前一陣做了個編譯器(僅詞法分析、語法分析、部分語義分析,所以說是前端),拿來分享一下,如有錯 誤,歡迎批評指教!
整個代碼庫具有如下功能:
提供編譯器所需基礎數據結構、計算流程框架 類,可供繼承使用;
提供基礎數據結構的可視化控件;
提供類似YACC的詞法分析器、語法分析 器自動生成功能;
提供Winform程序,集成和擴展上述功能,方便研究和應用。
本文及其後續 系列將逐步給出所有工程源代碼(visual studio 2010版本)。
上圖展示一下先。
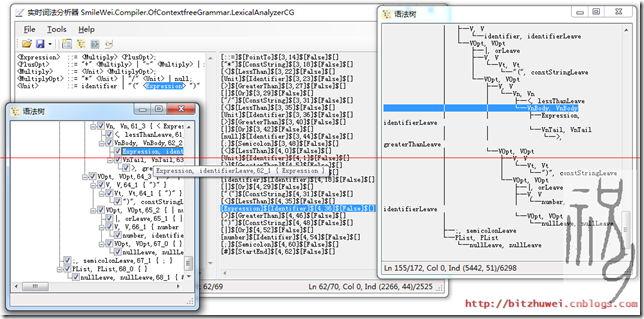
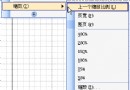
圖1 詞法、語法分析和結點匹配
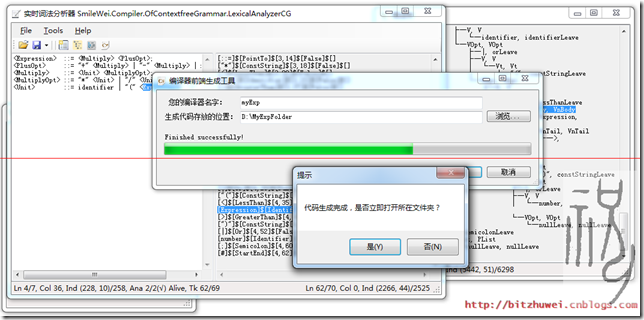
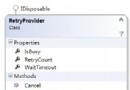
圖2 自動生成詞法分析器、語法分析器
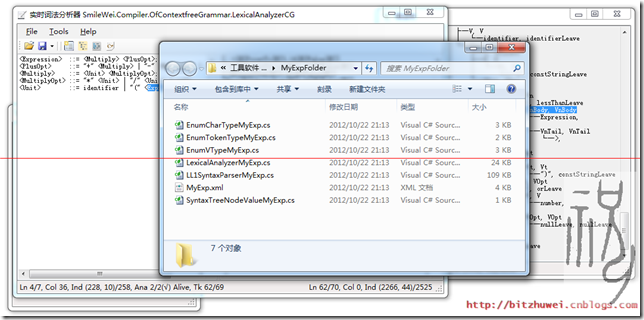
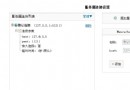
圖3 自動生成詞法分析器、語法分析器
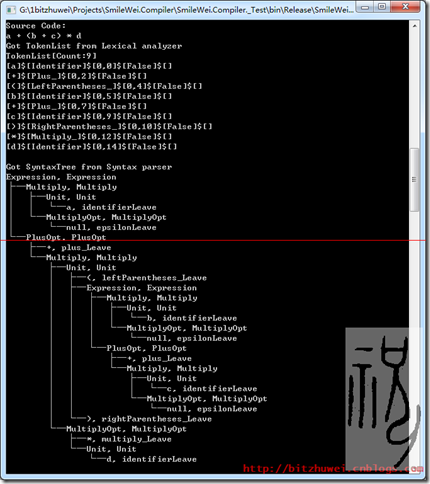
圖4 自動打印語法樹
為 了說清楚編譯器這種東西,我想最好還是舉例。
比如我們要為數學計算的表達式(Expression)設計 一個編譯器。(當然有很多方法可以實現讀取數學表達式並計算結果的算法,未必使用編譯原理)
來 看一些數學表達式的例子:
37
19 * 19 - 18 * 18
(19 + 18) * (19 - 18)
18 +19 / (18 / 18)
a + (a + 1) + (a + 2) + (a + 3)
好了夠了,大家能夠了解本文所討 論的Expression的范圍了。那麼我們引入“文法”(Grammar)的概念。Expression的文法就是這樣的:
<Expression> ::= <Multiply> <PlusOpt>;
<PlusOpt> ::= "+" <Multiply> | "-" <Multiply> | null;
<Multiply> ::= <Unit> <MultiplyOpt>;
<MultiplyOpt> ::= "*" <Unit> | "/" <Unit> | null;
<Unit> ::= identifier | "(" <Expression> ")" | number;
我們分別展示出上述幾個例子用文法展開的過程。
37: <Expression>
=> <Multiply> <PlusOpt>
=> <Unit> <MultiplyOpt>
=> number
19 * 19 - 18 * 18: <Expression>
=> <Multiply> <PlusOpt>
=> <Unit> <MultiplyOPt> "-" <Multiply>
=> number "*" <Unit> "-" <Unit> <MultiplyOpt>
=> number "*" number "-" number "*" <Unit>
=> number "*" number "-" number "*" number
(19 + 18) * (19 - 18): <Expression>
=> <Multiply> <PlusOpt>
=> <Unit> <MultiplyOpt>
=> "(" <Expression> ")" "*" <Unit>
=> " (" <Multiply> <PlusOpt> ")" "*" "(" <Expression> ")"
=> "(" <Unit> <MultiplyOpt> "+" <Multiply> ")" "*" "(" <Multiply> <PlusOpt> ")"
=> "(" number "+" <Unit> <MultiplyOpt> ")" "*" "(" <Unit> <MultiplyOpt> "-" <Multiply> ")"
=> "(" number "+" number ")" "*" "(" number "-" number <MultiplyOpt> ")"
=> "(" number "+" number ")" "*" "(" number "-" number ")"
寫到這裡就,其余例子大家自己試試~ 如果寫不出來,後面的部分可能就不太容易看了。(試試寫寫,很快就寫的比較熟練了)
總結一下“ 文法”(Grammar)。文法就是描述Expression的構成的,和英語的語法類似吧。 有了文法,我們就可以寫編 譯器了。
