相信很多人都有過HTML文檔解析的需求。比如我們抓取了某1個網站的頁面數據,格式就是HTML的格式。以前我們都是通過正則表達式來進行解析,但是發現有一些問題。解析HTML文檔時並不容易,如果文檔的格式稍有變化很可能就不能正確的匹配。因此我們需要專門的工具來幫助我們輕松的解析HTML文檔。
其實已經有一個非常不錯的工具提供了。比如HtmlAgilityPack。它可以幫助我們解析HTML文檔就像用XmlDocument類來解析XML一樣輕松、方便。
這個工具可以在http://htmlagilitypack.codeplex.com/下載到,裡面有支持各種.NET Framework的版本的dll。
好了,下面提供一個足夠Simple的例子給大家。大家可以在此基礎之上,舉一反三。
比如要解析下面的HTML。
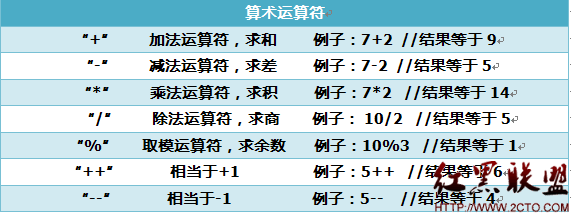
時間 類型 名稱 單位 金額 2013-12-29 發票1 采購物資發票1 某某公司1 123元 2013-12-29 發票2 采購物資發票2 某某公司2 321元
以控制台項目為例,首先要引用HtmlAgilityPack.dll文件,這樣才能使用dll裡面的類和方法。
static void Main(string[] args)
{
string strWebContent = @"
時間
類型
名稱
單位
金額
" +
@"
2013-12-29
發票1
采購物資發票1
某某公司1
123元
" +
@"
2013-12-29
發票2
采購物資發票2
某某公司2
321元
";
List datas = new List();//定義1個列表用於保存結果
HtmlDocument htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(strWebContent);//加載HTML字符串,如果是文件可以用htmlDocument.Load方法加載
HtmlNodeCollection collection = htmlDocument.DocumentNode.SelectSingleNode("table/tbody").ChildNodes;//跟Xpath一樣,輕松的定位到相應節點下
foreach (HtmlNode node in collection)
{
//去除\r\n以及空格,獲取到相應td裡面的數據
string[] line = node.InnerText.Split(new char[] { '\r', '\n', ' ' }, StringSplitOptions.RemoveEmptyEntries);
//如果符合條件,就加載到對象列表裡面
if (line.Length == 5)
datas.Add(new Data() { 時間 = line[0], 類型 = line[1], 名稱 = line[2], 單位 = line[3], 金額 = line[4] });
}
//循環輸出查看結果是否正確
foreach (var v in datas)
{
Console.WriteLine(string.Join(",", v.時間, v.類型, v.名稱, v.單位, v.金額));
}
}上面就是完整的代碼,注釋也很清楚。
最後看一下解析的結果: