Lucene.net入門學習系列(1)-分詞
Lucene.net入門學習系列(2)-創建索引
Lucene.net入門學習系列(3)-全文檢索
這幾天在公司實習的時候閒的蛋疼,翻了一下以往的教程和博客,看到了Lucene.net。原本想學著寫一個系列的博文,由於本人水平有限,一直找不到適合的內容來寫,干脆就寫一個簡單的Lucene.net系列文章吧。希望和大家一起學習,一起進步,有什麼寫錯了或者有什麼建議歡迎提出來。
一.引言
先說一說什麼是Lucene.net。Lucene.net是Lucene的.net移植版本,是一個開源的全文檢索引擎開發包,即它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎。開發人員可以基於Lucene.net實現的功能。
說完了Lucene.net,接著來說什麼是全文檢索。全文檢索是一種將文件中所有文本與檢索項匹配的文字資料檢索方法。
二.分詞
前面的引言大概說了一下什麼是全文檢索,介紹了Lucene.net這個全文檢索引擎。
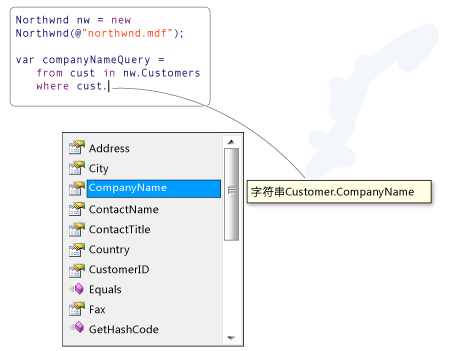
分詞就是將連續的字序列按照一定的規范重新組合成詞序列的過程。在英文的行文中,單詞之間是以空格作為自然分界符的,而中文只是字、句和段能通過明顯的分界符來簡單劃界,唯獨詞沒有一個形式上的分界符,雖然英文也同樣存在短語的劃分問題,不過在詞這一層上,中文比之英文要復雜的多、困難的多。不過,前輩們已經做了很多工作,我們只要拿來用就行了。在這裡,我們使用""。盤古分詞是一個基於.net 平台的開源中文分詞組件,提供lucene(.net 版本) 和HubbleDotNet的接口,采用字典和統計結合的分詞算法,分詞准確率較高。
說了那麼多的廢話,現在我們來看一看如何分詞。
我們要添加對3個程序集的引用: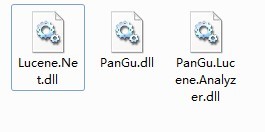
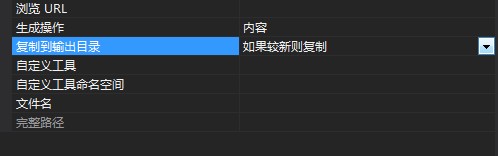
還要對字典進行設置:
1.將字典放到項目中(字典在本文末提供下載)
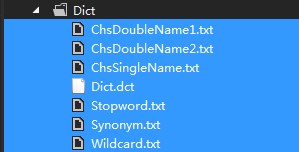
2.在屬性中設置:
上代碼
[] SplitWords(
List<> list = List<>
Analyzer analyzer =
TokenStream tokenStream = analyzer.TokenStream(,
((token = tokenStream.Next()) !=
}
Main( s1 = s2 =
( r SplitWords(s1) r).ToList().ForEach(a => Console.Write(a +
( r SplitWords(s2) r).ToList().ForEach(a => Console.Write(a +
}
測試結果:
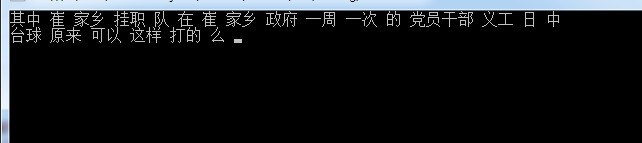
我們可以看到,分出來的效果還是比較令人滿意的。像"崔家鄉"這些地名詞,我們可以通過盤古分詞附帶的一個工具將詞語添加進去。
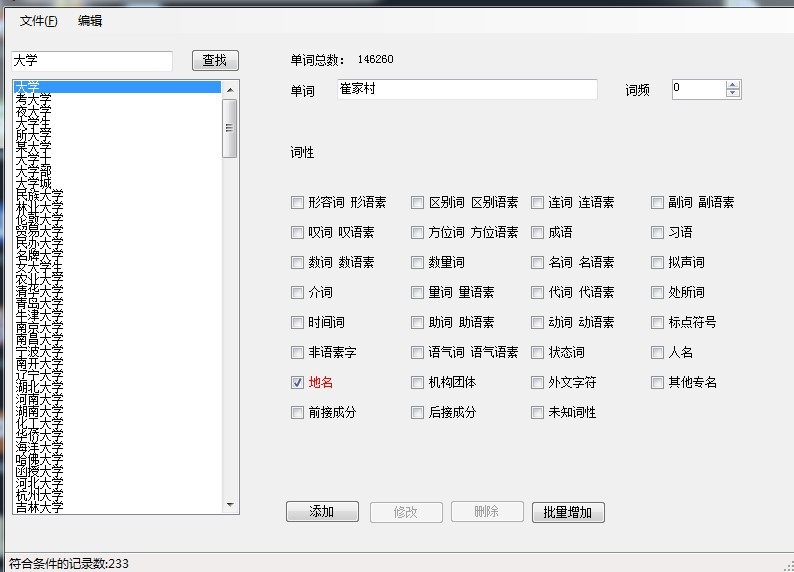
添加好詞語之後我們再來進行一次測試。

我們可以看到,盤古分詞已經"崔家鄉"這個詞當做一個詞來看待了。
Dll下載地址:http://files.cnblogs.com/g1mist/SplitWords-PanGu.zip
字典下載地址:http://files.cnblogs.com/g1mist/Dict.zip