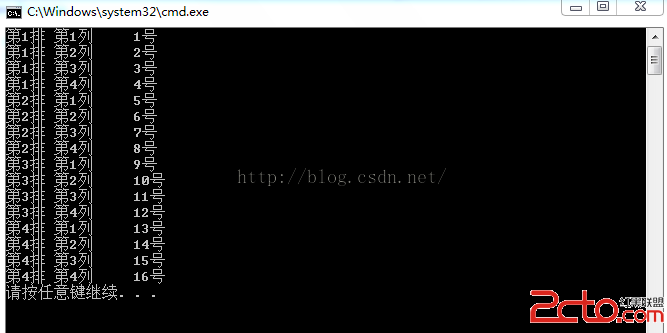
本文實現:
1、以犧牲空間為代價,方便快速地實現漢字的助記碼獲取。
2、針對拼音特性,實現多音字並提供顯式地姓氏調用方法。
網上關於使用C#取助記碼的方法很多,不過一般都是采用將每一個碼有哪些漢字的方法來實現助記碼的轉換,它的缺點是顯而易見的:
1.相當於本來應該存放在數據庫或者是外部的數據存放到程序中;
2.利用字符串的定位功能,性能上也不一定好。
在線性表中我們查找指定位置結點的數據是最快的,比如一個包含10000個元素的線性表中,無論直接訪問哪一個位置的數據值,只要根據表的第一個位置就可以直接定位到第9000個元素的位置,數組也是一種簡單有效的線性表,需要某個項目,只要通過編移量即可搞定。
在不使用數據庫,直接使用文件做資源,方便配置,完成中文到助記碼的的轉換,同時針對拼音助記碼,還要實現:1.多音字詞組匹配;2.姓氏專用方法。
同時五筆碼、四角碼等多種類別也易如反掌。雖然在以犧牲空間為代價,但用空間換得時間的性能提高,還是非常值得的。
數組就是一種線性表,我們的解決思路是:
1、 每一個項目對應一個結構,它包括漢字、拼音碼、是否多音字、五筆碼(或其它更多編碼);
2、 每一個漢字直接轉換成一個數字編碼(ASCII或者是UNICODE),數字就是數組下標;
3、 讀取文字串,根據每一個漢字取得數字,直接定位數組中的位置,取得編碼。
因此我們定義用於存放漢字的助記簡碼的結構(有更多編碼,只要在結構上擴充即可):
private struct ItemWord{
public int numFlag; //是否多音字
public char strWord;//當前單詞
public string strSpell1;//輸入碼
public string strSpell2;//輸入碼
public string strExt; //多音字保留串
public string strName;//用於定義姓氏碼
由於要支持拼音及多音字,也支持五筆的助記碼,為了例子方便,編碼表都暫時存放在d:myword下,下面以拼音碼的加載為例,首先初始化Itemword中的每一個項目,通常情況下GBK的實際漢字數應該在20000字左右,從雙字節的角度來看,最多也就只有64K,因此把我們的數組定義為64K,即:
private static readonly int INTMAX = 65536;
private ItemWord[] stWord = new ItemWord[INTMAX];
在函數fun_LoadWord中拼音碼hzpy1.txt的加載方法:
while ((strInput = srFile.ReadLine()) != null){
chrWord = strInput.ToCharArray();
numIndex = (int)chrWord[0];
stWord[numIndex].strWord = chrWord[0];
stWord[numIndex].strSpell1 = chrWord[2].ToString();
注意,其中最最關鍵是把讀取的內容轉成char的數組,再通過(int)chrWord[0]把它轉換為一個數組的下標值(這個相對來說C就簡單許多),再把相應內容填到數組中此下標項目。對於五筆碼的讀取方法也一致,非常簡單(更多的其它編碼也不在話下)。不過,拼音碼的多音存儲,需要介紹一下,實際上對於漢字來說,單音是大多數,只有少部分才是多音字,為了結構更簡單,把多音字是存放在相應的漢字結構中,即:
numIndex = (int)chrWord[0];
strInput = strInput.Substring(2);
strInput = strInput.Replace(" ", " ");
strInput = strInput.Replace(" ", "/");
stWord[numIndex].strExt = stWord[numIndex].strExt + strInput + "|";
最終strExt中的結構內容是“|曾哥/Z|”的格式,它的好處會在多音碼的展現時進行說明。
我們先舉例五筆的助記碼實現,對傳入的漢字串來說,只要提取每一個漢字,得到對應的字符編碼,再直接提取其對應編碼,由於直接采用下標取得編碼,而數據又加載在內存數組中,可以用飛速來描述它:
chrWord = strChinese.ToCharArray();
numCount = strChinese.Length;
for (i = 0; i < numCount; i++){
numIndex = (int)chrWord[i];
strSpell = strSpell + stWord[numIndex].strSpell2.ToString();
拼音碼,則存在著幾個主要問題,一個是姓氏,還有一個是多音字,多音字的實現,通過詞組模式來處理,即首先它是一個多音字,即結構中的numFlag標志。同時根據漢字串往前往後追蹤一個形成詞組,例如“曾哥”,它雖然來源於姓氏,但是本身已經形成一個受眾很廣的詞,在hzpy2.txt中定義“曾 曾哥 Z”這樣一行內容。在多音字時,我們用函數funFindMulti來定位多音字的編碼:
strWord = "|" + ch1 + ch2 + "/";
numPos = stWord[numIndex].strExt.IndexOf(strWord);
if (numPos >= 0) return stWord[numIndex].strExt.Substring(numPos + strWord.Length, 1);
也就是說,但我們定位漢字“曾”時,首先它是一個多音字,再根據詞組“曾哥”對應的編碼,
![clip_image001[4]](https://www.aspphp.online/bianchen/UploadFiles_4619/201701/2017012019301633.png "clip_image001[4]")
我們把用於定位的詞組形成前綴“|詞組/”的格式,假定有多個多音時,可以通過唯一位置定位後,再取得此串後面的字符,即“Z”,所以當我們輸入“信曾哥得自信”時,得到拼音助記碼自然就是“XZGDZX”了。因為姓氏的特殊性,並且實際業務中,比較明確地知道,當前的內容是否是姓名,即我們顯式調用,而姓名中,也只有在首字時才發生按姓的讀音。只要調用參數提供是否姓名的開關(下面的變量IsName,為了文章方便,緊湊格式了)即可:

 代碼
代碼
if (stWord[numIndex].numFlag > 0 && !IsName){
if (i > 0) strThis = funFindMulti(numIndex, chrWord[i - 1], chrWord[i]);
if (strThis.Length == 0 && i < numCount -1 ) strThis = funFindMulti(numIndex, chrWord[i], chrWord[i + 1]);
}
if (IsName && i == 0