Array類是所有一維和多維數組的隱式基類,同時也是實現標准集合接口的最基本的類型。Array類實現了類型統一,因此它為所有數組提供了一組通用的方法,不論這些數組元素的類型,這些通用的方法均適用。
正因為數組如此重要,所以C#為聲明數組和初始化數組提供了明確的語法。在使用C#語法聲明一個數組時,CLR隱式地構建Array類--合成一個偽類型以匹配數組的維數和數組元素的類型。而且這個偽類型實現了generic集合接口,比如IList<string>接口。
CLR在創建數組類型實例時會做特殊處理--在內存中為數組分配連續的空間。這就使得索引數組非常高效,但這卻阻止了對數組的修改或調正數組大小。
Array類實現了IList<T>接口和IList接口。Array類顯示地實現了IList<T>接口,這是為了保證接口的完整性。但是在固定長度集合比如數組上調用IList<T>接口的Add或Remove方法時,會拋出異常(因為數組實例一旦聲明之後,就不能更改數組的長度)。Array類提供了一個靜態的Resize方法,使用這個方法創建一個新的數組實例,然後復制當前數組的元素到新的實例。此外,在程序中,當在任何地方引用一個數組都會執行最原始版本的數組實例。因此如果希望集合大小可以調整,那麼你最好使用List<T>類。
數組元素可以是值類型也可以是引用類型。值類型數組元素直接存在數組中,比如包含3個整數的數組會占用24個字節的連續內存。而引用類型的數組元素,占用的空間和一個引用占用的空間一樣(32位環境中4個字節,64為環境中8個字節)。我們先來看下面的代碼:
[] numbers = [] =1] = 7= StringBuilder[] = StringBuilder(] = StringBuilder(] = StringBuilder();
對應的內存分配變化如下面幾張圖所示:
執行完int[] numbers=new int[3]之後,在內存中分配了8×3=24個字節,每個字節都為0。
執行完numbers[0]=1之後,數組聲明後的第一個8字節變為00 00 00 01。
同樣地,執行完numbers[1]=7之後,第二段8個字節變為00 00 00 07。
對應引用類型的數組,我們用一張圖來說明內存分配:
看起來分復雜,其實內存分配示意圖如下
通過Clone方法可以克隆一個數組,比如arrayB = arrayA.Clone()。但是,克隆數組執行淺拷貝,也就是說數組自己包含的那部分內容才會被克隆。簡單說,如果數組包含的是值類型對象,那麼克隆了這些對象的值。而數組的子元素是引用類型,那麼僅僅克隆引用類型的地址。
StringBuilder[] builders2 == (StringBuilder[])builders.Clone();
與之對應的內存分配示意圖:
如果需要執行深拷貝,即克隆引用類型的子對象;那麼你需要遍歷數組並手動的克隆每個數組元素。深克隆規則也適用於.NET其他集合類型。
盡管數組在設計時,主要使用32位的索引,它也在一定程度上支持64位索引,這需要使用那些既接收Int32又接收Int64類型參數的方法。這些重載方法在實際中並沒有意義,因為CLR不允許任何對象--包括數組在內--的大小超過2G(無論32位的系統還是64位的系統)
創建數組和索引數組的最簡單方式就是通過C#語言的構建器
Int[] myArray={,, first=myArray[ last = myArray[myArray.Length-];
或者,你可以通過調用Array.CreateInstance方法動態地創建一個數組實例。你可以通過這種方式指定數組元素的類型和數組的維度。而GetValue和SetValue方法允許你訪問動態創建的數組實例的元素。
Array a = Arrat.CreateInstance((), a.SetValue(, s = ()a.getValue([] cSharpArray = ( s2 = cSharpArray[];
動態創建的零索引的數組可以轉換為一個匹配或兼容的C#數組。比如,如果Apple是Fruit的子類,那麼Apple[]可以轉換成Fruit[]。這也是為什麼object[]沒有作為統一的數組類型,而是使用Array類;答案在於object[]不僅與多維數組不兼容,而且還與值類型數組不兼容。因此我們使用Array類作為統一的數組類型。
GetValue和SetValue對編譯器生成的數組也起作用,若想編寫一個方法處理任何類型的數組和任意維度的數組,那麼這兩個方法非常有用。對於多維數組,這兩個方法可以把一個數組當作索引參數。
GetValue( SetValue( value, [] indices)
下面的方法在屏幕打印任意數組的第一個元素,無論數組的維度
+ [] indexers = +[] oneD = { , , [,] twoD = { {,}, {,
WriteFirstValue (twoD);
}
在使用SetValue方法時,如果元素與數組類型不兼容,那麼會拋出異常。
無論采取哪種方式實例化一個數組之後,那麼數組元素自動初始化了。對於引用類型元素的數組而言,初始化數組元素就是把null值賦給這些數組元素;而對於值類型數組元素,那麼會把值類型的默認值賦給數組元素。此外,調用Array類的Clear方法也可以完成同樣的功能。Clear方法不會影響數組大小。這和常見的Clear方法(比如ICollection<T>.Clear方法)不一樣,常見的Clear方法會清除集合的所有元素。
