之前對幾個沒什麼理解,只是簡單的用過可空類型,也是知道怎麼用,至於為什麼,還真不太清楚,通過整理本文章學到了很多知識,也許對於以後的各種代碼優化都有好處。
本文的重點就是:值類型直接存儲其值,引用類型存儲對值的引用,值類型存在堆棧上,引用類型存儲在托管堆上,值類型轉為引用類型叫做裝箱,引用類型轉為值類型叫拆箱。
這一句話概括起來很簡單,可是真正的理解起來卻沒那麼簡單,對於我來說吧。
C#值類型數據直接在他自身分配到的內存中存儲數據,而C#引用類型只是包含指向存儲數據位置的指針。
C#值類型,我們可以把他歸納成三類:
第一類: 基礎數據類型(string類型除外):包括整型、浮點型、十進制型、布爾型。
整型包括:sbyte、byte、char、short、ushort、int、uint、long、ulong 這九種類型;
浮點型就包括 float 和 double 兩種類型;
十進制型就是 decimal ;
布爾型就是 bool 型了。
第二類:結構類型:就是 struct 型
第三類:枚舉類型:就是 enum 型
C#引用類型有五種:class、interface、delegate、object、string。
上面說的是怎麼區分哪些C#值類型和C#引用類型,而使用上也是有區別的。所有值類型的數據都無法為null的,聲明後必須賦以初值;引用類型才允許為null。
不過這裡我們可以看一下可空類型
可空類型可以表示基礎類型的所有值,另外還可以表示 null 值。可空類型可通過下面兩種方式中的一種聲明:
System.Nullable<T>? variable
T 是可空類型的基礎類型。T 可以是包括 struct 在內的任何值類型;但不能是引用類型。
1.值類型後加問號表示此類型為可空類型,如int? i = null;
? d = <> e = ;
2.可空類型與一元或二元運算符一起使用時,只要有一個操作數為null,結果都為null;

3.比較可空類型時,只要一個操作數為null,比較結果就為false。

值類型和引用類型在賦值(或者說復制)的時候也是有區別的。值類型數據在賦值的時候是直接復制值到新的對象中,而引用類型則只是復制對象的引用。
最後,值類型存在堆棧上,引用類型存儲在托管堆上。接下來我們來看看堆和棧吧。
Stack是指堆棧,Heap是指托管堆,在C#中的叫法應該是這樣的。
1、堆棧stack:堆棧中存儲值類型。
堆棧實際上是自上向下填充的,即由高內存地址指向低內存地址填充。
堆棧的工作方式是先分配的內存變量後釋放(先進後出原則)。堆棧中的變量是從下向上釋放,這樣就保證了堆棧中先進後出的規則不與變量的生命周期起沖突!
堆棧的性能非常高,但是對於所有的變量來說還不太靈活,而且變量的生命周期必須嵌套。
通常我們希望使用一種方法分配內存來存儲數據,並且方法退出後很長一段時間內數據仍然可以使用。此時就要用到堆(托管堆)!
2、C#堆棧的工作方式
Windwos使用虛擬尋址系統,把程序可用的內存地址映射到硬件內存中的實際地址,其作用是32位處理器上的每個進程都可以使用4GB的內存-無論計算機上有多少硬盤空間(在64位處理器上,這個數字更大些)。這4GB內存包含了程序的所有部份-可執行代碼,加載的DLL,所有的變量。這4GB內存稱為虛擬內存。
4GB的每個存儲單元都是從0開始往上排的。要訪問內存某個空間存儲的值。就需要提供該存儲單元的數字。在高級語言中,編譯器會把我們可以理解的名稱轉換為處理器可以理解的內存地址。
在進程的虛擬內存中,有一個區域稱為堆棧,用來存儲值類型。另外在調用一個方法時,將使用堆棧復制傳遞給方法的所有參數。
我們來看一下下面的小例子:
聲明了a之後,在內部代碼塊中聲明了b,然後內部代碼塊終止,b就出了作用域,然後a才出作用域。在釋放變量的時候,其順序總是與給它們分配內存的順序相反,後進先出,這就是堆棧的工作方式。
堆棧是向下填充的,即從高地址向低地址填充。當數據入棧後,堆棧指針就會隨之調整,指向下一個自由空間。我們來舉個例子說明。
