和當前元素相等的元素後面,那麼交換後穩定性就被破壞了。比較拗口,舉個例子,序列5 8 5 2 9, 我們知道第一遍選擇第1個元素5會和2交換,那麼原序列中2個5的相對前後順序就被破壞了,所以選擇排序不是一個穩定的排序算法。
C# 代碼 復制
堆排序
時間復雜度:平均情況—O(nlog2n) 最壞情況—O(nlog2n) 輔助空間:O(1) 穩定性:不穩定
我們知道堆的結構是節點i的孩子為2*i和2*i+1節點,大頂堆要求父節點大於等於其2個子節點,小頂堆要求父節點小於等於其2個子節點。在一個長為n的序列,堆排序的過程是從第n/2開始和其子節點共3個值選擇最大(大頂堆)或者最小(小頂堆),這3個元素之間的選擇當然不會破壞穩定性。但當為n/2-1, n/2-2, ...1這些個父節點選擇元素時,就會破壞穩定性。有可能第n/2個父節點交換把後面一個元素交換過去了,而第n/2-1個父節點把後面一個相同的元素沒有交換,那麼這2個相同的元素之間的穩定性就被破壞了。所以,堆排序不是穩定的排序算法
歸並排序
時間復雜度:平均情況—O(nlog2n) 最壞情況—O(nlog2n) 輔助空間:O(n) 穩定性:穩定
歸並排序是把序列遞歸地分成短序列,遞歸出口是短序列只有1個元素(認為直接有序)或者2個序列(1次比較和交換),然後把各個有序的段序列合並成一個有序的長序列,不斷合並直到原序列全部排好序。可以發現,在1個或2個元素時,1個元素不會交換,2個元素如果大小相等也沒有人故意交換,這不會破壞穩定性。那麼,在短的有序序列合並的過程中,穩定是是否受到破壞?沒有,合並過程中我們可以保證如果兩個當前元素相等時,我們把處在前面的序列的元素保存在結果序列的前面,這樣就保證了穩定性。所以,歸並排序也是穩定的排序算法。
C# 代碼 復制
main()
{
int i,j,temp;
int a[10];
for(i=0;i<10;i++)
scanf ("%d,",&a[i]);
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
for(i=1;i<11;i++)
printf("%5d,",a[i] );
printf("\n");
}
--------------
冒泡算法
冒泡排序的算法分析與改進
交換排序的基本思想是:兩兩比較待排序記錄的關鍵字,發現兩個記錄的次序相反時即進行交換,直到沒有反序的記錄為止。
應用交換排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
將被排序的記錄數組R[1..n]垂直排列,每個記錄R看作是重量為R.key的氣泡。根據輕氣泡不能在重氣泡之下的原則,從下往上掃描數組R:凡掃描到違反本原則的輕氣泡,就使其向上"飄浮"。如此反復進行,直到最後任何兩個氣泡都是輕者在上,重者在下為止。
(1)初始
R[1..n]為無序區。
(2)第一趟掃描
從無序區底部向上依次比較相鄰的兩個氣泡的重量,若發現輕者在下、重者在上,則交換二者的位置。即依次比較(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);對於每對氣泡(R[j+1],R[j]),若R[j+1].key<R[j].key,則交換R[j+1]和R[j]的內容。
第一趟掃描完畢時,"最輕"的氣泡就飄浮到該區間的頂部,即關鍵字最小的記錄被放在最高位置R[1]上。
(3)第二趟掃描
掃描R[2..n]。掃描完畢時,"次輕"的氣泡飄浮到R[2]的位置上……
最後,經過n-1 趟掃描可得到有序區R[1..n]
注意:
第i趟掃描時,R[1..i-1]和R[i..n]分別為當前的有序區和無序區。掃描仍是從無序區底部向上直至該區頂部。掃描完畢時,該區中最輕氣泡飄浮到頂部位置R上,結果是R[1..i]變為新的有序區。
2、冒泡排序過程示例
對關鍵字序列為49 38 65 97 76 13 27 49的文件進行冒泡排序的過程
3、排序算法
(1)分析
