背景
通過LINQ可以方便的查詢並處理不同的數據源,使用Parallel LINQ (PLINQ)來充分獲得並行化所帶來的優勢。
PLINQ不僅實現了完整的LINQ操作符,而且還添加了一些用於執行並行的操作符,與對應的LINQ相比,通過PLINQ可以獲得明顯的加速,但是具體的加速效果還要取決於具體的場景,不過在並行化的情況下一段會加速。
如果一個查詢涉及到大量的計算和內存密集型操作,而且順序並不重要,那麼加速會非常明顯,然而,如果順序很重要,那麼加速就會受到影響。
AsParallel() 啟用查詢的並行化
下面貼代碼,看下效果,詳情見注釋:

class MRESDemo
{
/*code:釋迦苦僧*/
static void Main()
{
ConcurrentQueue<string> products = new ConcurrentQueue<string>();
products.Enqueue("E");
products.Enqueue("F");
products.Enqueue("B");
products.Enqueue("G");
products.Enqueue("A");
products.Enqueue("C");
products.Enqueue("SS");
products.Enqueue("D");
/*不采用並行化 其數據輸出結果 不做任何處理 */
var productListLinq = from product in products
where (product.Length == 1)
select product;
string appendStr = string.Empty;
foreach (string str in productListLinq)
{
appendStr += str + " ";
}
Console.WriteLine("不采用並行化 輸出:{0}", appendStr);
/*不采用任何排序策略 其數據輸出結果 是直接將分區數據結果合並起來 不做任何處理 */
var productListPLinq = from product in products.AsParallel()
where (product.Length == 1)
select product;
appendStr = string.Empty;
foreach (string str in productListPLinq)
{
appendStr += str + " ";
}
Console.WriteLine("不采用AsOrdered 輸出:{0}", appendStr);
/*采用 AsOrdered 排序策略 其數據輸出結果 是直接將分區數據結果合並起來 並按原始數據順序排序*/
var productListPLinq1 = from product in products.AsParallel().AsOrdered()
where (product.Length == 1)
select product;
appendStr = string.Empty;
foreach (string str in productListPLinq1)
{
appendStr += str + " ";
}
Console.WriteLine("采用AsOrdered 輸出:{0}", appendStr);
/*采用 orderby 排序策略 其數據輸出結果 是直接將分區數據結果合並起來 並按orderby要求進行排序*/
var productListPLinq2 = from product in products.AsParallel()
where (product.Length == 1)
orderby product
select product;
appendStr = string.Empty;
foreach (string str in productListPLinq2)
{
appendStr += str + " ";
}
Console.WriteLine("采用orderby 輸出:{0}", appendStr);
Console.ReadLine();
}
}
View Code
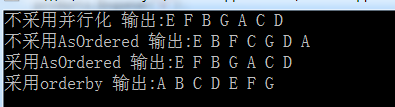
在PLINQ查詢中,AsOrdered()和orderby子句都會降低運行速度,所以如果順序並不是必須的,那麼在請求特定順序的結果之前,將加速效果與串行執行的性能進行比較是非常重要的。
指定執行模式 WithExecutionMode
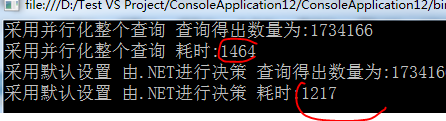
對串行化代碼進行並行化,會帶來一定的額外開銷,Plinq查詢執行並行化也是如此,在默認情況下,執行PLINQ查詢的時候,.NET機制會盡量避免高開銷的並行化算法,這些算法有可能會將執行的性能降低到地獄串行執行的性能。
.NET會根據查詢的形態做出決策,並不開了數據集大小和委托執行的時間,不過也可以強制並行執行,而不用考慮執行引擎分析的結果,可以調用WithExecutionMode方法來進行設置。、
下面貼代碼,方便大家理解
通過PLINQ執行歸約操作
PLINQ可以簡化對一個序列或者一個組中所有成員應用一個函數的過程,這個過程稱之為歸約操作,如在PLINQ查詢中使用類似於Average,Max,Min,Sum之類的聚合函數就可以充分利用並行所帶來好處。
並行執行的規約和串行執行的規約的執行結果可能會不同,因為在操作不能同時滿足可交換和可傳遞的情況下產生攝入,在每次執行的時候,序列或組中的元素在不同並行任務中分布可能也會有區別,因而在這種操作的情況下可能會產生不同的最終結果,因此,一定要通過對於的串行版本來興義原始的數據源,這樣才能幫助PLINQ獲得最優的執行結果。
