搞了SQL Server時間也不短了,對B樹的概念也算是比較了解。去網上搜也搜不到用C#或java實現的B樹,干脆自己寫一個。實現B樹的過程中也對很多細節有了更深的了解。
簡介
B樹是一種為輔助存儲設計的一種數據結構,在1970年由R.Bayer和E.mccreight提出。在文件系統和數據庫中為了減少IO操作大量被應用。遺憾的是,他們並沒有說明為什麼取名為B樹,但按照B樹的性質來說B通常被解釋為Balance。在國內通常有說是B-樹,其實並不存在B-樹,只是由英文B-Tree直譯成了B-樹。
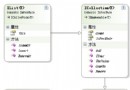
一個典型的 B樹如圖1所示。
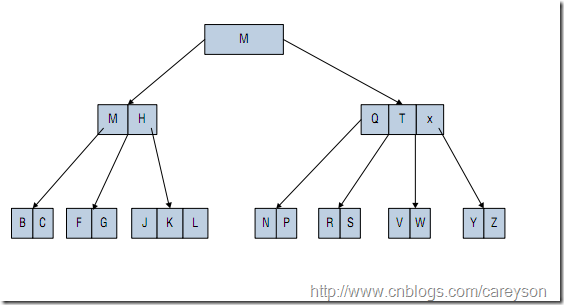
圖1.一個典型的B樹
符合如下特征的樹才可以稱為B樹:
根節點如果不是葉節點,則至少需要兩顆子樹
每個節點中有N個元素,和N+1個指針。每個節點中的元素不得小於最大節點容量的1/2
所有的葉子位於同一層級(這也是為什麼叫平衡樹)
父節點元素向左的指針必須小於節點元素,向右的指針必須大於節點元素,比如圖1中Q的左指針必須小於Q,右指針必須大於Q
為什麼要使用B樹
在計算機系統中,存儲設備一般分為兩種,一種為主存(比如說CPU二級緩存,內存等),主存一般由硅制成,速度非常快,但每一個字節的成本往往高於輔助存儲設備很多。還有一類是輔助存儲(比如硬盤,磁盤等),這種設備通常容量會很大,成本也會低很多,但是存取速度非常的慢,下面我們來看一下最常見的輔存--硬盤。
硬盤作為主機中除了唯一的一個機械存儲設備,速度遠遠落後於CPU和內存。圖2是一個典型的磁盤驅動器。
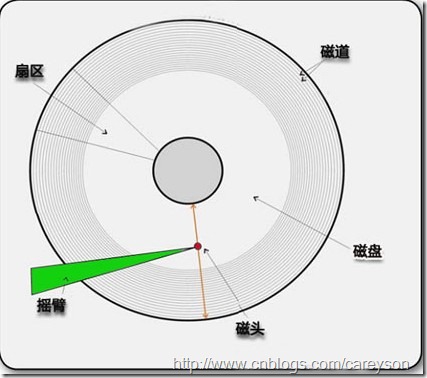
圖2.典型的磁盤驅動器工作原理
一個驅動器包含若干盤片,以一定的速度繞著主軸旋轉(比如PC常見的轉速是7200RPM,服務器級別的有10000RPM和15000RPM的),每個盤片表面覆蓋一個可磁化的物質.每個盤片利用搖臂末端的磁頭進行讀寫。搖臂是物理連接在一起的,通過移動遠離或貼近主軸。
因為有機械移動的部分,所以磁盤的速度相比內存而言是非常的慢。這個機械移動包括兩個部分:盤旋轉和磁臂移動。僅僅對於盤旋轉來說,比如常見的7200RPM的硬盤,轉一圈需要60/7200≈8.33ms,換句話說,讓磁盤完整的旋轉一圈找到所需要的數據需要8.33ms,這比內存常見的100ns慢100000倍左右,這還不包括移動搖臂的時間。
因為機械移動如此的花時間,磁盤會每次讀取多個數據項。一般來說最小單位為簇。而對於SQL Server來說,則為一頁(8K)。
但由於要查找的數據往往很大,不能全部裝入主存。需要磁盤來輔助存儲。而讀取磁盤則是占處理時間最重要的一部分,所以如果我們盡可能的減少對磁盤的IO操作,則會大大加快速度。這也是B樹設計的初衷。
B樹通過將根節點放入主存,其它所有節點放入輔存來大大減少對於輔存IO的操作。比如圖1中,我如果想查找元素Y,僅僅需要從主存中取得根節點,再根據根節點的右指針做一次IO讀,再根據這個節點最右的指針做一次IO讀,就可以找到元素Y。相比其他數據結構,僅僅做兩次輔存IO讀大大減少了查找的時間。
B樹的高度
根據上面的例子我們可以看出,對於輔存做IO讀的次數取決於B樹的高度。而B樹的高度由什麼決定的呢?