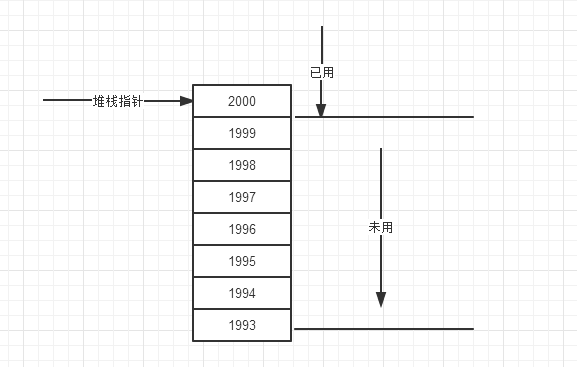
如圖,假如堆棧指針2000,下一個自由空間是1999。下面的代碼會告訴編譯器需要一些存儲單元來存儲一個整數和一個雙精度浮點數。
c = d=
這兩個都是值類型,自然是存儲在堆棧中。聲明c賦值2後,c進入作用域。int類型需要4個字節,c就存儲在1996~1999上。此時,堆棧指針就減4,指向新的已用空間的末尾1996,下一個自由空間為1995。下一行聲明d賦值3.5後,double需要占用8個字節,所以存儲在1988~1995上,堆棧指針減去8。
當d出作用域時,計算機就知道這個變量已經不需要了。變量的生存期總是嵌套的,當d在作用域的時候,無論發生什麼事情,都可以保證堆棧指針一直指向存儲d的空間。刪除這個d變量的時候堆棧指針遞增8,現在指向d曾經使用過的空間,此處就是放置閉合花括號的地方。然後c也出作用域,堆棧指針再遞增4。
此時如果放入新的變量,從1999開始的存儲單元就會被覆蓋了。
3、堆(托管堆)heap堆(托管堆)存儲引用類型。
此堆非彼堆,.NET中的堆由垃圾收集器自動管理。
與堆棧不同,堆是從下往上分配,所以自由的空間都在已用空間的上面。
4、托管堆的工作方式
堆棧有很高的性能,但要求變量的生命周期必須嵌套(後進先出)。通常我們希望使用一個方法來分配內存,來存儲一些數據,並在方法退出後很長的一段時間內數據仍是可用的。用new運算符來請求空間,就存在這種可能性-例如所有引用類型。這時候就要用到托管堆了。
托管堆是進程可用4GB的另一個區域,我們用一個例子了解托管堆的工作原理和為引用數據類型分配內存。假設我們有一個Cat類。
Name { ;
來看下面這個最簡單的方法,當然著兩行代碼,在第一節中也有提到過http://www.cnblogs.com/aehyok/p/3499822.html。
cat = }
第三行代碼聲明了一個Cat的引用cat,在堆棧上給這個引用分配存儲空間,但這只是一個引用,而不是實際的Cat對象。cat引用包含了存儲Cat對象的地址-需要4個字節把0~4GB之間的地址存儲為一個整數-因此cat引用占4個字節。
第四行代碼首先分配托管堆上的內存,用來存儲Cat實例,然後把變量cat的值設置為分配給Cat對象的內存地址。
Cat是一個引用類型,因此是放在內存的托管堆中。為了方便討論,假設Cat對象占用32字節,包括它的實例字段和.NET用於識別和管理其類實例的一些信息。為了在托管堆中找到一個存儲新Cat對象的存儲位置,.NET運行庫會在堆中搜索一塊連續的未使用的32字節的空間,假定其起始地址是1000。而在堆棧中的內存地址的四個字節為:1996到1999。在實例化cat之前應該是這樣的。
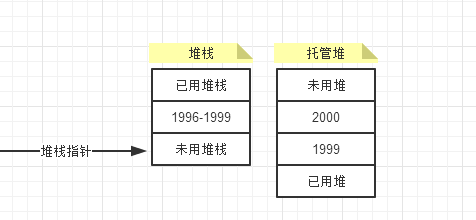
cat實例化,給Cat對象分配空間之後,內存變化為 cat在堆棧中使用1996到1999的內存地址,然後對Cat對象分配空間之後。
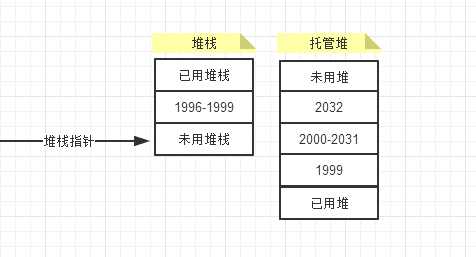
這裡與堆棧不同,堆上的內存是向上分配的,所有自由空間都在已用空間的上面。
以上例子可以看出,建議引用變量的過程比建立值變量的過程復雜的多,且不能避免性能的降低-.NET運行庫需要保持堆的信息狀態,在堆添加新數據時,這些信息也需要更新(這個會在堆的垃圾收集機制中提到)。盡管有這麼些性能損失,但還有一種機制,在給變量分配內存的時候,不會受到堆棧的限制:
把一個引用變量e的值賦給另一個相同類型的變量f,這兩個引用變量就都引用同一個對象了。當變量f出作用域的時候,它會被堆棧刪除,但它所引用的對象依然保留在堆上,因為還有一個變量e在引用這個對象。只有該對象的數據不再被任何變量引用時,它才會被刪除。
5、托管堆的垃圾收集
