在實際開發中,經常需要將一些字符串寫入到文本文件中,或者從文本文件中讀入字符串,在 .NET應用程序中,通常使用 StreamReader或 StreamWriter兩個類完成這一工作,比如以下代碼將 fileContent字串寫入到 FileName文件中:
static void WriteFileUseStreamWriter(String fileContent, String FileName)
{
using (StreamWriter writer = new StreamWriter(FileName))
{
writer.Write(fileContent);
}
}
如果你使用 .NET基類庫中相關類(比如 StreamReader或下面用到的 File類)去讀取這個文件,你會發現一切如你所願地正常運轉:
WriteFileUseStreamWriter( " 中國ab " , " test.txt " );由於多數情況下我們都工作在中文 Windows下,而且往往都是某個 .NET程序寫,另一個 .NET程序讀,所以,不少 .NET程序員可能都沒注意到這其中其實存在著一個字符編碼的問題,在特定的場合下,這一問題會給我們帶來麻煩。
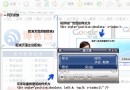
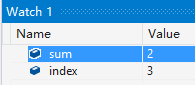
請看圖 1:
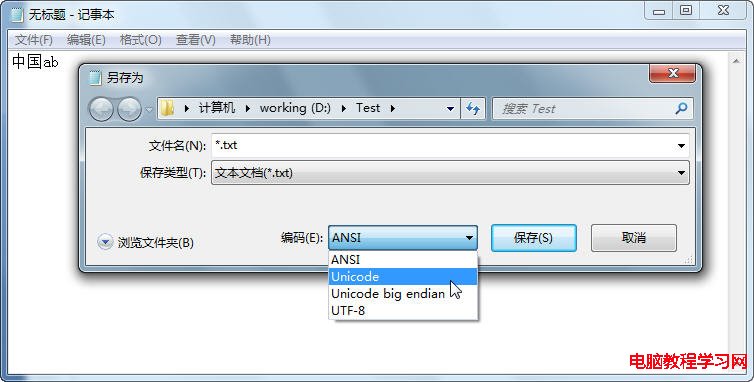
圖1 記事本支持的編碼方式
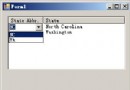
默認情況下, Windows記事本以 ANSI編碼方式保存文件。如圖 1所示,如果文本內容為“中國 ab ” ,記事本將其以 ASNI方式保存為“ test.txt”,則以下代碼將“罷工”了(參看圖 2):
Console.WriteLine(File.ReadAllText( " test.txt " ));
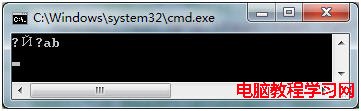
圖2 漢字將顯示為亂碼
如 圖 2 所示, File.ReadAllText方法打開“ test.txt”文件時,會發現英文字符可以正常顯示,但中文將顯示為亂碼。
2 了解字符的編碼
我們可以做個試驗,使用記事本將“中國 ab”這個中英混雜的字符串以不同編碼方式保存為多個“ .txt”文件,然後直接查看其二進制內容:

圖3 比對字符編碼
圖 3 展示了“中國 ab”按四種編碼方式( ANSI、 UTF8、 Unicode、 Unicode Big Endian )得到的不同二進制數據。
以英文字符“ a”為例, ANSI和 UTF8得到的數值都是“ 61”,但 Unicode將它擴充為 2個字節 16位的二進制(“ 61 00”和“ 00 61”),所以我們又將這種編碼方式稱為 UTF-16。
UTF-16 又可以細分為 2種編碼方式: Big Endian方式與 Little_Edian方式,這兩者的唯一區別在於字節排列順序剛好相反, Little_Edian方式將“ a”編碼為“ 61 00”,而 Big Endian方式則編碼為“ 00 61”。
現在看看中文字符,“中國”兩個漢字, ANSI編碼為“ D6 D0 B9 FA”, 4個字節,一個漢字占兩個字節,而 UTF8則編碼為“ E4 B8 AD E5 9B BD”, 6個字節,一個漢字占 3個字節!這說明 UTF8是一種“變長”的編碼,可能使用 1~4個字節來表示某個字符。
另外,我們看到 UTF8和 Unicode編碼(不管是 Big Endian還是 Little Endian )前面都有幾個標記字符,這些字符放在文本文件的開頭,稱為“ BOM( Byte Order Mark,字節順序標記)”指明了文本的編碼方式,以下是 .NET程序中常見的字符編碼方式的 BOM值:
編碼
BOM 值
UTF-8
EF BB BF
UTF-16 big endian
FE FF
UTF-16 little endian
FF FE
UTF-32 big endian
00 00 FE FF
UTF-32 little endian
FF FE 00 00
了解了上述基礎知識,我們就可以依據 BOM值自動檢測字符串的編碼方式,從而正確從二進制數據流中解碼,以下代碼檢測文本二進制數據是否采用 UTF8編碼:
// 打開文件讀取二進制數據其他的編碼方式都可以“依樣畫葫蘆”。
3 詳解 .NET 基類庫中與字符編碼相關的類