因為每一趟排序都使有序區增加了一個氣泡,在經過n-1趟排序之後,有序區中就有n-1個氣泡,而無序區中氣泡的重量總是大於等於有序區中氣泡的重量,所以整個冒泡排序過程至多需要進行n-1趟排序。
若在某一趟排序中未發現氣泡位置的交換,則說明待排序的無序區中所有氣泡均滿足輕者在上,重者在下的原則,因此,冒泡排序過程可在此趟排序後終止。為此,在下面給出的算法中,引入一個布爾量exchange,在每趟排序開始前,先將其置為FALSE。若排序過程中發生了交換,則將其置為TRUE。各趟排序結束時檢查exchange,若未曾發生過交換則終止算法,不再進行下一趟排序。
(2)具體算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上掃描,對R做冒泡排序
int i,j;
Boolean exchange; //交換標志
for(i=1;i&......余下全文>>
main()
{
int i,j,temp;
int a[10];
for(i=0;i<10;i++)
scanf ("%d,",&a[i]);
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
for(i=1;i<11;i++)
printf("%5d,",a[i] );
printf("\n");
}
--------------
冒泡算法
冒泡排序的算法分析與改進
交換排序的基本思想是:兩兩比較待排序記錄的關鍵字,發現兩個記錄的次序相反時即進行交換,直到沒有反序的記錄為止。
應用交換排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
將被排序的記錄數組R[1..n]垂直排列,每個記錄R看作是重量為R.key的氣泡。根據輕氣泡不能在重氣泡之下的原則,從下往上掃描數組R:凡掃描到違反本原則的輕氣泡,就使其向上"飄浮"。如此反復進行,直到最後任何兩個氣泡都是輕者在上,重者在下為止。
(1)初始
R[1..n]為無序區。
(2)第一趟掃描
從無序區底部向上依次比較相鄰的兩個氣泡的重量,若發現輕者在下、重者在上,則交換二者的位置。即依次比較(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);對於每對氣泡(R[j+1],R[j]),若R[j+1].key<R[j].key,則交換R[j+1]和R[j]的內容。
第一趟掃描完畢時,"最輕"的氣泡就飄浮到該區間的頂部,即關鍵字最小的記錄被放在最高位置R[1]上。
(3)第二趟掃描
掃描R[2..n]。掃描完畢時,"次輕"的氣泡飄浮到R[2]的位置上……
最後,經過n-1 趟掃描可得到有序區R[1..n]
注意:
第i趟掃描時,R[1..i-1]和R[i..n]分別為當前的有序區和無序區。掃描仍是從無序區底部向上直至該區頂部。掃描完畢時,該區中最輕氣泡飄浮到頂部位置R上,結果是R[1..i]變為新的有序區。
2、冒泡排序過程示例
對關鍵字序列為49 38 65 97 76 13 27 49的文件進行冒泡排序的過程
3、排序算法
(1)分析
因為每一趟排序都使有序區增加了一個氣泡,在經過n-1趟排序之後,有序區中就有n-1個氣泡,而無序區中氣泡的重量總是大於等於有序區中氣泡的重量,所以整個冒泡排序過程至多需要進行n-1趟排序。
若在某一趟排序中未發現氣泡位置的交換,則說明待排序的無序區中所有氣泡均滿足輕者在上,重者在下的原則,因此,冒泡排序過程可在此趟排序後終止。為此,在下面給出的算法中,引入一個布爾量exchange,在每趟排序開始前,先將其置為FALSE。若排序過程中發生了交換,則將其置為TRUE。各趟排序結束時檢查exchange,若未曾發生過交換則終止算法,不再進行下一趟排序。
(2)具體算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上掃描,對R做冒泡排序
int i,j;
Boolean exchange; //交換標志
for(i=1;i&......余下全文>>