我們在做采集軟件的時候
有些網站通過直接分析html文本是很麻煩的事情
在利用WinForm編程的情況下
有一種更好的方式當然是分析HtmlDocument
然而,這HtmlDoucment並不能直接創建
它必須由 WebBroswer控件Navigate生成一個頁面後
才能取得wb.HtmlDocument
然後就可以對HtmlDocument的各元素、標簽進行分析。
事實上,在采集的時候
並不是采集只會采集單個頁面
這樣的話,在主窗體中就可以完成
譬如采集一些列表頁面,有N多個頁
那麼,一個循環下去,
用WebBrowser去響應,那就會導致假死
這時候,我們肯定會想到用多線程去做這件事情
C#的多線程,
大家應該都知道,有STA,MTA兩種模式
然而,WebBrowser控件卻有一個不好的特點
那就是:它只支持多線程STA模式
例如下面的代碼,
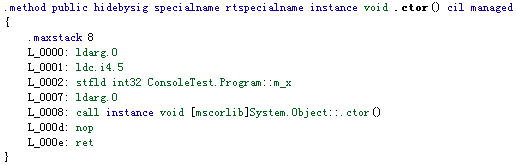
Thread tread = new Thread(new ParameterizedThreadStart(BeginCatch));

 代碼
private void BeginCatch(object obj)
代碼
private void BeginCatch(object obj)
需要分析WebBrowser產生 的HtmlDocument時,必須在事件DocumentCompleted裡面去操作
只有這時候,WebBrowser才算加載完成
不過,這只是一個陷阱!!!!
WebBrowser有一個特性,那就是在多線程STA的時候,根本就不等到DocumentCompleted的執行
也就是無法再進行後面的操作!!!
這樣的話,我們該如何辦呢?
也許有人會想:wb.Document.Write(string)方法,如下:
代碼
private void BeginCatch(object obj)