Expression的文法有5個式子,這5個式子就叫做“產生式”(Production),因為他們能從 左邊的結構產生(推導)出右邊的結構來。一個文法至少有一個產生式,第一個產生式的左邊的結點是初始結 點,所有的推導都必須從初始結點(即第一個產生式)開始。
產生式(Production)左邊叫做左部( 左部只有始終一個結點),右邊叫做右部(廢話),中間用【::=】這個符號隔開。
右部由符號【|】 分為若干部分,每一部分都是產生式可能推導出的一個結果,且每次只能選擇其中一個進行推導。【null】表 示什麼也不推導出來。(這是個霸氣的符號,不要覺得什麼都不推導出來就不重要,恰恰相反,這個符號很重 要)
為簡化後文的說明,繼續舉例:<PlusOpt> ::= "+" <Multiply> | "-" <Multiply> | null;
對於這個產生式,其實是由三部分<PlusOpt> ::= "+" <Multiply>;和<PlusOpt> ::= "-" <Multiply>和 <PlusOpt> ::= null;組成的,每一部分都稱為一個“推導式”(Derivation)。
像【(19 + 18) * (19 - 18)】這樣一個具體的“東西”,我們稱之為一個“句子”(Sentence)。
明了了上述關 於文法的東西,就可以進行編譯器的設計了。
我們先搞搞清楚,編譯器能做什麼?以Expression的【 19 * 19 - 18 * 18】為例,Expression的編譯器首先要讀取字符串格式的源代碼,即:
1 var sentence = “19 * 19 - 18 * 18”;
2 var expLexicalAnalyzer = new LexicalAnalyzerExpression ();
3 expLexicalAnalyzer.SetSourceCode(sentence);
然後,編譯器進行詞法分析,得到單詞 流(TokenList)。“流”這個東西,其實就是數組。
1 var tokens = expLexicalAnalyzer.Analyze ();
在此例中,得到的單詞流是這樣的:
[19]$[Number]$[0,0]$[False]$[]
[*] $[Multiply]$[0,3]$[False]$[]
[19]$[Number]$[0,5]$[False]$[]
[-]$[Minus_]$[0,8] $[False]$[]
[18]$[Number]$[0,10]$[False]$[]
[*]$[Multiply_]$[0,13]$[False]$[]
[18]$[Number]$[0,15]$[False]$[]
第一個單詞的意思是:這個單詞是【19】,類別是【Number】,在 源代碼中第一個字符的位置是【行0, 列0】,是否錯誤的單詞【False】,其它描述信息為【】(空,即木有 描述信息))
然後是根據這個單詞流分析出語法樹:
1 var expSyntaxParser = new SyntaxParserExpression();
2 expSyntaxParser.SetTokenList(tokens);
3 var syntaxTree = expSyntaxParser.Parse();
得到的語法樹是一個樹的結構,可以表示如下:
<Expression>
├─<Multiply>
│ ├─ <Unit>
│ │ └─number(19)
│ └─ <MultiplyOpt>
│ ├─*
│ └─ <Unit>
│ └─number(19)
└─ <PlusOpt>
├─-
└─<Multiply>
├─<Unit>
│ └─ number(18)
└─<MultiplyOpt>
├─*
└─<Unit>
└─number(18)
從此樹中可以看到,樹的結構和上文的 文法展開過程是對應的,並且樹的葉結點從上到下組成了我們的例子【19 * 19 - 18 * 18】
然後就是 語義分析了。到目前為止(據我所學到的),人類還沒有完善的自動生成語義分析代碼的能力。我們在此處就 把”計算結果“作為語義分析的任務。仍以上例進行說明。各個葉結點的含義我們是知道的,【+】【-】【* 】【/】代表運算,【number】代表數值,【identifier】代表變量名。那麼在沒有【identifier】的時候, 數和數就直接算出結果來,有【identifier】就保留著不動。我們分別為Expression文法的各類結點都賦予語 義:
<Expression>:將它的兩個子結點進行運算或保留。
<Multiply>:將它的兩 個子結點進行運算或保留。
<PlusOpt>:去掉自己,用自己的子結點代替自己的位置。
<Unit>:去掉自己,用自己的子結點代替自己的位置。
