幾乎所有編程語言中都提供了"生成一個隨機數"的方法,也就是調用這個方法會生成一個數,我們事先也不知道它生成什麼數。比如在.Net中編寫下面的代碼:
Random rand = newRandom(); Console.WriteLine(rand.Next());
運行後結果如下:

Next()方法用來返回一個隨機數。同樣的代碼你執行和我的結果很可能不一樣,而且我多次運行的結果也很可能不一樣,這就是隨機數。
一、陷阱
看似很簡單的東西,使用的時候有陷阱。我編寫下面的代碼想生成100個隨機數:
for(int i=0;i<100;i++)
{
Random rand = new Random();
Console.WriteLine(rand.Next());
}
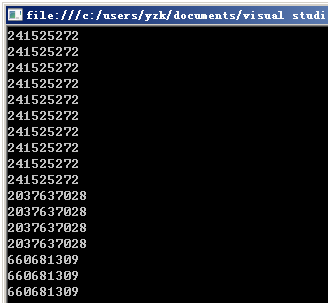
太奇怪了,竟然生成的"隨機數"有好多連續一樣的,這算什麼"隨機數"呀。有人指點"把new Random()"放到for循環外面就可以了:
Random rand = newRandom();
for(int i=0;i<100;i++)
{
Console.WriteLine(rand.Next());
}
運行結果:
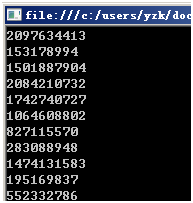
確實可以了!
二、這是為什麼呢?
這要從計算機中"隨機數"產生的原理說起了。我們知道,計算機是很嚴格的,在確定的輸入條件下,產生的結果是唯一確定的,不會每次執行的結果不一樣。那麼怎麼樣用軟件實現產生看似不確定的隨機數呢?
生成隨機數的算法有很多種,最簡單也是最常用的就是 "線性同余法": 第n+1個數=(第n個數*29+37) % 1000,其中%是"求余數"運算符。很多像我一樣的人見了公式都頭疼,我用代碼解釋一下吧,MyRand是一個自定義的生成隨機數的類:
class MyRand
{
private int seed;
public MyRand(int seed)
{
this.seed = seed;
}
public int Next()
{
int next = (seed * 29 + 37) % 1000;
seed = next;
return next;
}
}
如下調用:
MyRand rand = newMyRand(51);
for (int i = 0; i < 10; i++)
{
Console.WriteLine(rand.Next());
}
執行結果如下:
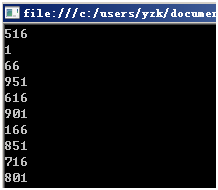
生成的數據是不是看起來"隨機"了。簡單解釋一下這個代碼:我們創建MyRand的一個對象,然後構造函數傳遞一個數51,這個數被賦值給seed,每次調用Next方法的時候根據(seed * 29 + 37) % 1000計算得到一個隨機數,把這個隨機數賦值給seed,然後把生成的隨機數返回。這樣下次再調用Next()的時候seed就不再是51,而是上次生成的隨機數了,這樣就看起來好像每一次生成的內容都很"隨機"了。注意"%1000"取余預算的目的是保證生成的隨機數不超過1000。
當然無論是你運行還是我每次運行,輸出結果都是一樣的隨機數,因為根據給定的初始數據51,我們就可以依次推斷下來下面生成的所有"隨機數"是什麼都可以算出來了。這個初始的數據51就被稱為"隨機數種子",這一系列的516、1、66、951、616……數字被稱為"隨機數序列"。我們把51改成52,就會有這樣的結果:
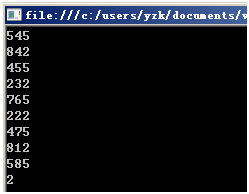
三、樓主好人,跪求種子
那麼怎麼可以使得每次運行程序的時候都生成不同的"隨機數序列"呢?因為我們每次執行程序時候的時間很可能不一樣,因此我們可以用當前時間做"隨機數種子"
MyRand rand = newMyRand(Environment.TickCount);
for (int i = 0; i < 10; i++)
{
Console.WriteLine(rand.Next());
}
Environment.TickCount為"系統啟動後經過的微秒數"。這樣每次程序運行的時候Environment.TickCount都不大可能一樣(靠手動誰能一微秒內啟動兩次程序呢),所以每次生成的隨機數就不一樣了。
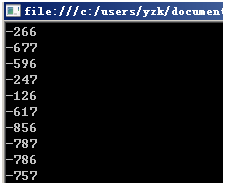
當然如果我們把new MyRand(Environment.TickCount)放到for循環中:
for (int i = 0; i < 100; i++)
{
MyRand rand = newMyRand(Environment.TickCount);
Console.WriteLine(rand.Next());
}
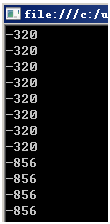
運行結果又變成"很多是連續"的了,原理很簡單:由於for循環體執行很快,所以每次循環的時候Environment.TickCount很可能還和上次一樣(兩行簡單的代碼運行用不了一毫秒那麼長事件),由於這次的"隨機數種子"和上次的"隨機數種子"一樣,這樣Next()生成的第一個"隨機數"就一樣了。從"-320"變成"-856"是因為運行到"-856"的時候時間過了一毫秒。
四、各語言的實現
我們看到.Net的Random類有一個int類型參數的構造函數:
public Random(int Seed)
就是和我們寫的MyRand一樣接受一個"隨機數種子"。而我們之前調用的無參構造函數就是給Random(int Seed)傳遞Environment.TickCount類進行構造的,代碼如下:
public Random() : this(Environment.TickCount)
{
}
這下我們終於明白最開始的疑惑了。
同樣道理,在C/C++中生成10個隨機數不應該如下調用:
int i;
for(i=0;i<10;i++)
{