下面貼代碼:
如上述代碼所示
在LINQ版本中,該方法會返回一個 IEumerable<int>,即調用 Eumerable.Range方法生成指定范圍整數序列的結果,
在PLINQ版本中,該方法會返回一個 ParallelQuery<int>,即調用並行版本中System.Linq.ParallelEumerable的ParallelEumerable.Range方法,通過這種方法得到的結果序列也是並行序列,可以再PLINQ中並行運行。
如果想對特定數據源進行LINQ查詢時,可以定義為 private IEquatable<int> products
如果想對特定數據源進行PLINQ查詢時,可以定義為 private ParallelQuery<int> products
並發PLINQ任務
如代碼所示tk1,tk2,tk3三個任務,tk2,tk3任務的運行需要基於tk1任務的結果,因此,參數中指定了TaskContinuationOptions.OnlyOnRanToCompletion,通過這種方式,每個被串聯的任務都會等待之前的任務完成之後才開始執行,tk2,tk3在tk1執行完成後,這兩個任務的PLINQ查詢可以並行運行,並將會可能地使用多個邏輯內核。
class MRESDemo
{
/*code:釋迦苦僧*/
static void Main()
{
ConcurrentQueue<Product> products = new ConcurrentQueue<Product>();
/*向集合中添加多條數據*/
Parallel.For(0, 600000, (num) =>
{
products.Enqueue(new Product() { Category = "Category" + num, Name = "Name" + num, SellPrice = num });
});
CancellationTokenSource cts = new CancellationTokenSource();
CancellationToken token = cts.Token;
/*創建tk1 任務 查詢 符合 條件的數據*/
Task<ParallelQuery<Product>> tk1 = new Task<ParallelQuery<Product>>((ct) =>
{
var result = products.AsParallel();
try
{
Console.WriteLine("開始執行 tk1 任務", products.Count);
Console.WriteLine("tk1 任務中 數據結果集數量為:{0}", products.Count);
result = products.AsParallel().WithCancellation(token).Where(p => p.Name.Contains("1") && p.Name.Contains("2"));
}
catch (AggregateException ex)
{
foreach (Exception e in ex.InnerExceptions)
{
Console.WriteLine("tk3 錯誤:{0}", e.Message);
}
}
return result;
}, cts.Token);
/*創建tk2 任務,在執行tk1任務完成 基於tk1的結果查詢 符合 條件的數據*/
Task<ParallelQuery<Product>> tk2 = tk1.ContinueWith<ParallelQuery<Product>>((tk) =>
{
var result = tk.Result;
try
{
Console.WriteLine("開始執行 tk2 任務", products.Count);
Console.WriteLine("tk2 任務中 數據結果集數量為:{0}", tk.Result.Count());
result = tk.Result.WithCancellation(token).Where(p => p.Category.Contains("1") && p.Category.Contains("2"));
}
catch (AggregateException ex)
{
foreach (Exception e in ex.InnerExceptions)
{
Console.WriteLine("tk3 錯誤:{0}", e.Message);
}
}
return result;
}, TaskContinuationOptions.OnlyOnRanToCompletion);
/*創建tk3 任務,在執行tk1任務完成 基於tk1的結果查詢 符合 條件的數據*/
Task<ParallelQuery<Product>> tk3 = tk1.ContinueWith<ParallelQuery<Product>>((tk) =>
{
var result = tk.Result;
try
{
Console.WriteLine("開始執行 tk3 任務", products.Count);
Console.WriteLine("tk3 任務中 數據結果集數量為:{0}", tk.Result.Count());
result = tk.Result.WithCancellation(token).Where(p => p.SellPrice > 1111 && p.SellPrice < 222222);
}
catch (AggregateException ex)
{
foreach (Exception e in ex.InnerExceptions)