<MultiplyOpt>:去掉自 己,用自己的子結點代替自己的位置。
“+”:對自己的左右結點進行加法運算。
“-”:對自 己的左右結點進行減法運算。
“*”:對自己的左右結點進行乘法運算。
“/”:對自己的左右 結點進行除法運算。
identifier:保持不變。
number:保持不變。
“(“:若自己右部 的<Expression>成為數字或單一的【identifier】,則去掉自己,去掉<Expression>右部的”) ”;否則不變。
“)”:保持不變。
上例經過語義分析(對語法樹自頂向下進行遞歸分析其語 義),就得到一個數值”37“。
語義分析的偽代碼如下:
語義分析偽代碼
SyntaxTreeExpression SemanticAnalyze(SyntaxTree root)
{
switch(root.NodeType)
{
case EnumTreeNodeType.Expression:
return Cacul(SemanticAnalyze(root.Children[0]),SemanticAnalyze(root.Children[1]));
break;
case EnumTreeNodeType.Multiply:
return Cacul(SemanticAnalyze(root.Children[0]),SemanticAnalyze(root.Children[1]));
break;
case EnumTreeNodeType.PlusOpt:
var child = SemanticAnalyze(root.Children[0]);
var child2 = SemanticAnalyze(root.Children[1]);
root.parent.Children[1] = child; root.parent.Children[2] = child2;
break;
case EnumTreeNodeType.Unit:
root.parent.Children[0] = root.Children[0];
break;
//…
case EnumTreeNodeType.Plus:// “+”
return Calcu(SemanticAnalyze(root.parent.Children[0]), SemanticAnalyze
(root.parent.Children[2]));
break;
//…
}
語義分析完成,我們這個編譯器前端也就大功告成了。
所以這個編譯器要實現的東西大體 感覺就是這樣的。雖然單單對Expression進行編譯分析是沒多大意思的,但是這個例子在足夠簡單的同時,又 足夠典型,等我們把這個例子實現了,再復雜的編譯器也都能做出來了。編譯器制作步驟比較多,工作量也大 ,如果一上來就抱著完整的C語言文法來做,等於把自己埋在深不見底的BUG海洋中活活淹死。
以後實 現了編譯器的語法分析後,就可以自動生成示例中的語法樹了,其實這也算是一種語義分析。
後面系 列文章將給出具體的設計和實現過程,以及完整的工程代碼。敬請關注!
關於本系列有什麼好的建議 ,也請提出來,O(∩_∩)O謝謝!
PS:下面給出【(19 + 18) * (19 - 18)】的語法樹,供大家學習參 考,也方便後續文章講解。
<Expression>
├─<Multiply>
│ ├─<Unit>
│ │ ├─(
│ │ ├─ <Expression>
│ │ │ ├─<Multiply>
│ │ │ │ ├─<Unit>
│ │ │ │ │ └─number(19)
│ │ │ │ └─ <MultiplyOpt>
│ │ │ │ └─null
│ │ │ └─<PlusOpt>
│ │ │ ├─+
│ │ │ └─<Multiply>
│ │ │ ├─<Unit>
│ │ │ │ └─number(18)
│ │ │ └─<MultiplyOpt>
│ │ │ └─null
│ │ └─)
│ └─ <MultiplyOpt>
│ ├─*
│ └─ <Unit>
│ ├─(
│ ├─<Expression>
│ │ ├─ <Multiply>
│ │ │ ├─<Unit>
│ │ │ │ └─number(19)
│ │ │ └─<MultiplyOpt>
│ │ │ └─null
│ │ └─<PlusOpt>
│ │ ├ ─-
│ │ └─<Multiply>
│ │ ├─<Unit>
│ │ │ └─number(18)
│ │ └─<MultiplyOpt>
│ │ └─null
│ └─)
└─<PlusOpt>
└─null
出 處http://www.cnblogs.com/bitzhuwei