最近在看貝葉斯算法,該算法在不少方面都有應用,已有的開發實例有:拼寫檢查、文本分類、垃圾郵件過濾、中文分詞等方面。根據需要,決定實現前面兩種,拼寫檢查已經實現,先貼於此。
程序效果圖:
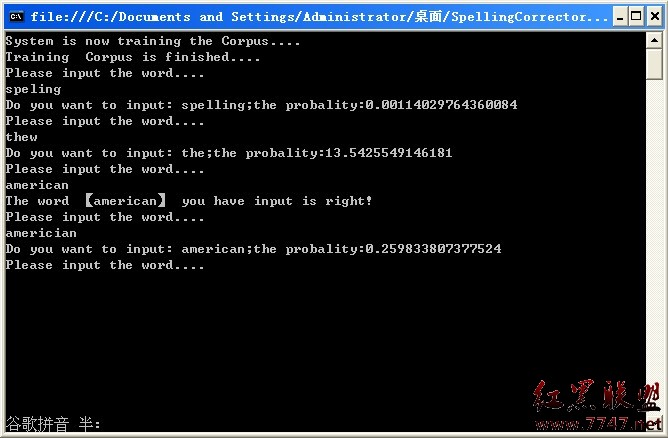
有關貝葉斯算法的學習和拼寫糾正方面請參照:原文這裡,徐宥的翻譯版這裡。
程序流程:
1.根據訓練語料統計訓練語料中每個單詞的出現次數、頻率,計算出p(h)先驗概率;訓練語料在此下載 big.txt,內含幾百萬單詞,可作為語料使用。
2.計算條件概率p(D|h),即假設(猜測)的單詞是我們輸入的單詞的概率大小,這裡使用了編輯距離的概念,簡化起見,計算了所有的編輯距離為1的可能編輯,其他請Google或參見這裡。
3.根據Bayes原理,後驗概率與每個輸入的生成概率p(D)無關,所以p(h|D)∝ P(h) * P(D | h),計算出最可能的拼寫。
說明:
1.對於語料中沒有出現的單詞,采用平滑處理1/N,N為訓練樣本中所有單詞的出現次數之和。
2.條件概率采用1/M,M為所有可能的單詞之和,如speling的每一個猜測單詞的條件概率1/290,290是編輯距離為1的所有可能的猜測。(也可以將26個字母表示為矩陣,求出每個字母在鍵盤上的距離,相信會更有說服力。俄羅斯有人在1973年做過這方面研究。)
3.訓練語料進性了簡單的預處理,統一轉換為小寫字母。
4.輸入exit可以退出程序。
關鍵代碼:
入口:

 代碼
static void Main(string[] args)
代碼
static void Main(string[] args)