這篇文章本來准備前幾天就得寫的,誰也沒想到這段時間公司的RC太多了,含酸苦逼的加班,加班。。。所以在大一點的公司上班,
寫代碼的責任心一定要強,或許就因為你的一些小bug,給公司帶來不少損失。。。這在以前公司真的沒多大體會的。
好了,繼續說說架構的演變,從第四代架構中可以看到,我們通過做應用程序層的負載均衡可以比較完美的解決了在整個架構中讓應
用程序層不再成為瓶頸,通過A10,我們可以讓用戶的訪問請求分發到集群中的任何一台服務器上,當訪問量繼續膨脹的時候,我們就可
以繼續在集群中增加服務器來解決負載的壓力,達到系統的可伸縮性,現在我們的業務規模像滾雪球一樣越來越大,用戶數暴增。。。這
時候我們緩存中的數據也越來越多,雖然我們用了緩存,但是大量的“”和“",導致數據庫壓力非常大,這時候
數據庫的壓力成為了我們架構中的瓶頸。
既然數據庫成為了我們第四代架構的瓶頸,這時候必須解決數據庫的壓力問題,最常見的做法也就是“讀寫分離”,將寫和讀的庫進行拆
分來緩解數據庫的壓力。
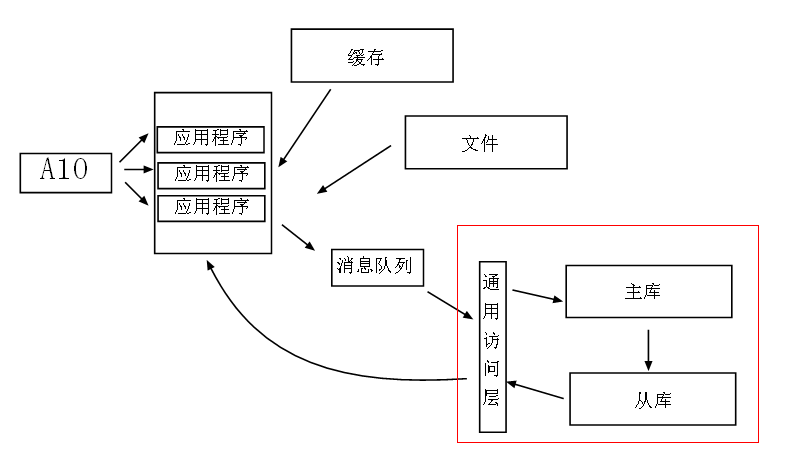
現在我們做了多個庫,寫的時候進主庫,然後數據庫分發到從庫中,然後應用程序在從庫中讀取,這裡為了讓數據庫對應用程序更加
透明,我們通常加一個“數據訪問層”,在攜程裡面就是在企業庫上進行了一層封裝以及安全性采用了all in one 模式,可以看到第五代
架構對數據庫的壓力有了很大的緩解。
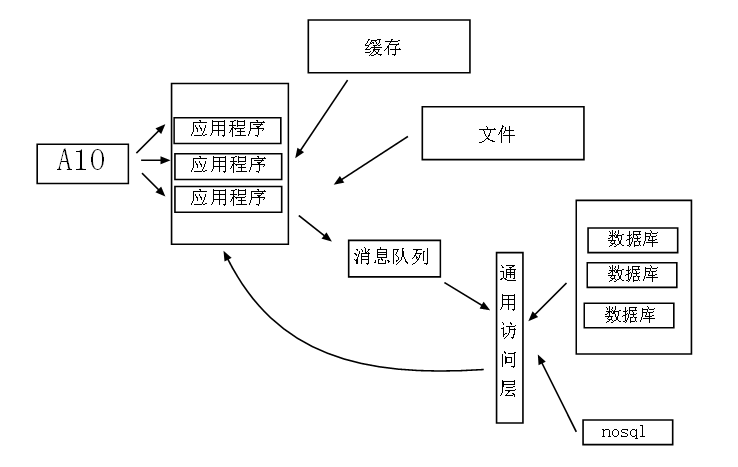
經過幾個月業務噴井式的發展之後,我們會發現數據庫檢索越來越慢,單表數據量已經差不多爆炸了。。。已經嚴重影響到系統性能,
用戶抱怨不斷,這時候“數據檢索”成為了我們系統的嚴重瓶頸。
既然檢索成了瓶頸,我們必須對數據庫進行拆分,盡可能的減少檢索中的數據量規模以及盡可能的優化算法。
1:業務分庫
我們將不同的業務分攤到不同的業務服務器上,而不是將其耦合在一個數據庫裡面,從而建立起數據庫集群,分流應用層對數
據庫的壓力。
2:分表
可以采用時間劃分,將三個月之後的數據放入到歷史表裡面,當前表只保存三個月之內的數據,而從極大提供單表的檢索能力。
3:采用nosql
nosql就是為了web而生,分詞,系統日志等等,一樣都讓不少nosql,而且nosql有其天生的負載均衡。
4:優化算法
棧,隊列,二叉樹,哈希 等等變換和非變換的數據結構在這種大數據的場景下可以得到靈活運用,這也是區分高級程序員和低等
碼農
當你的架構到這個程度的時候,差不到公司的人數也過千了,這時候我們的業務會分成很多產品線的,比如:機票事業部,酒店
事業部,旅游度假事業部,攻略社區事業部,每個事業部只會負責自己的產品架構,從而將我們的架構再次細分,從技術角度看,這些
事業部又可以提煉出公共的部門,比如登錄模塊,訂單處理等等這些可復用的模塊,可以相應的成立公共平台事業部和框架架構部,當
這個架構繼續往下發展的話,就有了現在的各種雲,也就成了各種變錢的工具了,就比如現在的博客園托管在阿裡雲之上。。。
終於在今天,結束了高層重視的IVR項目的所有事情,最後祭奠一下,