首先大家需要清楚一點的是:任何網站的頁面,無論是php、jsp、aspx這些動態頁面還是用後台程序生成的靜態頁面都是可以在浏覽器中查看其HTML源文件的。
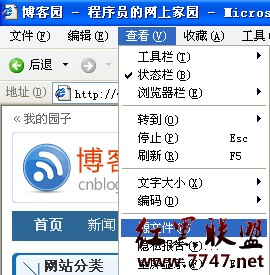
所以當你要開發數據采集程序的時候,你必須先對你試圖采集的網站的前台頁面結構(HTML)要有所了解。
當你對要采集數據的網站裡的HTML源文件內容十分熟悉之後,剩下程序上的事情就很好辦了。因為C#對Web站點進行數據采集其原理就在於“把你要采集的頁面HTML源文件下載下來,分析其中HTML代碼然後抓取你需要的數據,最後將這些數據保存到本地文件”。
基本流程如下圖所示:
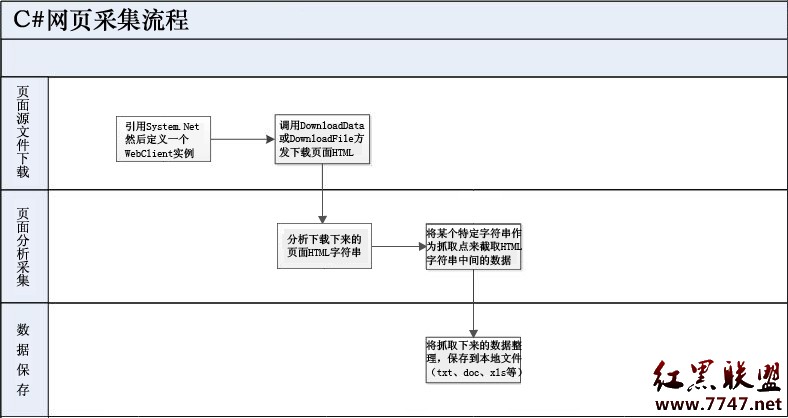
1.頁面源文件下載
首先引用System.Net命名空間
using System.Net;
此外還需引用
using System.Text;
using System.IO;
引用完後實例化一個WebClient對象
private WebClient wc = new WebClient();
調用DownloadData方法將指定網頁的源文件下載一組BYTE數據,然後將BYTE數組轉為字符串。
//下載頁面源文件並將其轉換成UTF8編碼格式的STRING
string mainData = Encoding.UTF8.GetString(wc.DownloadData(string.Format("你要采集的網頁地址")));
或則也可以調用DownloadFile方法,先將源文件下載到本地然後再讀取其字符串
//下載網頁源文件到本地
wc.DownloadFile("你要采集的網頁URL","保存源文件的本地文件路徑");
//讀取下載下來的源文件HTML格式的字符串
string mainData = File.ReadAllText("保存源文件的本地文件路徑",Encoding.UTF8);
有了網頁HTML格式字符串,就可以對網頁分析采集並抓取你所需要的內容了。
2.頁面分析采集
頁面分析就是要將網頁源文件中某個特定或是唯一的字符(串)作為抓取點,以這個抓取點作為開端來截取你想要的頁面上的數據。
以博客園為列,比方說我要采集博客園首頁上列出來的文章的標題和鏈接,就必須以"<a class="titlelnk" href=""作為抓取點,以此展開來抓取文章的標題和鏈接。

CODE:
//以"<a class="titlelnk" href=""作為抓取點開始采集
mainData=mainData.Substring(mainData.IndexOf("<a class="titlelnk" href="") + 26);
//獲取文章頁面的鏈接地址
string articleAddr = mainData.Substring(0,mainData.IndexOf("""));
//獲取文章標題
string articleTitle = mainData.Substring(mainData.IndexOf("target="_blank">") + 16,
mainData.IndexOf("</a>") - mainData.IndexOf("target="_blank">") - 16);
注意:當你要采集的網頁前台HTML格式變了之後,作為抓取點的字符竄也因做相應地改變,否則是采集不到任何東西的
3.數據保存
當你把需要的數據從網頁截取下來後,將數據在程序中稍加整理保存到本地文件(或插入到自己本地的數據庫中)。這樣整個采集工作就算搞一段落了。
//輸出數據到本地文件
File.AppendAllText(CreateFolderIfNot(Settings.Default.OutPath) + articleTitle + ".txt",
articleData,
Encoding.UTF8);
此外附上一個我自己寫的采集博客園首頁文章的小程序代碼,該程序的功能是可以將發布到博客園首頁上所有文章采集下來。
下載地址:CnBlogCollector.rar
當然如果博客園前台頁面格式調整了,那程序的采集功能肯定是無效的了,只能自己重新調整程序才能繼續采集,呵呵。。。
程序效果如下: