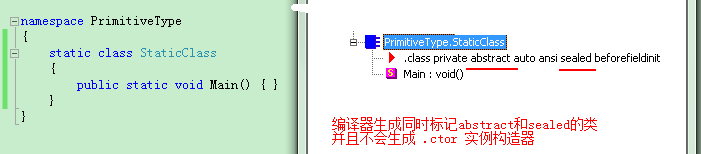
C# 已經提供了我們幾種非常好用的類庫如 BackgroundWorker、Thread、Task等,借助它們,我們就能夠分分鐘編寫出一個多線程的應用程序。
比如這樣一個需求:有一個 Winform 窗體,點擊按鈕後,會將窗體中的數據導出到一個 output.pdf 文件中。原先的代碼沒有采用多線程技術,所以當點擊按鈕後,整個窗體就變成無響應了。為了解決這個問題,可以使用 Task.Run(()=>{...導出文件的代碼});
上面的代碼看似簡單,卻隱藏著種種危機。如果在導出的期間,窗體的數據被修改了,那會怎麼樣?如果多個窗體同時導出到同一個文件,又會怎麼樣?
在看完本系列後,你就會清楚了。
有點了解的朋友都知道線程同步有多種手段,什麼 mutex、moniter、seamphore、event 等等,我把它們歸為三類,對應三種需要線程同步的情景。
當一個資源同時被多個線程訪問時,有可能會造成資源沖突(尤其是在存在多個寫線程的時候)的情景。遇到這種情況,在 C# 中,我們可以使用 Interlocked、lock、Moniter、SpinLock、ReadWriteLockSlim、Mutex 來處理問題。
關於不同方案間的區別,請猛擊這裡。
什麼情況下會被認為是情景一?
當你設計的類中出現靜態變量、IO操作時,就會遇到情景一。因為這些資源是由多個對象共享的,不同的線程很同時去訪問這些資源時,就可能會出現爭用。
當一個類被設計成單例,且包含實例變量時,也會遇到情景一。因為實例變量屬於這個單例,當多個線程操縱此單例時,該變量可能會被爭用。
當一個類中的方法調用線程操作某個實例變量時,也會遇到情景一。
情景一強調的是一對多的情形,而在情景二中,資源的數量並不唯一。相比於情景一,情景二側重的是數量上的限制。而用於實現這一需求的類有:Semaphore、SemaphoreSlim。
關於不同方案間的區別,請猛擊這裡。
什麼情況下會被認為是情景二?
當所操作的公共資源存在並發數限制的時候(如數據庫連接、IIS連接數限制等),就被認為是情景二。
情景三關注的是線程執行過程中的先後順序,而用於保證這種先後順序的方式就是通過線程通信的方式:ManualResetEventSlim、ManualResetEvent、AutoResetEvent。
關於不同方案間的區別,請猛擊這裡。
什麼情況下會被認為是情景三?
當兩個線程所處理的事情有先後的依賴時,比如線程二的執行過程依賴線程一的執行結果,那就認為是情景三。
上面的各種方案並不是絕對只限於某一場景,比如 AutoResetEvent 即可以用於情景三,也可以用於情景一。但是,殺雞焉用牛刀,雖然使用 AutoResetEvent 能夠實現情景一的需求,但是用不了 AutoResetEvent 的線程通信能力,同時又會有一些額外的限制(每個線程必須保證 wait 和 set 的成對使用,否則一個線程在鎖定資源後就可能被另一個線程解鎖)。
lock (m)
{
//....
}
//等價於如下方式
autoResetEvent.WaitOne();
//....
autoResetEvent.Set();
也有朋友說,可以用情景一中的 lock 方案來實現情景三的需求。
AutoResetEvent autoReset = new AutoResetEvent(false);
private void button1_Click(object sender, EventArgs e)
{
Task.Run(() =>
{
autoReset.WaitOne();
Console.WriteLine("步驟二");
});
Thread.Sleep(1000);//故意延遲從而保證第二個線程是在第一個線程之後才執行
Task.Run(() =>
{
Console.WriteLine("步驟一");
autoReset.Set();
});
}
上面這個例子最終輸出的結果可想而知。此實例說明,不管線程實際的執行順序如何,AutoResetEvent 都能很容易的保證兩個線程的執行順序。
如果用 lock 呢?
