接上一篇《C#基礎之類型和成員基礎以及常量、字段、屬性》
C#中的方法分為兩類,一種是屬於對象(類型的實例)的,稱之為實例方法,另一種是屬於類型的,稱之為靜態方法(用static關鍵字定義)。大家都是做開發的,這兩個也沒啥好說的。
唯一的建議就是:你的靜態方法最好是線程安全的(這點是說起容易做起難啊……)。
構造器是一種特殊的方法,CLR中的構造器分為兩種:一種是實例構造器;另一種是類型構造器。和其他方法不同,構造器不能被繼承,所以在構造器前應用virtual/new/override/sealed和abstract是沒有意義的,同時構造器也不能有返回值。
實例構造器用來初始化類型的實例(也就是對象)的初始狀態。
對於引用類型,如果我們沒有顯式定義實例構造器,C#編譯器默認會生成一個無參實例構造器,這個構造器什麼也不做,只是簡單調用一下父類的無參實例構造器。這裡應該意識到,如果我們定義的類的基類沒有定義無參構造器,那麼我們的派生類就必須顯式調用一個基類構造器。
MyBase(
上面的代碼會報“MyBase不包含采用0個參數的構造函數”的錯誤,必須顯式調用一個基類的構造器:
MyBase( MyClass( name) :
MyBase()
: ( MyBase( name)
: (name, MyBase( name, age)
除了實例構造器,C#語言還提供了一種初始化字段的簡便語法,稱為“內聯初始化”:
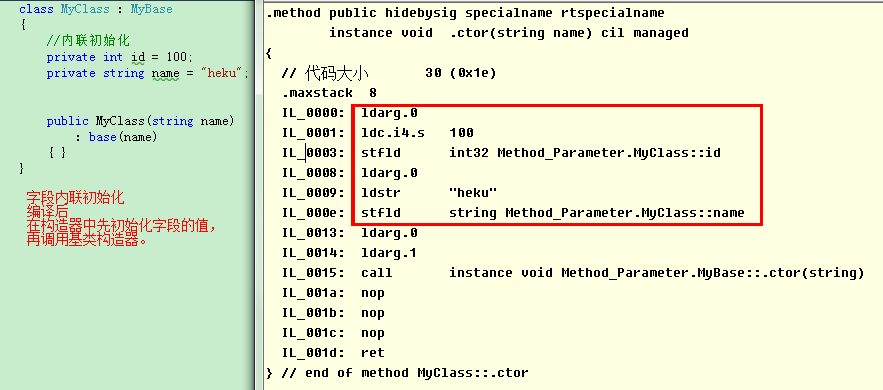
從編譯後生成的IL代碼可以看出,內聯初始化本質是在所有實例構造器中,生成一段字段初始化代碼的方式來實現的。注意這裡一個潛在的代碼膨脹問題,如果我們定義了多個實例構造器,那麼在每個實例構造器開頭處,都會生成這樣的初始化代碼。在有多個實例構造器的類型定義中,應盡量減少這種內聯初始化,可以通過創建一個構造器來初始化這些字段,然後讓其他構造器通過this關鍵字來調用這個構造器。