通過foreach語句,可以非常方便地遍歷數組:
[] myArray = { , , ( val
你還可以使用Array.ForEach方法來遍歷數組
ForEach<T> (T[] array, Action<T> action);
該方法使用Action代理,此代理方法的簽名是(接收一個參數,不返回任何值):
Action<T> (T obj);
下面的代碼顯示了如何使用ForEach方法
Array.ForEach ([] { , , }, Console.WriteLine);
你可能會很好奇Array.ForEach是如何執行的,它就是這麼執行的
ForEach<T>(T[] array, Action<T>( array == ArgumentNullException(( action == ArgumentNullException(( i = ; i < array.Length; i++
在內部執行for循環,並調用Action代理。在上面的實例中,我們調用Console.WriteLine方法,所以可以在屏幕上輸出1,2,3。
Array提供了下列方法或屬性以獲取數組的長度和數組的維度:
GetLength ( GetLongLength ( Length { LongLength { GetLowerBound ( GetUpperBound ( Rank { ; }GetLength和GetLongLength返回指定維度的長度(0表示一維數組),Length和LongLength返回數組中所有元素的總數(包含了所有維度)。
GetLowerBound和GetUpperBound對於多維數組非常有用。GetUpperBound返回的結果等於指定維度的GetLowerBound+指定維度的GetLength
Array類對外提供了一系列方法,以在一個維度中查找元素。比如:
如果沒有找到指定的值,數組的這些搜索方法不會拋出異常。相反,搜索方法返回-1(假定數組的索引都是以0開始),或者返回generic類型的默認值(int返回0,string返回null)。
二進制搜索速度很快,但是它僅僅適用於排序後的數組,而且數組的元素是根據大小排序,而不是根據相等性排序。正因為如此,所以二進制搜索方法可以接收IComparer或IComparer<T>對象以對元素進行排序。傳入的IComparer或IComparer<T>對象必須和當前數組所使用的排序比較器一致。如果沒有提供比較器參數,那麼數組會使用默認的排序算法。
IndexOf和LastIndexOf方法對數組進行簡單的遍歷,然後根據指定的值返回第一個(或最後一個)元素的位置。
以斷定為基礎(predicate-based)的搜索方法接受一個方法代理或lamdba表達式判斷元素是否滿足“匹配”。一個斷定(predicate)是一個簡單的代理,該代理接收一個對象並返回bool值:
Precicate<T>(T );
下面的例子中,我們搜索字符數組中包含字母A的字符:
Main([] names = { , , match = ContainsA( name.Contains(
上面的代碼可以簡化為:
Main([] names = { , , match = Array.Find(names, ( name) { name.Contains(
如果使用lamdba表達式,那麼代碼還可以更簡潔:
Main([] names = { , , match = Array.Find(names, name=>name.Contains(
FindAll方法則從數組中返回滿足斷言(predicate)的所有元素。實際上,該方法等同於Enumerable.Where方法,只不過數組的FindAll是從數組中返回匹配的元素,而Where方法從IEnumerable<T>中返回。
如果數組成員滿足指定的斷言(predicate),那麼Exists方法返回True,該方法等同於Enumerable.Any方法。
所以數組的所有成員都滿足指定的斷言(predicate),那麼TrueForAll方法返回True,該方法等同於Enumerable.All方法。
數組有下列自帶的排序方法:
Sort<T> Sort(Array keys[], Array items);
上面的方法都有重載的版本,重載方法接受下面這些參數:
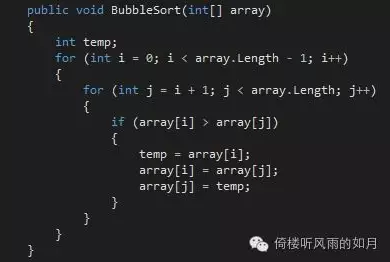
下面的代碼演示了如何實現一個簡單的排序:
Main([] numbers = { ,, ( number
Sort方法還可以接收兩個兩個數組類型的參數,然後基於第一個數組的排序結果,對每個數組的元素進行排序。下面的例子中,數字數組和字符數組都按照數字數組的順序進行排序。
Main([] numbers = { ,,[] names = { , , ( number
( name