private void button1_Click(object sender, EventArgs e)
{
Task.Run(() =>
{
lock (s)
{
Console.WriteLine("步驟一");
}
});
Thread.Sleep(1000);//必須人為確保步驟二的線程要在步驟一的線程之後執行
Task.Run(() =>
{
lock (s)
{
Console.WriteLine("步驟二");
}
});
}
雖然能實現,但是需要花費額外的代碼去人為保證兩個線程的執行順序。
如何在這麼多方案中確定最終所使用的,需要你能對項目的各種情景進行分析,根據實際情景選擇對應的方案,而不至於大材小用。
通過本系列文章的介紹,希望讓大家能對多線程中可能碰到的情景有一個概念,不至於在面臨多線程的時候手忙腳亂。
本文來自《C# 基礎回顧: 線程同步的三類情景》
main()
{
int i,j,temp;
int a[10];
for(i=0;i<10;i++)
scanf ("%d,",&a[i]);
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
for(i=1;i<11;i++)
printf("%5d,",a[i] );
printf("\n");
}
--------------
冒泡算法
冒泡排序的算法分析與改進
交換排序的基本思想是:兩兩比較待排序記錄的關鍵字,發現兩個記錄的次序相反時即進行交換,直到沒有反序的記錄為止。
應用交換排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
將被排序的記錄數組R[1..n]垂直排列,每個記錄R看作是重量為R.key的氣泡。根據輕氣泡不能在重氣泡之下的原則,從下往上掃描數組R:凡掃描到違反本原則的輕氣泡,就使其向上"飄浮"。如此反復進行,直到最後任何兩個氣泡都是輕者在上,重者在下為止。
(1)初始
R[1..n]為無序區。
(2)第一趟掃描
從無序區底部向上依次比較相鄰的兩個氣泡的重量,若發現輕者在下、重者在上,則交換二者的位置。即依次比較(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);對於每對氣泡(R[j+1],R[j]),若R[j+1].key<R[j].key,則交換R[j+1]和R[j]的內容。
第一趟掃描完畢時,"最輕"的氣泡就飄浮到該區間的頂部,即關鍵字最小的記錄被放在最高位置R[1]上。
(3)第二趟掃描
掃描R[2..n]。掃描完畢時,"次輕"的氣泡飄浮到R[2]的位置上……
最後,經過n-1 趟掃描可得到有序區R[1..n]
注意:
第i趟掃描時,R[1..i-1]和R[i..n]分別為當前的有序區和無序區。掃描仍是從無序區底部向上直至該區頂部。掃描完畢時,該區中最輕氣泡飄浮到頂部位置R上,結果是R[1..i]變為新的有序區。
2、冒泡排序過程示例
對關鍵字序列為49 38 65 97 76 13 27 49的文件進行冒泡排序的過程
3、排序算法
(1)分析
因為每一趟排序都使有序區增加了一個氣泡,在經過n-1趟排序之後,有序區中就有n-1個氣泡,而無序區中氣泡的重量總是大於等於有序區中氣泡的重量,所以整個冒泡排序過程至多需要進行n-1趟排序。
若在某一趟排序中未發現氣泡位置的交換,則說明待排序的無序區中所有氣泡均滿足輕者在上,重者在下的原則,因此,冒泡排序過程可在此趟排序後終止。為此,在下面給出的算法中,引入一個布爾量exchange,在每趟排序開始前,先將其置為FALSE。若排序過程中發生了交換,則將其置為TRUE。各趟排序結束時檢查exchange,若未曾發生過交換則終止算法,不再進行下一趟排序。
(2)具體算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上掃描,對R做冒泡排序
int i,j;
Boolean exchange; //交換標志
for(i=1;i&......余下全文>>
main()
{
int i,j,temp;
int a[10];
for(i=0;i<10;i++)
scanf ("%d,",&a[i]);
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
for(i=1;i<11;i++)
printf("%5d,",a[i] );
printf("\n");
}
--------------
冒泡算法
冒泡排序的算法分析與改進
交換排序的基本思想是:兩兩比較待排序記錄的關鍵字,發現兩個記錄的次序相反時即進行交換,直到沒有反序的記錄為止。
應用交換排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
將被排序的記錄數組R[1..n]垂直排列,每個記錄R看作是重量為R.key的氣泡。根據輕氣泡不能在重氣泡之下的原則,從下往上掃描數組R:凡掃描到違反本原則的輕氣泡,就使其向上"飄浮"。如此反復進行,直到最後任何兩個氣泡都是輕者在上,重者在下為止。
(1)初始
R[1..n]為無序區。
(2)第一趟掃描
從無序區底部向上依次比較相鄰的兩個氣泡的重量,若發現輕者在下、重者在上,則交換二者的位置。即依次比較(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);對於每對氣泡(R[j+1],R[j]),若R[j+1].key<R[j].key,則交換R[j+1]和R[j]的內容。
第一趟掃描完畢時,"最輕"的氣泡就飄浮到該區間的頂部,即關鍵字最小的記錄被放在最高位置R[1]上。
(3)第二趟掃描
掃描R[2..n]。掃描完畢時,"次輕"的氣泡飄浮到R[2]的位置上……
最後,經過n-1 趟掃描可得到有序區R[1..n]
注意:
第i趟掃描時,R[1..i-1]和R[i..n]分別為當前的有序區和無序區。掃描仍是從無序區底部向上直至該區頂部。掃描完畢時,該區中最輕氣泡飄浮到頂部位置R上,結果是R[1..i]變為新的有序區。
2、冒泡排序過程示例
對關鍵字序列為49 38 65 97 76 13 27 49的文件進行冒泡排序的過程
3、排序算法
(1)分析
因為每一趟排序都使有序區增加了一個氣泡,在經過n-1趟排序之後,有序區中就有n-1個氣泡,而無序區中氣泡的重量總是大於等於有序區中氣泡的重量,所以整個冒泡排序過程至多需要進行n-1趟排序。
若在某一趟排序中未發現氣泡位置的交換,則說明待排序的無序區中所有氣泡均滿足輕者在上,重者在下的原則,因此,冒泡排序過程可在此趟排序後終止。為此,在下面給出的算法中,引入一個布爾量exchange,在每趟排序開始前,先將其置為FALSE。若排序過程中發生了交換,則將其置為TRUE。各趟排序結束時檢查exchange,若未曾發生過交換則終止算法,不再進行下一趟排序。
(2)具體算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上掃描,對R做冒泡排序
int i,j;
Boolean exchange; //交換標志
for(i=1;i&......余下全文>>