好一段時間沒寫博客了,這次我們來一起談談SQL文件執行器的功能實現,在ERP軟件升級時往往在客戶端程序更新的同時也要對數據庫進行升級,ERP程序開發人員會對數據庫升級的執行代碼在開發的過程中以SQL文件的形式記錄下來或者保存到特定格式的文件中供軟件升級時使用,有些ERP軟件會附帶開發數據庫升級工具來方便實施人員執行軟件升級操作或者ERP軟件內置數據庫升級功能,不管使用什麼樣的方式能達到軟件升級的目的就是好方法,這次我們就來剝離這部分的功能來實現一個SQL文件執行器,不特定於SQL文件,只要文件裡面包含有SQL語法,而且能正常得到執行,在本執行器中就能正確的執行它(本次我們主要爭對SQL文件,其他格式文件只要把相關控制去掉就好了,只是得不到很好的控制比較亂,或者你有更好的方法)。介紹性引入就到此為止了,接下來我們開始進入主題,研究一下SQL執行器的原理及設計思路吧。
一、SQL文件執行器原理分析
在分析原理之前,我們先來規范一下SQL文檔的書寫,我們在一個SQL語句結束的時候換行來個GO關鍵字再換行繼續書寫下一個SQL語句,遇到“USE [數據庫名] ”語句時希望能把此語句單獨放一行。做到以上書寫規范我們開始原理分析:
1.上述SQL規范居然都做到了但是SQL文件裡面的內容還不是我想要的,我想重新規范一下我的SQL文檔,我想理想化它,所以我需要對SQL文件進行重新洗牌,我想我應該一行一行的閱讀它,並把它提取出來去掉前後的空格,我應該重組改文件的內容並且在讀取每一行的同時在其末尾寫入一個換行回車符,而且我還想統計出每一個SQL文件中的SQL語句的個數(循環時會用到),我用GO關鍵字來標記了SQL語句的個數,在閱讀到一行去掉首尾空格後只剩下不區分大小寫的GO時我的統計會+1(統計從1開始),哦,這還永遠不夠,我還沒考慮到USE關鍵字的處理,通常會選擇一個數據庫來執行相應的SQL文件,USE關鍵字在切換著數據庫,我需要在檢測到USE語句時切換數據庫為USE後面跟著的數據庫來執行後面的代碼,所以我要把USE語句單獨剝離開來以待做特殊的處理,往往我們寫SQL文件的時候在USE語句的前後都不帶GO關鍵字的,我需要給它加上。有一個需要注意的地方:USE [數據庫名] 後面直接跟著SQL語句的(沒有回車換行),這種寫法在語法上是完全正確的,但是看上去就不是很美觀了,這種方式我這邊就不做處理了,請遵守上述規范吧,再處理下去程序性能就嚴重下降啦,本程序在數據庫切換時是從USE 之後的字符開始到回車換行符結束來取數據庫名的,這種寫法會引發SQL異常。我需要構建一個這樣的方法。
2.在第一點裡面我們對SQL文件進行了格式化,現在開始我希望以GO關鍵字作為分割點,把SQL文件裡面的SQL語法進行分段,我希望一段段的得到執行並返回執行結果,此時我需要一個循環來遍歷文件中的SQL語句並執行它。本工具名字叫做SQL文件執行器很顯然是爭對批量SQL文件的處理的,所以一個循環是永遠不夠的,我還得在外面再套一個循環來遍歷所有的SQL文件,對每個SQL文件進行分析並遍歷其中的SQL語句執行它,這樣就達到我們的目的了。貌似還有一個問題未處理,比如在執行到一半的時候我不執行了需要強制停止他這如何是好呢,強制關閉程序很顯然是不可取的很容易引發未知的數據庫異常或者造成數據丟失這些狀況都是我們不想看到的,那麼有什麼好辦法呢?此時我啟用了臭名遠揚的goto語句來從深層嵌套循環中跳出循環,我讓他在用戶發出停止指令後在執行完當前的SQL語法段後跳出循環,從而停止接下來的SQL語法的執行,這樣子保障了SQL數據的安全,在SQL文件執行的期間,程序是不允許關閉的,除非向程序發出停止指令,並成功停止的時候,才允許程序關閉。
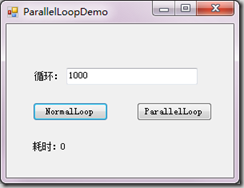
很簡單的一個程序,我就大致的做以上兩點的原理分析吧,接下來我上傳下我的程序界面設計圖吧,大家參考下:
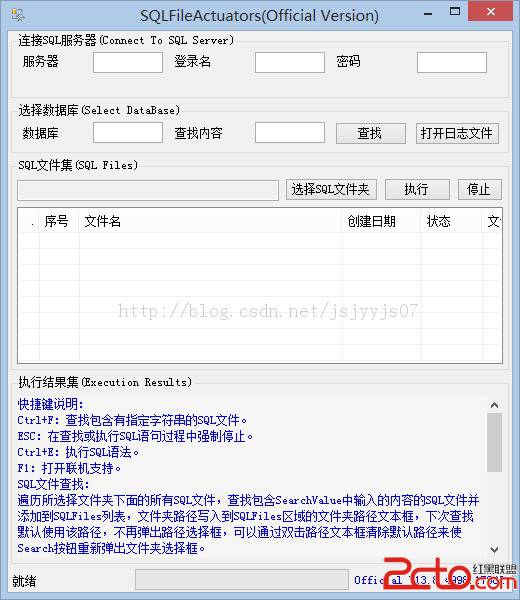 接下來我貼上來一些主要源代碼供參考,代碼可能看上去有些難懂,表述性不是很好,期待大家來改進它:
這是對SQL文件中的語法進行重新洗牌的方法
接下來我貼上來一些主要源代碼供參考,代碼可能看上去有些難懂,表述性不是很好,期待大家來改進它:
這是對SQL文件中的語法進行重新洗牌的方法
/// <summary>
/// 讀取文件內容(SQL關鍵字特殊處理主要針對GO關鍵字)
/// </summary>
/// <param name="path">文件路徑</param>
