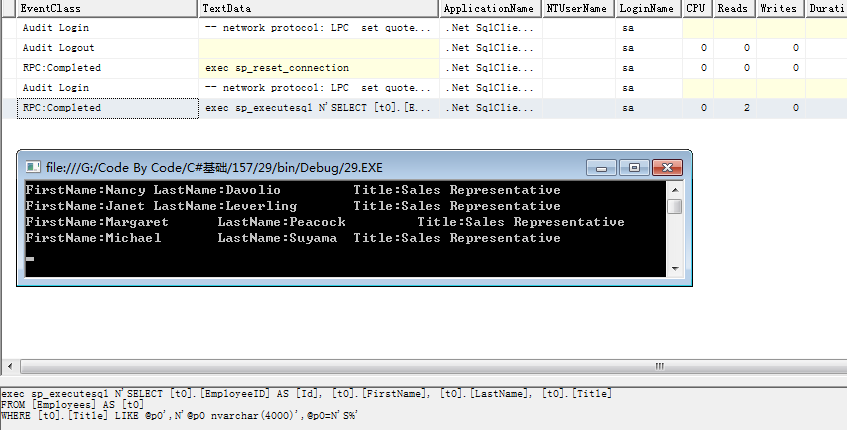
我們在做數據系統的時候,經常會用到模糊搜索,但是,數據庫提供的模糊搜索並不具備按照相關度進行排序的功能。
現在提供一個比較兩個字符串相似度的方法。
通過計算出兩個字符串的相似度,就可以通過Linq在內存中對數據進行排序和篩選,選出和目標字符串最相似的一個結果。
本次所用到的相似度計算公式是 相似度=Kq*q/(Kq*q+Kr*r+Ks*s) (Kq > 0 , Kr>=0,Ka>=0)
其中,q是字符串1和字符串2中都存在的單詞的總數,s是字符串1中存在,字符串2中不存在的單詞總數,r是字符串2中存在,字符串1中不存在的單詞總數. Kq,Kr和ka分別是q,r,s的權重,根據實際的計算情況,我們設Kq=2,Kr=Ks=1.
根據這個相似度計算公式,得出以下程序代碼:
/// <summary>
/// 獲取兩個字符串的相似度
/// </summary>
/// <param name=”sourceString”>第一個字符串</param>
/// <param name=”str”>第二個字符串</param>
/// <returns></returns>
public static decimal GetSimilarityWith(this string sourceString, string str)
{
decimal Kq = 2;
decimal Kr = 1;
decimal Ks = 1;
char[] ss = sourceString.ToCharArray();
char[] st = str.ToCharArray();
//獲取交集數量
int q = ss.Intersect(st).Count();
int s = ss.Length – q;
int r = st.Length – q;
return Kq * q / (Kq * q + Kr * r + Ks * s);
}
這就是計算字符串相似度的方法,但是實際應用時,還需要考慮到同義詞或近義詞的情況發生, 如“愛造人小說閱讀的更新最快”和“愛造人小說閱讀地更新最快” 。兩個字符串在一定意義上說其實是相同的,如果使用上述方法計算就會出現不准確的情況。所以在實際應用的時候,我們需要替換同義詞或近義詞,計算替換後的相似度。
如果是近義詞,需要綜合替換近義詞前和近義詞後的計算結果,得出兩個字符串的實際相似度。
摘自 kuibono