對於值類型,C#不會對值類型生成默認的無參構造器,但CLR總是允許值類型的實例化。即對於以下的值類型定義,雖然我們沒有定義任何構造器,C#也沒有為我們生成默認無參構造器,但它總是可以通過new實例化的(值類型的字段被初始化為0或null)。
= MyStruct();
MyStruct( a) =
MyStruct( a)
;
x =
類型構造器(靜態構造器)用來初始化類型的初始狀態,並且有且只能定義一個,且沒有參數。類型構造器總是私有的,C#會自動把它標記為private,事實上C#禁止開發人員對類型構造器應用任何訪問修飾符。
CLR在第一次使用一類型時,如果該類型定義了類型構造器,CLR便會以線程安全的方式調用它。這裡應該意識到對類型構造器的調用,由於CLR要做大量檢查與判斷和線程同步,所以性能上會有所損失。
類型構造器的通常用來初始化類型中的靜態字段,C#同樣提供了一種內聯初始化的語法:
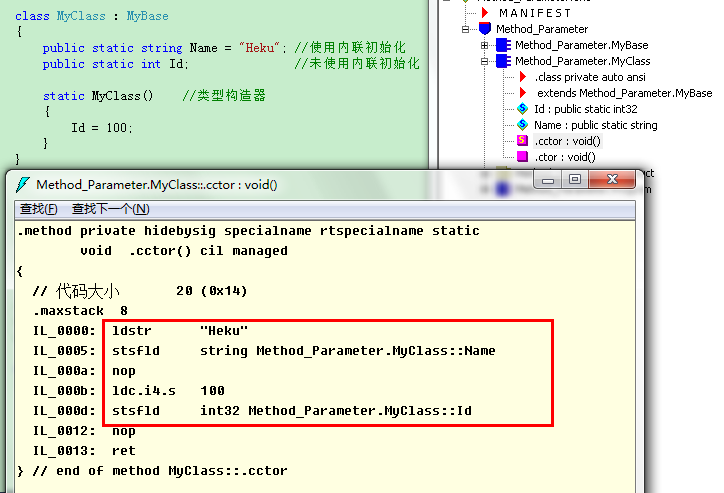
從編譯器生成的IL可知,靜態字段的內聯初始化實際上是在類型構造器生成初始化代碼完成的,而且首先生成的是內聯初始化代碼,然後才是類型構造器方法內部顯式包含的代碼。
雖然值類型能定義類型構造器,但永遠都不要那麼做。因為CLR有時不會調用值類型的類型構造器。
這兩個概念都是針對於類型的繼承層次結構中來說的,如果沒有了繼承,它們是毫無意義的。這也意味著它們的可訪問性至少是protected,即對派生類是可見的。
抽象方法是只定義了方法名稱、簽名和返回值類型,而沒有定義任何方法實現的一種方法。C#中用abstract定義,抽象方法所在的類肯定是抽象類。由於抽象方法沒有定義方法實現,所以它是沒有意義的,必須在派生類中提供方法的實現(如果派生類沒有提供,那麼它必須仍然定義成抽象類)。
Test0() {
Test1() {
Test3() {
在C#中用virtual定義的方法是虛方法,它看上去只是比定義一個普通實例方法多了一個virtual關鍵字。虛方法總是允許在派生類中重寫,但不強求,這正在它和抽象方法的區別。也可以邏輯上把虛方法想象成提供了默認實現的抽象方法,因為提供了默認實現,所以不強求派生類中重寫。