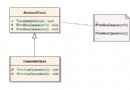
前述代碼中的 Encoding類是 .NET實現字符編碼解碼的核心類型。圖 4展示了它的屬性:
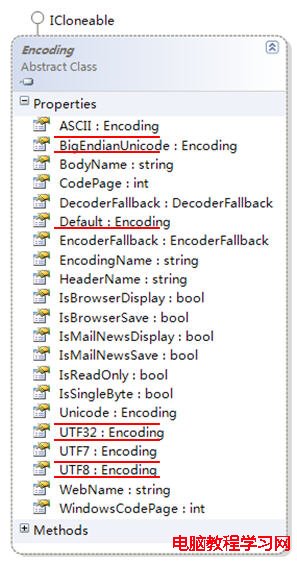
圖 4 Encoding類型
如圖 4所示, Encoding類型提供了 UTF8、 Unicode等編碼和解碼器,調用它的 Get系列方法完成編碼和解碼工作,以下為示例代碼:
// 編碼運行結果如下:
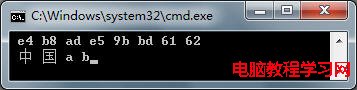
圖5 編碼和解碼
需要注意的是上述二進制值不包括 BOM。
事實上, .NET中的 StreamWriter默認采用 UTF8編碼格式編碼字符串,但並不將 UTF8所對應的 BOM值(“ EF BB BF”)寫入到二進制流中。以下是 StreamWriter的一個構造函數聲明:
public StreamWriter( string path) : this (path, false , UTF8NoBOM , 0x400 )
類似地, File.ReadAllText()方法在內部使用 UTF8來讀取指定文件中的字符串 :
public static string ReadAllText( string path)由於默認編碼方式一致,所以配套使用 StreamWriter和 File.ReadAllText()方法可以正確地從流中存取字符串。
出於提升代碼可維護性考慮,正確的用法應該是明確地指明編碼方式:
static void WriteFileUseStreamWriterUseUTF8(String fileContent, String FileName)這時, StreamWriter會在文件開頭寫入 UTF8的 BOM標記,從而讓其他的應用程序可以很明確地知道本文件中字符串的編碼方式。
4 談談有趣的 Encoding.Default 屬性
Encoding 類中有一個有趣的 Default屬性,它的類型很奇怪,叫作“ DBCSCodePageEncoding”,這個類型在 MSDN中是查不到的。
“ DBCS”代表“ double-byte character set (雙字節字符集)”,它是與“ SBCS( single-byte character set,單字節字符集)”相對應的, SBCS中,所有字符都只占一個字節,所以能表示的字符數有限,但在 DBCS中,英文字母占一個字節,漢字等特殊字符占有兩個字節,從而擴充了 Windows能顯示的字符數量。
DBCSCodePageEncoding 中的“ Code Page”被稱為“ 代碼頁 ”,每個代碼頁定義了特定的編碼將如何對應於特定的字符(比如簡體和繁體中文就分別定義在不同的代碼頁中),因此,同樣的二進制數值,在不同的代碼頁中,會代表不同的字符。中文 Windows通過使用基於代碼頁的 DBCS編碼方式,可以方便地以多種編碼方式顯示和處理字符串。
我們在 MSDN中可以查到所有代碼頁的編號,下面列出了可能比較常用的代碼頁標識:
代碼頁標識值 .NET中的名字.NET 應用程序可以通過以下方式獲取指定代碼頁的編碼對象:
Encoding encode = Encoding.GetEncoding(CodePage);
以下代碼將按照指定代碼頁編碼字符串,並將其寫入到文件中:
static void WriteFileUseStreamWriterUseCodePage(String fileContent,String FileName, int CodePage)現在,使用以下代碼將按照 UTF8編碼字符串:
WriteFileUseStreamWriterUseCodePage( " 中國ab " , " test.txt " , 65001 );5 結束語
除了本文所介紹的將字符串保存到文本文件的這種場景,字符串的編碼方式在基於套接字的 TCP/UDP網絡編程也非常重要,比如 .NET提供了一個 NetworkStream封裝 Socket實現網絡通訊,如果希望將一個命令字符串從客戶端送到服務端,服務端通過讀取這個字符串完成特定的工作,則編碼方式就很重要了,客戶端與服務端必須采用一致的編碼方式傳送命令,否則,網絡服務就有可能因為無法解析客戶端發送過來的數據而 Down掉。
有關網絡編程的內容很有趣,我的下一篇文章會介紹 .NET套接字編程。
好了,這篇介紹字符串編碼的短文寫完了,希望本文能對讀者有所幫助,如有錯誤,敬請指正