對象不再被引用時,會刪除堆中已經不再被引用的對象。如果僅僅是這樣,久而久之,堆上的自由空間就會分散開來,給新對象分配內存就會很難處理,.NET運行庫必須搜索整個堆才能找到一塊足夠大的內存塊來存儲整個新對象。
但托管堆的垃圾收集器運行時,只要它釋放了能釋放的對象,就會壓縮其他對象,把他們都推向堆的頂部,形成一個連續的塊。在移動對象的時候,需要更新所有對象引用的地址,會有性能損失。但使用托管堆,就只需要讀取堆指針的值,而不用搜索整個鏈接地址列表,來查找一個地方放置新數據。
因此在.NET下實例化對象要快得多,因為對象都被壓縮到堆的相同內存區域,訪問對象時交換的頁面較少。Microsoft相信,盡管垃圾收集器需要做一些工作,修改它移動的所有對象引用,導致性能降低,但這樣性能會得到彌補。
1、裝箱是將值類型轉換為引用類型 ;拆箱是將引用類型轉換為值類型。
利用裝箱和拆箱功能,可通過允許值類型的任何值與Object 類型的值相互轉換,將值類型與引用類型鏈接起來。
例如,如下的代碼:
Main( val = obj =
這其實就是一個簡單裝箱的過程,是將值類型轉換為引用類型的過程。
Main( val = obj = num = (
接著前面裝箱的例子,那麼int num=(int)obj; 這個過程就是拆箱的過程。
注意:被裝過箱的對象才能被拆箱
2、為何需要裝箱?(為何要將值類型轉為引用類型?)
一種最普通的場景是,調用一個含類型為Object的參數的方法,該Object可支持任意為型,以便通用。當你需要將一個值類型(如Int32)傳入時,需要裝箱。
另一種用法是,一個非泛型的容器,同樣是為了保證通用,而將元素類型定義為Object。於是,要將值類型數據加入容器時,需要裝箱。
3、裝箱/拆箱的內部操作。
裝箱:
對值類型在堆中分配一個對象實例,並將該值復制到新的對象中。按三步進行。
第一步:新分配托管堆內存(大小為值類型實例大小加上一個方法表指針和一個同步塊索引SyncBlockIndex)。
第二步:將值類型的實例字段拷貝到新分配的內存中。
第三步:返回托管堆中新分配對象的地址。這個地址就是一個指向對象的引用了。
拆箱:
拆箱過程與裝箱過程正好相反。看一段代碼:
a = b = c = ()b;
拆箱必須非常小心,確保該值變量有足夠的空間存儲拆箱後得到的值。C#int只有32位,如果把64位的long值拆箱為int時,會產生一個InvalidCastExecption異常。
顯然,從原理上可以看出,裝箱時,生成的是全新的引用對象,這會有時間損耗,也就是造成效率降低。裝箱操作和拆箱操作是要額外耗費cpu和內存資源的,所以在c# 2.0之後引入了泛型來減少裝箱操作和拆箱操作消耗。
4、非泛型的裝箱和拆箱以及泛型
array = ( value
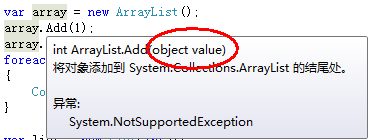

代碼聲明了一個ArrayList對象,向ArrayList中添加兩個數字1,2;然後使用foreach將ArrayList中的元素打印到控制台。
在這個過程中會發生兩次裝箱操作和兩次拆箱操作,在向ArrayList中添加int類型元素時會發生裝箱,在使用foreach枚舉ArrayList中的int類型元素時會發生拆箱操作,將object類型轉換成int類型,在執行到Console.WriteLine時,還會執行兩次的裝箱操作;這一段代碼執行了6次的裝箱和拆箱操作;如果ArrayList的元素個數很多,執行裝箱拆箱的操作會更多。
list = List<> ( value
代碼和1中的代碼的差別在於集合的類型使用了泛型的List,而非ArrayList.上述代碼只會在Console.WriteLine()方法時執行2次裝箱操作,不需要拆箱操作。
可以看出泛型可以避免裝箱拆箱帶來的不必要的性能消耗;當然泛型的好處不止於此,泛型還可以增加程序的可讀性,使程序更容易被復用等等,至於泛型以後再做詳細介紹。
趕腳自己還是學了不少東西的,沒事的時候多拿出來看看,說不定還會有意想不到的收獲呢,繼續加油!