抽象方法編譯後被標記為abstract virtual instance(抽象虛實例方法),虛方法編譯後被標記為virtual instance(虛實例方法)。
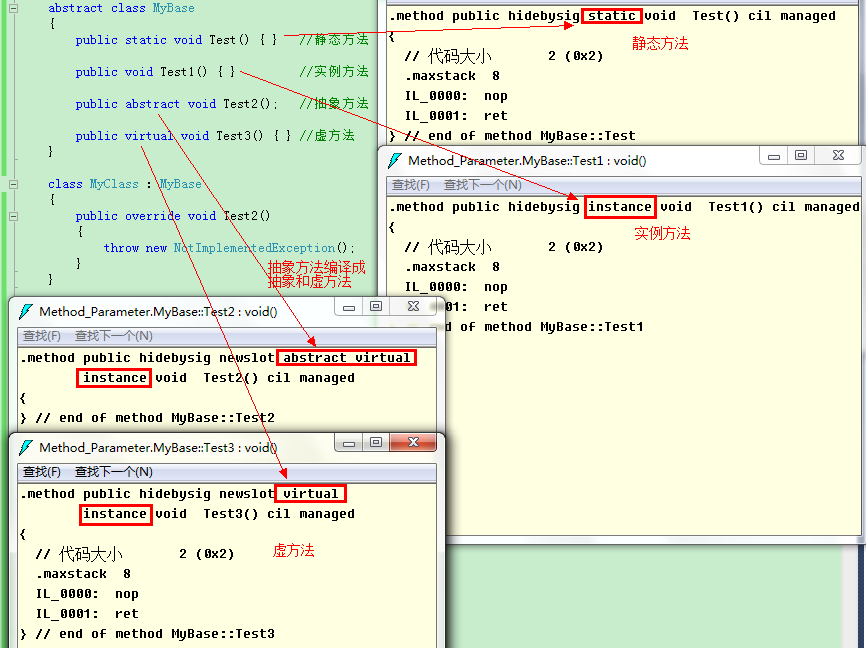
抽象方法和虛方法共同的特點都是可以在派生類中重寫,在C#中用override關鍵字來重寫一個方法。在VS中,如果我們在類中輸入override關鍵字加空格,便會顯示出所有基類中的虛成員(方法、屬性、事件等)。因為抽象方法編譯後是抽象和虛的,所以也會顯示在列表中。

重寫後的方法仍然是virtual的(但不再是抽象的)
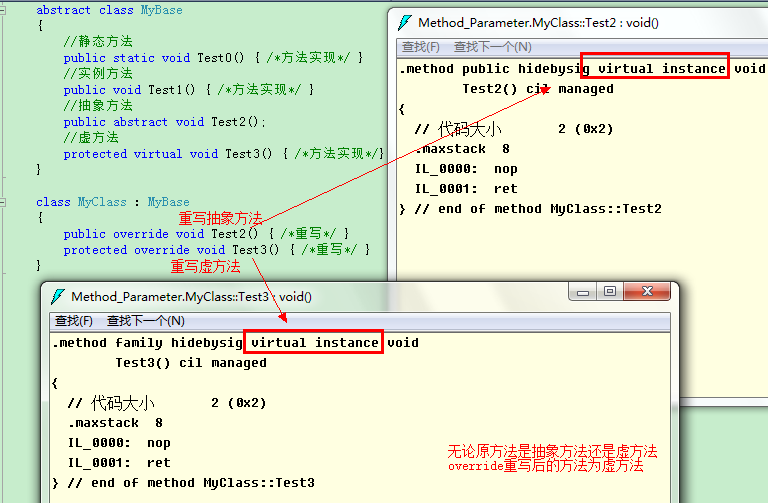
virtual方法是可以被派生類重寫的,如果不希望重寫後的方法被接下來的派生類(即派生自MyClass的類)重寫,可以在override前應用sealed關鍵字,將方法標記為封閉的。
如下圖中,我將MyClass中的Test3標記為sealed後,MyClass的派生類中,VS列出的可重寫的成員中便沒有Test3了。

當然,還可以對類應用sealed關鍵字,這樣整個類都不能被繼承了!類都不能被繼承了,類裡包含的所有虛方法更不談重寫了。
主要是partial關鍵字(也可以應用於類、結構和接口),可以將一個方法定義到多個文件中。
通常有這麼一種場情:我們往往利用代碼生成工具生成一些模板化的代碼,但又需要對某些細節進行定制,雖然可以通過虛方法重寫來實現,但這樣做存在兩點問題:
這時候,就可以利用分部方法來實現。讓代碼生成器生成一個分部類(注意這個類可以是密封的),把實現細節抽象成一個方法定義。像下面這樣:
PrepareSomething( boy,
PrepareSomething(,
如果我們沒有提供分部方法的實現,那麼編譯後,整個方法的定義和所有對此方法的調用都會被優化(刪除)掉,這樣可以讓代碼更少更快!也正因為這一點(編譯後分部方法可能不存在),所以分部方法不能定義任何修改符,也不能定義返回值!