{
Console.WriteLine("tk3 錯誤:{0}", e.Message);
}
}
return result;
}, TaskContinuationOptions.OnlyOnRanToCompletion);
tk1.Start();
try
{
Thread.Sleep(10);
cts.Cancel();//取消任務
Task.WaitAll(tk1, tk2, tk3);
Console.WriteLine("tk2任務結果輸出,篩選後記錄總數為:{0}", tk2.Result.Count());
Console.WriteLine("tk3任務結果輸出,篩選後記錄總數為:{0}", tk3.Result.Count());
}
catch (AggregateException ex)
{
foreach (Exception e in ex.InnerExceptions)
{
Console.WriteLine("錯誤:{0}", e.Message);
}
}
tk1.Dispose();
tk2.Dispose();
tk3.Dispose();
cts.Dispose();
Console.ReadLine();
}
}
class Product
{
public string Name { get; set; }
public string Category { get; set; }
public int SellPrice { get; set; }
}
View Code
/*tk1任務 采用所有可用處理器*/
result = products.AsParallel().WithCancellation(token).WithDegreeOfParallelism(Environment.ProcessorCount).Where(p => p.Name.Contains("1") && p.Name.Contains("2") && p.Category.Contains("1") && p.Category.Contains("2"));
/*tk1任務 采用1個可用處理器*/
result = products.AsParallel().WithCancellation(token).WithDegreeOfParallelism(1).Where(p => p.Name.Contains("1") && p.Name.Contains("2") && p.Category.Contains("1") && p.Category.Contains("2"));
View Code
好處:如果計算機有8個可用的邏輯內核,PLINQ查詢最多運行4個並發任務,這樣可用使用Parallel.Invoke 加載多個帶有不同並行度的PLINQ查詢,有一些PLINQ查詢的可擴展性有限,因此這些選項可用讓您充分利用額外的內核。
使用ForAll 並行遍歷結果
下面貼代碼:
ForAll是並行,foreach是串行,如果需要以特定的順序處理數據,那麼必須使用上述串行循環或方法。
WithMergeOptions
通過WithMergeOptions擴展方法提示PLINQ應該優先使用哪種方式合並並行結果片段,如下:
class MRESDemo
{
/*code:釋迦苦僧*/
static void Main()
{
Console.WriteLine("當前計算機處理器數:{0}", Environment.ProcessorCount);
ConcurrentQueue<Product> products = new ConcurrentQueue<Product>();
/*向集合中添加多條數據*/
Parallel.For(0, 600000, (num) =>
{
products.Enqueue(new Product() { Category = "Category" + num, Name = "Name" + num, SellPrice = num });
});
Stopwatch sw = new Stopwatch();
Thread.Sleep(1000);
sw.Restart();
int count = 0;
Task tk1 = Task.Factory.StartNew(() =>
{
var result = products.AsParallel().WithMergeOptions(ParallelMergeOptions.AutoBuffered).Where(p => p.Name.Contains("1") && p.Name.Contains("2") && p.Category.Contains("1") && p.Category.Contains("2"));
count = result.Count();
});
Task.WaitAll(tk1);
sw.Stop();
Console.WriteLine("ParallelMergeOptions.AutoBuffered 耗時:{0},數量:{1}", sw.ElapsedMilliseconds, count);
sw.Restart();
int count1 = 0;
Task tk2 = Task.Factory.StartNew(() =>
{
var result = products.AsParallel().WithMergeOptions(ParallelMergeOptions.Default).Where(p => p.Name.Contains("1") && p.Name.Contains("2") && p.Category.Contains("1") && p.Category.Contains("2"));