/// <param name="keywords">關鍵字</param>
/// <param name="str">輸出字符串</param>
/// <param name="i">keywords的個數</param>
public void FileReader(string path,string keywords,out int i,out string str)
{
bool useplusgo = false;//use後面是否跟著go
bool goplususe = false;//use前面是否存在go
StreamReader sr = new StreamReader(path, Encoding.GetEncoding("GB2312"));
//str = sr.ReadToEnd();
string s = null;
string temp = null;
int x = 0;
while ((temp = sr.ReadLine()) != null)
{
if (temp.Trim().ToUpper() == keywords.ToUpper())
{
useplusgo = false;//use語句後面跟著go則關閉use判斷
goplususe = true;//use前面存在go
x++;
s += "\r\n" + keywords + "\r\n \r\n";
}
else if (temp.Trim().Length >= 4 && temp.Trim().ToUpper().Substring(0, 4).Trim() == "USE")
{
temp = temp.Trim().Replace("[", "").Replace("]", "");
//如果use前面不存在go則加上
if (!goplususe && s != "\r\n" && s != null)
{
x++;
s += "\r\n" + keywords + "\r\n\r\n" + temp + "\r\n";
}
else
{
s += temp + "\r\n";
}
useplusgo = true;
}
else
{
goplususe = false;//go後面不跟use關閉判斷
//如果use後面不跟go則加上go
if (useplusgo)
{
x++;
s += "\r\n" + keywords + "\r\n" + temp + "\r\n";
useplusgo = false;//關閉use判斷
}
else
{
s += temp + "\r\n";
}
}
}
i = x;
str = s;
sr.Close();//關閉當前打開的文件
}
這個是處理USE語句的方法
/// <summary>
/// 獲取use後面的數據庫名稱
/// </summary>
/// <param name="str">use字符串行</param>
/// <returns></returns>
public string UseStatementProcessing(string str)
{
string[] strSplit = Regex.Split(str, "\r\n", RegexOptions.IgnoreCase);
int x = strSplit.Length;
string s = "";
if (/*strSplit[0].ToUpper().IndexOf("USE ", 0) >= 0*/Regex.IsMatch(strSplit[0].ToUpper(), "USE ", RegexOptions.IgnoreCase))
{
s = strSplit[0].Substring(4, strSplit[0].Length - 4).Trim();
}
else if (/*strSplit[1].ToUpper().IndexOf("USE ", 0) >= 0*/Regex.IsMatch(strSplit[1].ToUpper(), "USE ", RegexOptions.IgnoreCase))
{
s = strSplit[1].Substring(4, strSplit[1].Length - 4).Trim();
}
else
{
s = "";
}
return s;
}
這次話題就到此為止吧,這程序比較簡單,大家可以寫寫玩,當作練練手也不錯,主要在於文件的操作和字符串的處理。