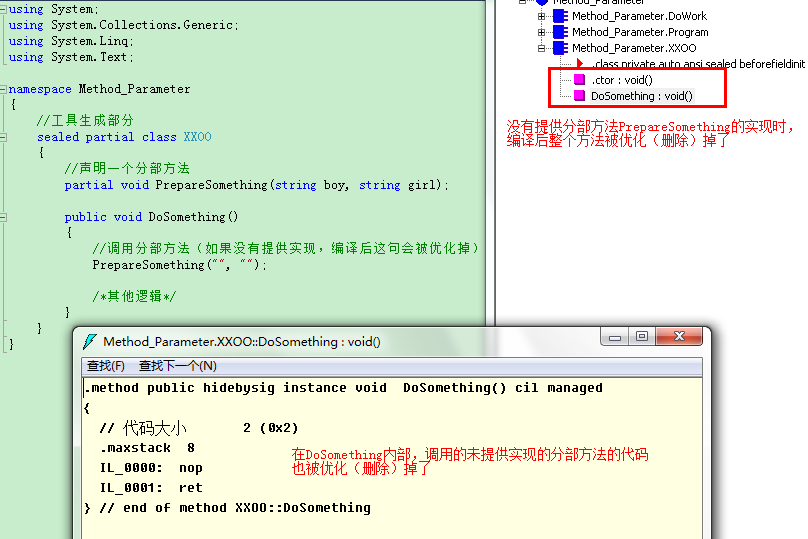
當然用分部方法主要還是為了提供實現細節,我們甚至可以在不同的文件中來定義這個類(在VS中輸入partial加空格,便會列出當前分部類中的還未提供實現的分部方法):
PrepareSomething( boy,
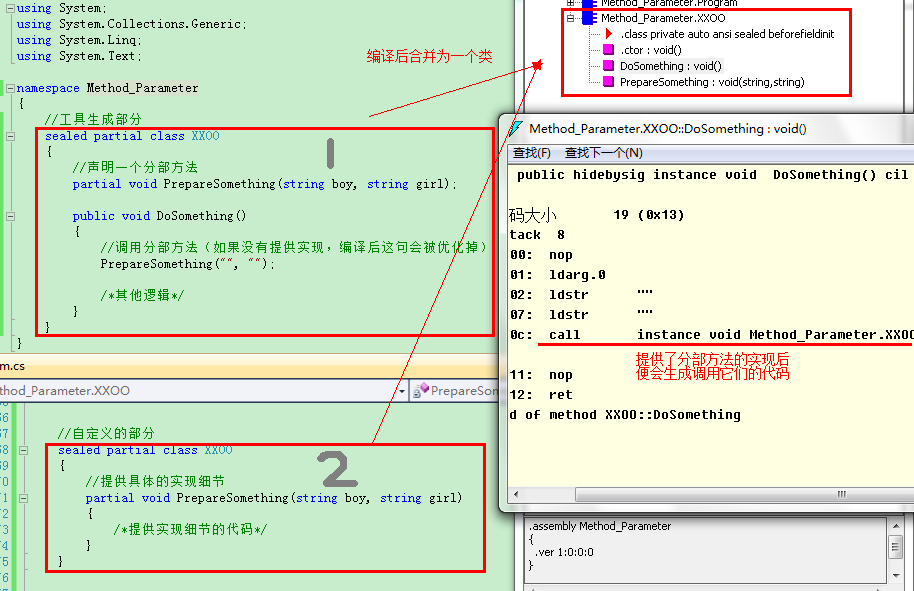
關於分部方法有幾點要小注意一下:
這兩個方法涉及CLR的垃圾回收部分,這裡只是從方法層面上談談這兩個方法。我們知道,C#是托管語言,我們寫的程序最終托管給CLR,CLR有強大的自動垃圾回收機制來幫助我們回收內存資源。但注意CLR自動回收的僅是內存資源,有些類除了要利用內存資源外,還需要利用一些其他的系統資源(比如文件、網絡連接、套接字、互斥體等),所以CLR提供了一種機制來釋放這些資源,這便是Finalize方法(終結器)。
這裡的Finalilze方法並不是指直接在類中定義一個Finalize方法(雖然可以定義,但永遠不要這麼做!),而是指用析構語法來定義的一種方法,即“~類名()”的方式定義的方法,該方法編譯後,會生成名為Finalize的方法。CLR會在決定回收包含Finalize方法的對象之前用一個特殊的線程調用Finalize方法來釋放一些資源(這個具體的過程待日後寫到CLR垃圾回收部分慢慢聊)。
下圖簡單演示了一下如何定義一個終結器,我們用定義析構函數的語法來定義了一個方法(注意這個方法沒有參數和任何修飾符),編譯後,編譯器為我們生成一個名為Finalize的protected virtual方法。且在方法內部生成一個try塊包裝原方法內的代碼,生成一個finally塊來調用基類的Finalize方法。
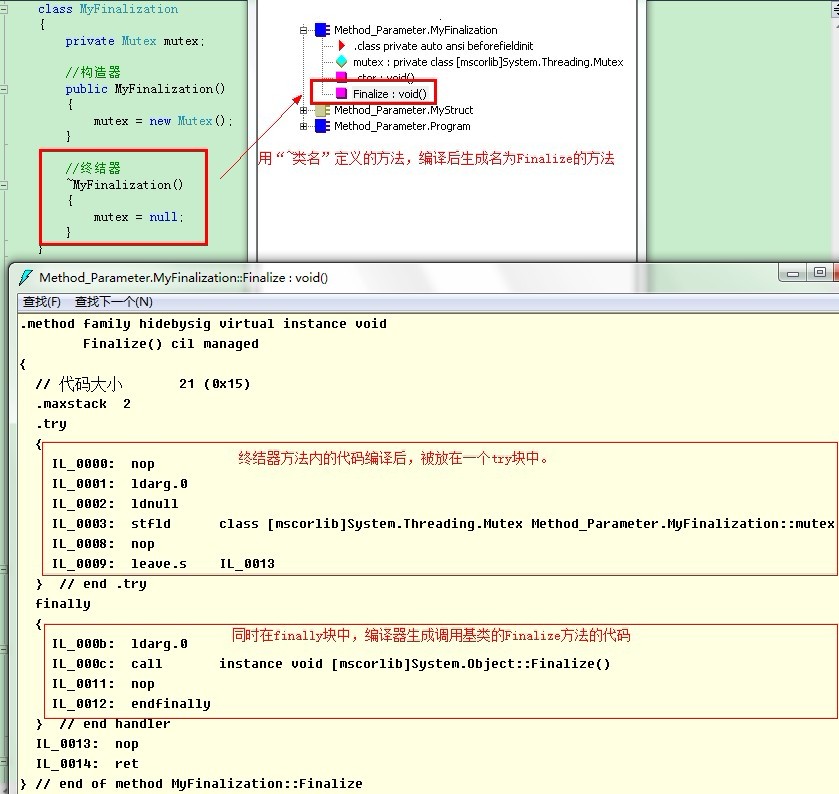
雖然定義Finalize方法的語法和C++的析構函數語法一樣,但CLR書上說兩者原理還是完全不同,所以不能稱為析構器(我的理解C++中的析構函數應該是釋放對象所用的資源包括內存資源,調用後對象便被清理干淨了;而C#中的Finalize方法只是釋放對象所用的系統資源,調用後對象仍然存活,直到CLR將其回收,不知道這麼理解對不對啊,請指點!)。