Array.Sort方法要求數組實現了IComparer接口。這就是說C#的大多數類型都可以排序。如果數組元素不能進行比較,或你希望重載默認的排序,那麼你需要在調用Sort方法時,需提供自定義的Comparison。所以自定義排序算法有下面兩種實現方式:
1)通過一個幫助對象實現IComparer或IComparer<T>接口
Sort<T>(T[] array, System.Collections.Generic.IComparer<T> comparer)
2)通過Comparison接口
Sort<T>(T[] array, Comparison<T> comparison)
Comparison代理遵循IComparer<T>.CompareTo語法:
Comparison<T> (T x, T y);如果x的位置在y之前,那麼返回-1;如果x在y之後,返回1,如果位置相同,那麼返回0。
我們來看一下Array的Sort<T>(T[]array, Comparison<T> comparison)方法的源代碼:
Sort<T>(T[] array, Comparison<T><T> comparer = FunctorComparer<T>
由此,可內部,Comparison<T>轉換成IComparer<T>,因此在實際中,需要實現自定義排序時,如果需要考慮性能,那麼推薦使用第一種方式。此外,我們分析Sort<T>(T[] array, System.Collections.Generic.IComparer<T> comparer)的源代碼,
Sort<T>(T[] array, index, length, System.Collections.Generic.IComparer<T> (length > (comparer == || comparer == Comparer<T> (TrySZSort(array, , index, index + length - <T>
我們可以看到,首先嘗試調用調用非托管代碼的Sort方法,如果成功排序,直接返回。否則調用非托管代碼(C#的ArraySortHelper)的Sort方法進行排序:
Sort(T[] keys, index, length, IComparer<T> (comparer == = Comparer<T>+ index - InvalidOperationException(Environment.GetResourceString(
如果有興趣,可以繼續分析IntrospectiveSort方法和DepthLimitedQuickSort,不過MSDN已經給出了總結,
意識是說,排序算法有三種:
使用下面的方法,可以反轉數組的所有元素或部分元素
Reverse (Array array, index, length);
如果你在乎性能,那麼請不要直接調用Array的Reverse方法,而是應該創建一個自定義的RerverseComparer。比如下面的例子中,調用Array.Reverse和CustomReverse在我的電腦上兩者的性能高差距為20%左右
Main( seeds = = = ( i = ; i < seeds; i++= Staff { StaffNo = r.Next( == + (t2 - t1).Milliseconds + == + (t2 - t1).Milliseconds + StaffNo { ; Name { ; CompareTo(= obj StaffComparer : IComparer<Staff>
執行結果:
Array提供了四個方法以實現淺拷貝:Clone,CopyTo,Copy和ConstrainedCopy。前兩個方法是實例方法,後面兩個是靜態方法。
Clone方法返回一個全新的(淺拷貝)數組 。CopyTo和Copy方法復制數組的連續子集。復制一個多維矩形數組需要你的多維索引映射到一個線性索引。比如,一個3×3的數組position,那麼postion[1,1]對應的線性索引為1*3+1=4。原數組和目標數組的范圍可以交換,不會帶來任何問題。
ConstrainedCopy執行原子操作,如果所要求的元素不能全部成功地復制,那麼操作回滾。
Array還提供AsReadOnly方法,它返回一個包裝器,以防止數組元素的值被更改。
最後,Clone方法是由外部的非托管代碼實現
Object MemberwiseClone()
同樣地,Copy,CopyTo, ConstraintedCopy也都是調用外部實現
Copy(Array sourceArray, sourceIndex, Array destinationArray, destinationIndex, length, reliable);
Array.ConvertAll創建並返回一個類型為TOutput的新數組,調用Converter代理以復制元素到新的數組中。Converter的定義如下:
TOutput Converter<TInput,TOutput>(TInput input)
下面的代碼展示了如果把一個浮點數數組轉換成int數組
[] reals = { , , [] wholes = Array.ConvertAll(reals, f => ( a Resize方法創建一個新數組,然後復制元素到新數組,然後返回新數組;原數組不發生改變。