在我們的日常web應用開發當中memcached可以算作是當今的標准開發配置了。相信memcache的基本原理大家也都了解過了,memcache雖然是分布式的應用服務,但分布的原則是由client端的api來決定的,api根據存儲用的key以及已知的服務器列表,根據key的hash計算將指定的key存儲到對應的服務器列表上。
基本的原理以及分布
在這裡我們通常使用的方法是根據 key的hash值%服務器數取余數 的方法來決定當前這個key的內容發往哪一個服務器的。這裡會涉及到一個hash算法的分布問題,哈希的原理用一句話解釋就是兩個集合間的映射關系函數,在我們通常的應用中基本上可以理解為 在集合A(任意字母數字等組合,此處為存儲用的key)裡的一條記錄去查找集合B(如0-2^32)中的對應記錄。(題外話:md5的碰撞或者說沖突其實就是發生在這裡,也就是說多個A的記錄映射到了同一個B的記錄)
實際應用
顯然在我們的應用中集合A的記錄應該更均勻的分布在集合B的各個位置,這樣才能盡量避免我們的數據被分布發送到單一的服務器上,在danga的memcached的原始版本(perl)中使用的是crc32的算法用java的實現寫出來:
private static int origCompatHashingAlg( String key ) {
int hash = 0;
char[] cArr = key.toCharArray();
for ( int i = 0; i < cArr.length; ++i ) {
hash = (hash * 33) + cArr[i];
}
return hash;
}
這裡還有另一個改進版本的算法:
private static int newCompatHashingAlg( String key ) {
CRC32 checksum = new CRC32();
checksum.update( key.getBytes() );
int crc = (int) checksum.getValue();
return (crc >> 16) & 0x7fff;
}
分布率測試
有人做過測試,隨機選擇的key在服務器數量為5的時候所有key在服務器群組上的分布概率是:
origCompatHashingAlg:
0 10%
1 9%
2 60%
3 9%
4 9%
newCompatHashingAlg:
0 19%
1 19%
2 20%
3 20%
4 20%
顯然使用舊的crc32算法會導致第三個memcached服務的負載更高,但使用新算法會讓服務之間的負載更加均衡。
其他常用的hash算法還有FNV-1a Hash,RS Hash,JS Hash,PJW Hash,ELF Hash,AP Hash等等。有興趣的童鞋可以查看這裡:
小結
至此我們了解到了在我們的應用當中要做到盡量讓我們的映射更加均勻分布,可以使服務的負載更加合理均衡。
新問題
但到目前為止我們依然面對了這樣一個問題:就是服務實例本身發生變動的時候,導致服務列表變動從而會照成大量的cache數據請求會miss,幾乎大部分數據會需要遷移到另外的服務實例上。這樣在大型服務在線時,瞬時對後端數據庫/硬盤照成的壓力很可能導致整個服務的crash。
一致性哈希(Consistent Hashing)
在此我們采用了一種新的方式來解決問題,處理服務器的選擇不再僅僅依賴key的hash本身而是將服務實例(節點)的配置也進行hash運算。
整個數據的圖例:
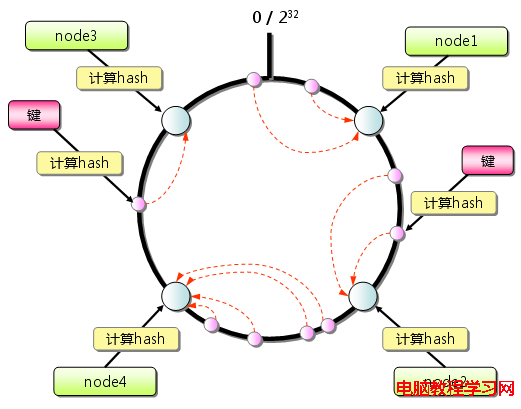
當增加服務節點時:
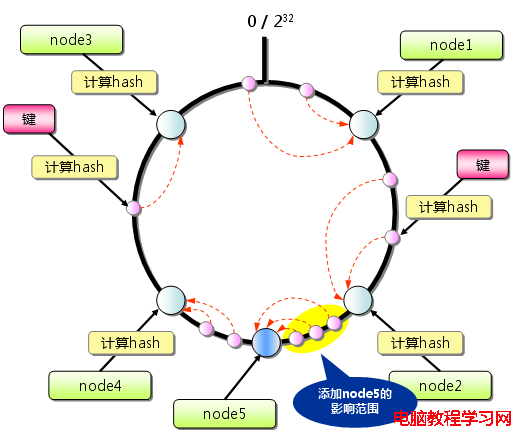
其他:只有在圓環上增加服務節點的位置為逆時針方向的第一個服務節點上的鍵會受到影響。
小結
一致性哈希算法最大程度的避免了key在服務節點列表上的重新分布,其他附帶的改進就是有的一致性哈希算法還增加了虛擬服務節點的方法,也就是一個服務節點在環上有多個映射點,這樣就能抑制分布不均勻,
最大限度地減小服務節點增減時的緩存重新分布。
應用
在memcached的實際應用,雖然官方的版本並不支持Consistent Hashing,但是已經有了現實的Consistent Hashing實現以及虛節點的實現,第一個實現的是last.fm(國外流行的音樂平台)開發的libketama,
其中調用的hash的部分的java版本的實現(基於md5):
/**
* Calculates the ketama hash value for a string
* @param s
* @return
*/
public static Long md5HashingAlg(String key) {
if(md5==null) {
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
log.error( "++++ no md5 algorythm found" );
throw new IllegalStateException( "++++ no md5 algorythm found");
}
}
md5.reset();
md5.update(key.getBytes());
byte[] bKey = md5.digest();
long res = ((long)(bKey[3]&0xFF) << 24) | ((long)(bKey[2]&0xFF) << 16) | ((long)(bKey[1]&0xFF) << 8) | (long)(bKey[0]&0xFF);
return res;
}
在一致性哈希的算法/策略環境中,按照測試來說時間和分布性都是綜合來說比較讓人滿意的,參見:
總結
在我們的web開發應用中的分布式緩存系統裡哈希算法承擔著系統架構上的關鍵點。
使用分布更合理的算法可以使得多個服務節點間的負載相對均衡,可以最大程度的避免資源的浪費以及服務器過載。
使用一致性哈希算法,可以最大程度的降低服務硬件環境變化帶來的數據遷移代價和風險。
使用更合理的配置策略和算法可以使分布式緩存系統更加高效穩定的為我們整體的應用服務。
展望
一致性哈希的算法/策略來源於p2p網絡,其實縱觀p2p網絡應用的場景,在許多地方與我們的應用有很多相似的地方,可以學習借鑒。