srand( (unsigned)time( NULL ) );
printf("%d\n",rand());
}
而應該:
srand( (unsigned)time( NULL ) ); //把當前時間設置為"隨機數種子"
int i;
for(i=0;i<10;i++)
{
printf("%d\n",rand());
}
五、"奇葩"的Java
Java學習者可能會提出問題了,在Java低版本中,如下使用會像.Net、C/C++中一樣產生相同的隨機數:
for(int i=0;i<100;i++)
{
Random rand = new Random();
System.out.println(rand.nextInt());
}
因為低版本Java中Rand類的無參構造函數的實現同樣是用當前時間做種子:
public Random() { this(System.currentTimeMillis()); }
但是在高版本的Java中,比如Java1.8中,上面的"錯誤"代碼執行卻是沒問題的:
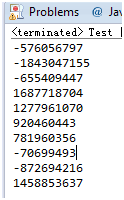
為什麼呢?我們來看一下這個Random無參構造函數的實現代碼:
public Random()
{
this(seedUniquifier() ^ System.nanoTime());
}
private static long seedUniquifier() {
for (;;) {
long current = seedUniquifier.get();
long next = current * 181783497276652981L;
if (seedUniquifier.compareAndSet(current, next))
return next;
}
}
privatestaticfinal AtomicLong seedUniquifier = new AtomicLong(8682522807148012L);
這裡不再是使用當前時間來做"隨機數種子",而是使用System.nanoTime()這個納秒級的時間量並且和采用原子量AtomicLong根據上次調用構造函數算出來的一個數做異或運算。關於這段代碼的解釋詳細參考這篇文章《解密隨機數生成器(2)——從java源碼看線性同余算法》
最核心的地方就在於使用static變量AtomicLong來記錄每次調用Random構造函數時使用的種子,下次再調用Random構造函數的時候避免和上次一樣。
六、高並發系統中的問題
前面我們分析了,對於使用系統時間做"隨機數種子"的隨機數生成器,如果要產生多個隨機數,那麼一定要共享一個"隨機數種子"才會避免生成的隨機數短時間之內生成重復的隨機數。但是在一些高並發的系統中一個不注意還會產生問題,比如一個網站在服務器端通過下面的方法生成驗證碼:
Random rand = new Random();
Int code = rand.Next();
當網站並發量很大的時候,可能一個毫秒內會有很多個人請求驗證碼,這就會造成這幾個人請求到的驗證碼是重復的,會給系統帶來潛在的漏洞。
再比如我今天看到的一篇文章《當隨機不夠隨機:一個在線撲克游戲的教訓》裡面就提到了"由於隨機數產生器的種子是基於服務器時鐘的,黑客們只要將他們的程序與服務器時鐘同步就能夠將可能出現的亂序減少到只有 200,000 種。到那個時候一旦黑客知道 5 張牌,他就可以實時的對 200,000 種可能的亂序進行快速搜索,找到游戲中的那種。所以一旦黑客知道手中的兩張牌和 3 張公用牌,就可以猜出轉牌和河牌時會來什麼牌,以及其他玩家的牌。"
這種情況有如下幾種解決方法:
七、真隨機數發生器
根據我們之前的分析,我們知道這些所謂的隨機數不是真的"隨機",只是看起來隨機,因此被稱為"偽隨機算法"。在一些對隨機要求高的場合會使用一些物理硬件采集物理噪聲、宇宙射線、量子衰變等現實生活中的真正隨機的物理參數來產生真正的隨機數。
當然也有聰明的人想到了不借助增加"隨機數發生器"硬件的方法生成隨機數。我們操作計算機時候鼠標的移動、敲擊鍵盤的行為都是不可預測的,外界命令計算機什麼時候要執行什麼進程、處理什麼文件、加載什麼數據等也是不可預測的,因此導致的CPU運算速度、硬盤讀寫行為、內存占用情況的變化也是不可預測的。因此如果采集這些信息來作為隨機數種子,那麼生成的隨機數就是不可預測的了。
在Linux/Unix下可以使用"/dev/random"這個真隨機數發生器,它的數據主來來自於硬件中斷信息,不過產生隨機數的速度比較慢。
Windows下可以調用系統的CryptGenRandom()函數,它主要依據當前進程Id、當前線程Id、系統啟動後的TickCount、當前時間、QueryPerformanceCounter返回的高性能計數器值、用戶名、計算機名、CPU計數器的值等等來計算。和"/dev/random"一樣CryptGenRandom()的生成速度也比較慢,而且消耗比較大的系統資源。
當然.Net下也可以使用RNGCryptoServiceProvider 類(System.Security.Cryptography命名空間下)來生成真隨機數,根據StackOverflow上一篇帖子介紹RNGCryptoServiceProvider 並不是對CryptGenRandom()函數的封裝,但是和CryptGenRandom()原理類似。
八、總結
有人可能會問:既然有"/dev/random" 、CryptGenRandom()這樣的"真隨機數發生器",為什麼還要提供、使用偽隨機數這樣的"假貨"?因為前面提到了"/dev/random" 、CryptGenRandom()生成速度慢而且比較消耗性能。在對隨機數的不可預測性要求低的場合,使用偽隨機數算法即可,因為性能比較高。對於隨機數的不可預測性要求高的場合就要使用真隨機數發生器,真隨機數發生器硬件設備需要考慮成本問題,而"/dev/random"、CryptGenRandom()則性能較差。
萬事萬物都沒有完美的,沒有絕對的好,也沒有絕對的壞,這才是多元世界美好的地方。