雖然Finalize方法很有用,能確釋放一些資源。但有一點要注意,就是它的調用是由CLR決定的,所以調用時間我們無法保證。所以我們需要一種機制來顯式地釋放資源,這便是Dispose模式。.Net裡提供了IDisposable接口(包含唯一一個Dispose方法),我們只要實現該接口即代表我們的類實現了Dispose模式。在Dispose方法內部,我們關閉對象所用到的系統資源。這樣我們在代碼中,就可以顯式調用Dispose方法來釋放資源,而不是被動地交給CLR去釋放,《CLR Via C#》書中建議所有實現終結器的類都同時實現Dispose模式。如下面的類,實現終結器的同時還實現Dispose模式(先不管實現細節是否合理):
=
~MyFinalization()
{
mutex =
Dispose()
{
mutex =
這樣在我們使用完MyResource對象後,就可以通過調用Dispose方法釋放資源。
MyResource resource =
resource.Dispose();
對於實現Dispose模式的類型,C#還提供了using語句來簡化我們的編碼。
(MyResource resource =
}
MyResource resource =
(resource !=
擴展方法使我們能夠向現有類型“添加”方法,而無需創建新的派生類型、重新編譯或以其他方式修改原始類型。 擴展方法是一種特殊的靜態方法,但可以像被擴展類型上的實例方法一樣進行調用,同時它可以得到VS智能提示的良好支持(我們可以像使用對象實例方法一樣,點出擴展方法)。
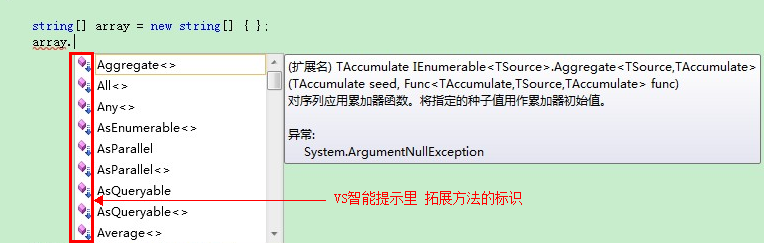
定義一個擴展方法,有以下幾點要求:
ExtensionMethods IsNullOrEmpty( s)
name =
name.IsNullOrEmpty();
關於擴展方法,還有以下幾點要注意:
擴展方法延伸閱讀:鶴沖天 http://www.cnblogs.com/ldp615/archive/2009/08/07/1541404.html
傳遞參數就是賦值操作,我們可以把方法參數看成方法定義的一些變量,傳參就是對這些變量進行賦值的過程。賦值過程就是拷貝線程棧內容的過程,值類型的棧內容保存的就是值實例本身,而引用類型棧內容保存的是引用實例在堆上的地址。所以這裡的區別主要是值類型與引用類型內存分配上的區別,具體可參考《C#基礎之基本類型》。所以在傳參後,方法的值類型參數擁有原始值的復制(一個副本),對其的更改不影響原始值,因為它們根本就不是一塊內存!方法的引用類型參數擁有與原始值相同的地址,它們指向同一塊堆內存,所以對引用類型參數的更改會影響原始值。如下示例,分別定義了一個值類型val和引用類型refObj,在調用Work方法後,值類型val未被修改,引用類型refObj被修改了。
Main(= val = = RefType { Id = , Name =
Id { ; Name { ;
Work(++++= b.Name +
我們定義一個有很多參數的方法後,那麼所有調用處都要准備好這些參數才能調用此方法。但往往有些時候,我們調用時只關心其中的部分參數,通常我們是通過重載來定義幾個參數比較少的方法,內部補全其他參數再調用參數最多的那個方法。但這是純體力活,而且也不能重載出所有可能的參數組合情況。因此C#提供一種機制,可以在定義方法的同時,給參數指定默認值,這樣在方法調用處,如果沒有給參數提供值,就會采用默認值,擁有默認值的參數就稱為可選參數。
ToUpperOrLower( message, isToUpper = , other = (isToUpper)
result = dw.ToUpperOrLower();
參數名:參數值”的語法給參數提供值,這種語法的作用是要求參數的匹配方式不要按參數順序,而是根據提供的名稱。像下面這樣(沒有用命名參數語法的參數還是按參數順序匹配,如第一個參數”Heku”):
result = dw.ToUpperOrLower(, other: );