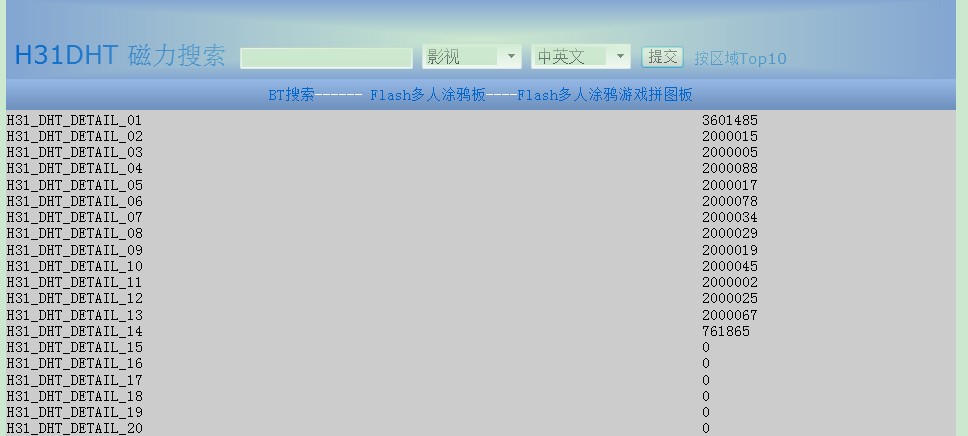
謝謝園子朋友的支持,已經找到個VPS進行測試,國外的服務器: http://h31bt.com 大家可以給提點意見...
服務器在抓取和處理同時進行,所以訪問速度慢是有些的,特別是搜索速度通過SQL的like來查詢慢,正在通過分詞改進中。。
DHT抓取程序開源地址:https://github.com/h31h31/H31DHTDEMO
數據處理程序開源地址:https://github.com/h31h31/H31DHTMgr
-----------------------------------------------------
目前在數據庫數量從量的增加到100多萬條數據時,數據庫的查詢插入就會面臨著比較慢的問題,下面就個人在整個設計過程中的方法與大家交流學習下。
個人目前采用的方法有:
由於中間調試程序,導致第一個表數據插入過多。
看來每個國家的前10名下載工作。



5.當程序有些錯誤的時候,數據庫有些字段設計錯誤,必須將程序全部重新跑一次的時候,跑了10幾天數據量需要快速來處理,如何解決速度問題,就需要考慮了,主要采用的方法還是白名單的方式,將已經處理過的正確的HASH字段存儲到一個表中,然後程序多線程重新處理,1天就可以差不多跑完10天的數據量。
Bloom Filter是由Bloom在1970年提出的一種多哈希函數映射的快速查找算法。通常應用在一些需要快速判斷某個元素是否屬於集合,但是並不嚴格要求100%正確的場合。
12. 用HashSet將訪問過的URL保存起來。那只需接近O(134
Bloom Filter的算法
111,str),h(2,str)…… h(k,str)。然後將BitSet的第h(1,str)、h(221,str),h(2,str)…… h(k,str)。然後檢查BitSet的第h(1,str)、h(2
-------------------------------
有了基本的思路後,我們采用了8個HASH生成函數來減少沖突概率,現提供代碼類:

此類有保存到文件和從文件中加載數據的功能,方便程序退出保存黑名單。
此類存儲了200000000條數據,占用內存在20M左右,使用後就減少從數據庫查詢工作,從而讓網站的查詢速度也快些。
以20M的內存來代替SQL數據庫的查詢工作還是值得的,雖然兩都都很花費CPU,但內存的比對肯定比數據庫快。
希望大家多多推薦哦...大家的推薦才是下一篇介紹的動力...