根據B樹的高度公式:
![]()
其中T為度數(每個節點包含的元素個數),N為總元素個數.
我們可以看出T對於樹的高度有決定性的影響。因此如果每個節點包含更多的元素個數,在元素個數相同的情況下,則更有可能減少B樹的高度。這也是為什麼SQL Server中需要盡量以窄鍵建立聚集索引。因為SQL Server中每個節點的大小為8092字節,如果減少鍵的大小,則可以容納更多的元素,從而減少了B樹的高度,提升了查詢的性能。
上面B樹高度的公式也可以進行推導得出,將每一層級的的元素個數加起來,比如度為T的節點,根為1個節點,第二層至少為2個節點,第三層至少為2t個節點,第四層至少為2t*t個節點。將所有最小節點相加,從而得到節點個數N的公式:
![]()
兩邊取對數,則可以得到樹的高度公式。
這也是為什麼開篇所說每個節點必須至少有兩個子元素,因為根據高度公式,如果每個節點只有一個元素,也就是T=1的話,那麼高度將會趨於正無窮。
B樹的實現
講了這麼多概念,該到實現B樹的時候了。
首先需要定義B樹的節點,如代碼1所示。
publicclass TreeNode<T>where T:IComparable<T>
{
publicint elementNum = 0;//元素個數public IList<T> Elements = new List<T>();//元素集合,存在elementNum個public IList<TreeNode<T>> Pointer = new List<TreeNode<T>>();//元素指針,存在elementNum+1publicbool IsLeaf = true;//是否為葉子節點
}
代碼1.聲明節點
我給每個節點四個屬性,分別為節點包含的元素個數,節點的元素數組,節點的指針數組和節點是否為葉子節點。我這裡對節點存儲的元素類型使用了泛型T,並且必須實現ICompable接口使得節點所存儲的元素可以互相比較。
有了節點的定義後,就可以創建B樹了,如代碼2所示。
//創建一個b樹,也是類的構造函數public BTree()
{
RootNode = new TreeNode<T>();
RootNode.elementNum = 0;
RootNode.IsLeaf = true;
//將節點寫入磁盤,做一次IO寫
}
代碼2.初始化B樹
這是BTree類的構造函數,初始化一個根節點。全部代碼我稍後給出。
下面則要考慮B樹的插入,其實B樹的構建過程也是向B樹插入元素的過程.B樹的插入相對來說比較復雜,需要考慮很多因素。
首先,每一個節點可容納的元素個數是一樣並且有限的,這裡我聲明了一個常量最為每個節點,如代碼3所示。
constint NumPerNode = 4;
代碼3.設置每個節點最多容納的元素個數
對於B樹來說,節點增加的唯一方式就是節點分裂,這個概念和SQL SERVER中的頁分裂是一樣的。
頁分裂的過程首先需要生成新頁,然後將大概一半的元素移動到新頁中,然後將中間元素提升到父節點。比如我想在現有的元素中插入8,造成已滿的頁進行分裂,如圖3所示:
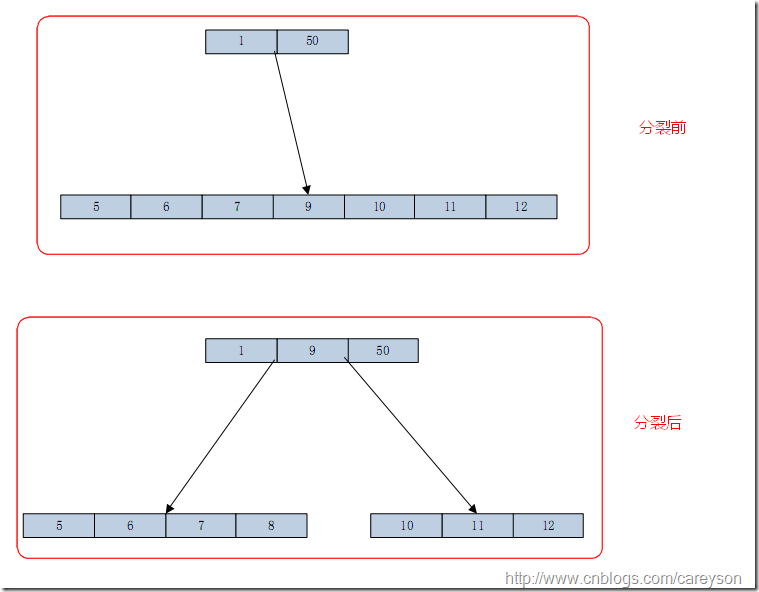
圖3.向已經滿的葉子節點插入元素會造成頁分裂
通過葉子分裂的概念不難看出,葉子節點分裂才會造成非葉子節點元素的增加。最終傳遞到根元素。而根元素的分裂是樹長高的唯一途徑。
在C#中的實現代碼如代碼4所示。
//B樹中的節點分裂publicvoid BTreeSplitNode(TreeNode<T> FatherNode, int position, TreeNode<T> NodeToBeSplit)
{
TreeNode<T> newNode = new TreeNode<T>();//創建新節點,容納分裂後被移動的元素
