若何處理hash抵觸。本站提示廣大學習愛好者:(若何處理hash抵觸)文章只能為提供參考,不一定能成為您想要的結果。以下是若何處理hash抵觸正文
1)抵觸是若何發生的?
上文中談到,哈希函數是指若何對症結字停止編址的規矩,這裡的症結字的規模很廣,可視為無窮集,若何包管無窮集的原數據在編址的時刻不會湧現反復呢?規矩自己沒法完成這個目標。舉一個例子,依然用班級同窗做比方,現有以下同窗數據
張三,李四,王五,趙剛,吳露.....
假設我們編址規矩為取姓氏中姓的開首字母在字母表的絕對地位作為地址,則會發生以下的哈希表
地位 字母 姓名 0 a 1 b 2 c
...
10 L 李四
...
22 W 王五,吳露 .. 25 Z 張三,趙剛
我們留意到,灰色配景標示的兩行外面,症結字王五,吳露被編到了統一個地位,症結字張三,趙剛也被編到了統一個地位。先生再拿號來找張三,坐位上有兩小我,"你們倆誰是張三?"
2)若何處理抵觸成績
既然不克不及防止抵觸,那末若何處理抵觸呢,明顯須要附加的步調。經由過程這些步調,以制訂更多的規矩來治理症結字聚集,平日的方法有:
a)開放地址法
開放地法律有一個公式:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
個中,m為哈希表的表長。di 是發生抵觸的時刻的增量序列。假如di值能夠為1,2,3,...m-1,稱線性探測再散列。
假如di取1,則每次抵觸以後,向後挪動1個地位.假如di取值能夠為1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
稱二次探測再散列。假如di取值能夠為偽隨機數列。稱偽隨機探測再散列。依然以先生排號作為例子,
現有兩名同窗,李四,吳用。李四與吳用事前已排好序,現新來一位同窗,名字叫王五,對它停止編制
10..
....
22
..
..
25
李四..
....
吳用
..
..
25
趙剛將來之前
10..
..
22
23
25
李四..
吳用
王五
(a)線性探測再散列對趙剛停止編址,且di=1
10...
20
22
..
25
李四..
王五
吳用
(b)二次探測再散列,且di=-2
1...
10...
22
..
25
王五..
李四..
吳用
(c)偽隨機探測再散列,偽隨機序列為:5,3,2
b)再哈希法
當產生抵觸時,應用第二個、第三個、哈希函數盤算地址,直到無抵觸時。缺陷:盤算時光增長。
好比下面第一次依照姓首字母停止哈希,假如發生抵觸可以依照姓字母首字母第二位停止哈希,再抵觸,第三位,直到不抵觸為止
c)鏈地址法
將一切症結字為同義詞的記載存儲在統一線性鏈表中。以下:
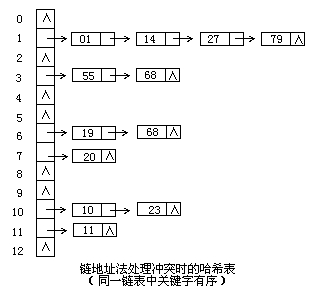
是以這類辦法,可以近似的以為是筒子外面套筒子
d)樹立一個公共溢出區
假定哈希函數的值域為[0,m-1],則設向量HashTable[0..m-1]為根本表,別的設立存儲空間向量OverTable[0..v]用以存儲產生抵觸的記載。
經由以上辦法,根本可以處理失落hash算法抵觸的成績。
注:之所以會簡略得引見了hash,是為了更好的進修lzw算法,進修lzw算法是為了更好的研討gif文件構造,最初,我將具體的論述一下gif文件是若何組成的,若何高效操作此品種型文件。
以上就是本文的全體內容,願望能給年夜家一個參考,也願望年夜家多多支撐。