在分析同事開發的客戶端搜索項目時注意到,搜索的關鍵是索引,而提到索引就不得不提Lucene.net,思路就是將需要搜索內容寫入索引,客戶端自己或局域網其他機器搜索時直接搜索索引,從而查看到你共享的信息。
初探Lucene.net時關注了幾個關鍵類:
a):IndexReader 索引讀取。
b):IndexWriter 創建索引。
c):StandardAnalyzer 分詞解析,這個應用就比較多了,他解析英文和中文時會拆成單個的字母或者漢字,如果使用PanGuAnalyzer【盤古分析解析】則是拆分成詞組搜索。
d):IndexSearcher 索引搜索。
1、寫入內容時的索引文件
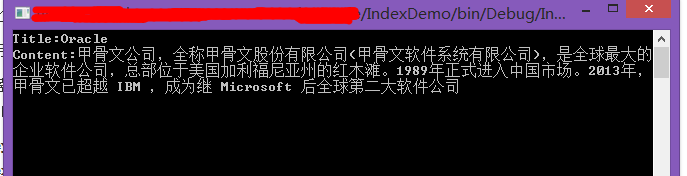
2、輸入關鍵字之後搜索效果
static void Main(string[] args)
{
//CreateIndex("Oracle", "甲骨文公司,全稱甲骨文股份有限公司(甲骨文軟件系統有限公司),是全球最大的企業軟件公司,總部位於美國加利福尼亞州的紅木灘。1989年正式進入中國市場。2013年,甲骨文已超越 IBM ,成為繼 Microsoft 後全球第二大軟件公司");
ReadIndex("oracle 公司 IBM");
Console.ReadKey();
}
private static void CreateIndex(string title,string content)
{
string indexpath = AppDomain.CurrentDomain.BaseDirectory + "IndexData";
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexpath), new NativeFSLockFactory());
bool isExist = IndexReader.IndexExists(directory); //判斷該索引是否存在
if (isExist)
{
if (IndexWriter.IsLocked(directory)) //寫入索引時需要解鎖
{
IndexWriter.Unlock(directory);
}
}
IndexWriter indexWriter=new IndexWriter(directory,new StandardAnalyzer(),!isExist,IndexWriter.MaxFieldLength.UNLIMITED);
Document document =new Document();
Field f1 =new Field("title",title,Field.Store.YES,Field.Index.TOKENIZED);
Field f2 = new Field("content", content, Field.Store.YES, Field.Index.TOKENIZED);
document.Add(f1);
document.Add(f2);
indexWriter.AddDocument(document);
indexWriter.Optimize();
indexWriter.Close();
}
private static void ReadIndex(string keywords)
{
string indexpath = AppDomain.CurrentDomain.BaseDirectory + "IndexData";
string title = "";
string content = "";
StandardAnalyzer analyzer=new StandardAnalyzer(); //分詞
IndexSearcher searcher=new IndexSearcher(indexpath); //索引搜索 -- 傳入索引文件路徑
//MultiFieldQueryParser多字段搜索,一次可以傳入多個需要解析的內容,
//如果需要一次傳入一個就使用QueryParse
MultiFieldQueryParser parser =new MultiFieldQueryParser(new string[]{"title","content"},analyzer );
Query query = parser.Parse(keywords);//轉化為Lucene內部使用的查詢對象
Hits hits = searcher.Search(query); //執行搜索
for (int i=0; i<hits.Length(); i++)
{
Document doc = hits.Doc(i);
title += doc.Get("title");
content += doc.Get("content");
}
searcher.Close();
Console.WriteLine("Title:"+title);
Console.WriteLine("Content:" + content);
}
}
lucene.net 提高索引 多文件夾搜索 只掉去該文件夾內的搜索結果
////根據文檔設置權重
//Random rd = new Random();
//int i = rd.Next(10);
//doc.SetBoost(i);
////根據字段設置權重數據
//Field d = new Field("sort", myred["sort"].ToString(), Field.Store.YES, Field.Index.TOKENIZED);
//d.SetBoost(9F);//特注:參數float小數
----------------------------------------------------------------------
就是以上注釋的啊,原來他們采用的隨機權重,沒有業務邏輯,你可以根據你的要求去添加權重,比如判斷連接是否來自 新浪、搜狐、百度,這些適當權重設置高一些。 或者根據你數據庫存儲的url外鏈來控制一個url的權重,設置其內容的重要性(rank 值),這樣可以保證一部分體驗好的內容排在前面,更多的算法還要靠你自己去思考,你需要的是什麼