newNode.IsLeaf = NodeToBeSplit.IsLeaf;//新節點的層級和原節點位於同一層
newNode.elementNum = NumPerNode - (NumPerNode / 2 + 1);//新節點元素的個數大約為分裂節點的一半for (int i = 1; i < NumPerNode - (NumPerNode / 2 + 1); i++)
{
//將原頁中後半部分復制到新頁中
newNode.Elements[i - 1] = NodeToBeSplit.Elements[i + NumPerNode / 2];
}
if (!NodeToBeSplit.IsLeaf)//如果不是葉子節點,將指針也復制過去
{
for (int j = 1; j < NumPerNode / 2 + 1; j++)
{
newNode.Pointer[j - 1] = NodeToBeSplit.Pointer[NumPerNode / 2];
}
}
NodeToBeSplit.elementNum = NumPerNode / 2;//原節點剩余元素個數//將父節點指向子節點的指針向後推一位for (int k = FatherNode.elementNum + 1; k > position + 1; k--)
{
FatherNode.Pointer[k] = FatherNode.Pointer[k - 1];
}
//將父節點的元素向後推一位for (int k = FatherNode.elementNum; k > position + 1; k--)
{
FatherNode.Elements[k] = FatherNode.Elements[k - 1];
}
//將被分裂的頁的中間節點插入父節點
FatherNode.Elements[position - 1] = NodeToBeSplit.Elements[NumPerNode / 2];
//父節點元素大小+1
FatherNode.elementNum += 1;
//將FatherNode,NodeToBeSplit,newNode寫回磁盤,三次IO寫操作
}
代碼4.分裂節點
通過概念和代碼不難看出,節點的分裂相對比較消耗IO,這也是為什麼SQL Server中需要一些最佳實現比如不用GUID做聚集索引,或是設置填充因子等來減少頁分裂。
而如果需要插入元素的節點不滿,則不需要頁分裂,則需要從根開始查找,找到需要被插入的節點,如代碼5所示。
//在節點非滿時尋找插入節點publicvoid BTreeInsertNotFull(TreeNode<T> Node, T KeyWord)
{
int i=Node.elementNum;
//如果是葉子節點,則尋找合適的位置直接插入if (Node.IsLeaf)
{
while (i >= 1 && KeyWord.CompareTo(Node.Elements[i - 1]) < 0)
{
Node.Elements[i] = Node.Elements[i - 1];//所有的元素後推一位
i -= 1;
}
Node.Elements[i - 1] = KeyWord;//將關鍵字插入節點
Node.elementNum += 1;
//將節點寫入磁盤,IO寫+1
}
//如果是非葉子節點else
{
while (i >= 1 && KeyWord.CompareTo(Node.Elements[i - 1]) < 0)
{
i -= 1;
}
//這步將指針所指向的節點讀入內存,IO讀+1if (Node.Pointer[i].elementNum == NumPerNode)
{
//如果子節點已滿,進行節點分裂
