昨天下午快下班的時候,無意中聽到公司兩位同事在探討批量向數據庫插入數據的性能優化問題,頓時來了興趣,把自己的想法向兩位同事說了一下,於是有了本文。
公司技術背景:數據庫訪問類(xxx.DataBase.Dll)調用存儲過程實現數據庫的訪問。
技術方案一:
壓縮時間下程序員寫出的第一個版本,僅僅為了完成任務,沒有從程序上做任何優化,實現方式是利用數據庫訪問類調用存儲過程,利用循環逐條插入。很明顯,這種方式效率並不高,於是有了前面的兩位同事討論效率低的問題。
技術方案二:
由於是考慮到大數據量的批量插入,於是我想到了ADO.NET2.0的一個新的特性:SqlBulkCopy。有關這個的性能,很早之前我是親自做過性能測試的,效率非常高。這也是我向公司同事推薦的技術方案。
技術方案三:
利用SQLServer2008的新特性--表值參數(Table-Valued Parameter)。表值參數是SQLServer2008才有的一個新特性,使用這個新特性,我們可以把一個表類型作為參數傳遞到函數或存儲過程裡。不過,它也有一個特點:表值參數在插入數目少於 1000 的行時具有很好的執行性能。
技術方案四:
對於單列字段,可以把要插入的數據進行字符串拼接,最後再在存儲過程中拆分成數組,然後逐條插入。查了一下存儲過程中參數的字符串的最大長度,然後除以字段的長度,算出一個值,很明顯是可以滿足要求的,只是這種方式跟第一種方式比起來,似乎沒什麼提高,因為原理都是一樣的。
技術方案五:
考慮異步創建、消息隊列等等。這種方案無論從設計上還是開發上,難度都是有的。
技術方案一肯定是要被否掉的了,剩下的就是在技術方案二跟技術方案三之間做一個抉擇,鑒於公司目前的情況,技術方案四跟技術方案五就先不考慮了。
接下來,為了讓大家對表值參數的創建跟調用有更感性的認識,我將寫的更詳細些,文章可能也會稍長些,不關注細節的朋友們可以選擇跳躍式的閱讀方式。
再說一下測試方案吧,測試總共分三組,一組是插入數量小於1000的,另外兩組是插入數據量大於1000的(這裡我們分別取10000跟1000000),每組測試又分10次,取平均值。怎麼做都明白了,Let’s go!
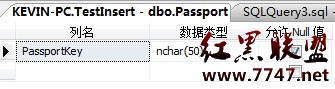
1.創建表。
為了簡單,表中只有一個字段,如下圖所示:
2.創建表值參數類型
我們打開查詢分析器,然後在查詢分析器中執行下列代碼:
Create Type PassportTableType as Table ( PassportKey nvarchar(50)
)
執行成功以後,我們打開企業管理器,按順序依次展開下列節點--數據庫、展開可編程性、類型、用戶自定義表類型,就可以看到我們創建好的表值類型了如下圖所示:
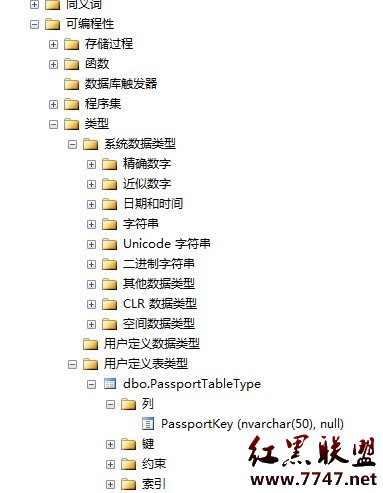
說明我們創建表值類型成功了。
3.編寫存儲過程
存儲過程的代碼為:
USE [TestInsert]
GO /****** Object: StoredProcedure [dbo].[CreatePassportWithTVP] Script Date: 03/02/2010 00:14:45 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO -- ============================================= -- Author: <Kevin> -- Create date: <2010-3-1> -- Description: <創建通行證> -- ============================================= Create PROCEDURE [dbo].[CreatePassportWithTVP]
@TVP PassportTableType readonly
AS BEGIN SET NOCOUNT ON;
Insert asp?so=RECCNT&siteid=us%2Fdev&p=1&nq=NEW&qu=into&IntlSearch=&boolean=PHRASE&ig=01