count1 = result.Count();
});
Task.WaitAll(tk2);
sw.Stop();
Console.WriteLine("ParallelMergeOptions.Default 耗時:{0},數量:{1}", sw.ElapsedMilliseconds, count1);
sw.Restart();
int count2 = 0;
Task tk3 = Task.Factory.StartNew(() =>
{
var result = products.AsParallel().WithMergeOptions(ParallelMergeOptions.FullyBuffered).Where(p => p.Name.Contains("1") && p.Name.Contains("2") && p.Category.Contains("1") && p.Category.Contains("2"));
count2 = result.Count();
});
Task.WaitAll(tk3);
sw.Stop();
Console.WriteLine("ParallelMergeOptions.FullyBuffered 耗時:{0},數量:{1}", sw.ElapsedMilliseconds, count2);
sw.Restart();
int count3 = 0;
Task tk4 = Task.Factory.StartNew(() =>
{
var result = products.AsParallel().WithMergeOptions(ParallelMergeOptions.NotBuffered).Where(p => p.Name.Contains("1") && p.Name.Contains("2") && p.Category.Contains("1") && p.Category.Contains("2"));
count3 = result.Count();
});
Task.WaitAll(tk4);
sw.Stop();
Console.WriteLine("ParallelMergeOptions.NotBuffered 耗時:{0},數量:{1}", sw.ElapsedMilliseconds, count3);
tk4.Dispose();
tk3.Dispose();
tk2.Dispose();
tk1.Dispose();
Console.ReadLine();
}
}
class Product
{
public string Name { get; set; }
public string Category { get; set; }
public int SellPrice { get; set; }
}
View Code
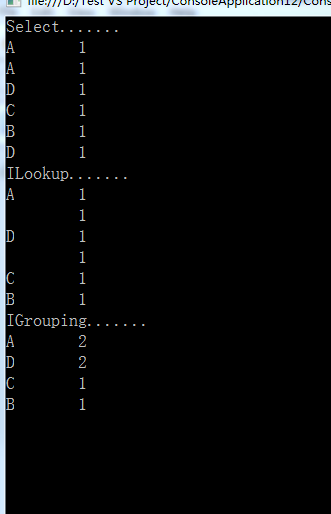
法 ILookup IGrouping
mapreduce ,也稱為Map/reduce 或者Map&Reduce ,是一種非常流行的框架,能夠充分利用並行化處理巨大的數據集,MapReduce的基本思想非常簡單:將數據處理問題分解為以下兩個獨立且可以並行執行的操作:
映射(Map)-對數據源進行操作,為每一個數據項計算出一個鍵值對。運行的結果是一個鍵值對的集合,根據鍵進行分組。
規約(Reduce)-對映射操作產生的根據鍵進行分組的所有鍵值對進行操作,對每一個組執行歸約操作,這個操作可以返回一個或多個值。
下面貼代碼,方便大家理解,但是該案列所展示的並不是一個純粹的MapReduce算法實現:
關於PLINQ:聲明式數據並行就寫到這,主要是PLINQ下的查詢注意項和查詢調優的一些擴展方法。如有問題,歡迎指正。
作者:釋迦苦僧 出處:http://www.cnblogs.com/woxpp/p/3951096.html 本文版權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接。
&可以作為“按位與”或是“取地址”運算符
下面是作為兩種用法的介紹:
1. 按位與運算 按位與運算符"&"是雙目運算符。其功能是參與運算的兩數各對應的二進位相與。只有對應的兩個二進位均為1時,結果位才為1 ,否則為0。參與運算的數以補碼方式出現。
例如:9&5可寫算式如下: 00001001 (9的二進制補碼)&00000101 (5的二進制補碼) 00000001 (1的二進制補碼)可見9&5=1。
按位與運算通常用來對某些位清0或保留某些位。例如把a 的高八位清 0 , 保留低八位, 可作 a&255 運算 ( 255 的二進制數為0000000011111111)。
2.取地址
&作為一元運算符,結果是右操作對象的地址。
例如&x返回x的地址。
地址本身是一個抽象的概念,用於表示對象在存儲器中的邏輯位置
&可以作為“按位與”或是“取地址”運算符
下面是作為兩種用法的介紹:
1. 按位與運算 按位與運算符"&"是雙目運算符。其功能是參與運算的兩數各對應的二進位相與。只有對應的兩個二進位均為1時,結果位才為1 ,否則為0。參與運算的數以補碼方式出現。
例如:9&5可寫算式如下: 00001001 (9的二進制補碼)&00000101 (5的二進制補碼) 00000001 (1的二進制補碼)可見9&5=1。
按位與運算通常用來對某些位清0或保留某些位。例如把a 的高八位清 0 , 保留低八位, 可作 a&255 運算 ( 255 的二進制數為0000000011111111)。
2.取地址
&作為一元運算符,結果是右操作對象的地址。
例如&x返回x的地址。
地址本身是一個抽象的概念,用於表示對象在存儲器中的邏輯位置