BTreeSplitNode(Node, i, Node.Pointer[i]);
}
if (KeyWord.CompareTo(Node.Elements[i - 1]) > 0)
{
//根據關鍵字的值決定插入分裂後的左孩子還是右孩子
i += 1;
}
//迭代找葉子,找到葉子節點後插入
BTreeInsertNotFull(Node.Pointer[i], KeyWord);
}
}
代碼5.插入
通過代碼5可以看出,我們沒有進行任何迭代。而是從根節點開始遇到滿的節點直接進行分裂。從而減少了性能損失。
再將根節點分裂的特殊情況考慮進去,我們從而將插入操作合為一個函數,如代碼6所示。
publicvoid BtreeInsert(T KeyWord)
{
if (RootNode.elementNum == NumPerNode)
{
//如果根節點滿了,則對跟節點進行分裂
TreeNode<T> newRoot = new TreeNode<T>();
newRoot.elementNum = 0;
newRoot.IsLeaf = false;
//將newRoot節點變為根節點
BTreeSplitNode(newRoot, 1, RootNode);
//分裂後插入新根的樹
BTreeInsertNotFull(newRoot, KeyWord);
//將樹的根進行變換
RootNode = newRoot;
}
else
{
//如果根節點沒有滿,直接插入
BTreeInsertNotFull(RootNode, KeyWord);
}
}
代碼6.插入操作
現在,我們就可以通過插入操作,來實現一個B樹了。
B樹的查找
既然B樹生成好了,我們就可以對B樹進行查找了。B樹的查找實現相對簡單,僅僅是從跟節點進行迭代,如果找到元素則返回節點和位置,如果找不到則返回NULL.
//從B樹中搜索節點,存在則返回節點和元素在節點的值,否則返回NULLpublic returnValue<T> BTreeSearch(TreeNode<T> rootNode, T keyword)
{
int i = 1;
while (i <= rootNode.elementNum && keyword.CompareTo(rootNode.Elements[i - 1])>0)
{
i = i + 1;
}
if (i <= rootNode.elementNum && keyword.CompareTo(rootNode.Elements[i - 1]) == 0)
{
returnValue<T> r = new returnValue<T>();
r.node = rootNode.Pointer[i];
r.position = i;
return r;
}
if (rootNode.IsLeaf)
{
returnnull;
}
else
{
//從磁盤將內容讀出來,做一次IO讀return BTreeSearch(rootNode.Pointer[i], keyword);
}
}
代碼7.對B樹進行查找
順帶說一下,returnValue類僅僅是對返回值的一個封裝,代碼如代碼8所示。
publicclass returnValue<T> where T : IComparable<T>
{
public TreeNode<T> node;
publicint position;
}
代碼8.returnValue的代碼
總結
本文從B樹的概念原理,以及為什麼需要B樹到B樹的實現來闡述B樹的概念。B樹是一種非常優雅的數據結構。是關系數據庫和文件系統的核心算法。對於B樹的了解會使得你對於數據庫的學習更加系統和容易。
本文示例代碼點擊這裡下載:http://files.cnblogs.com/CareySon/BTreeCsharp.rar