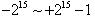DataGrid是一個功能非常強大的ASP.NET Web服務器端控件,它除了能夠方便地按各種方式格式化顯示表格中的數據,還可以對表格中的數據進行動態的排序、編輯和分頁。使Web開發人員從繁瑣的代碼中解放。實現DataGrid的分頁功能一直是很多初學ASP.NET的人感到棘手的問題,特別是自定義分頁功能,實現方法多種多樣,非常靈活。本文將向大家介紹一種DataGird控件在Access數據庫下的快速分頁法,幫助初學者掌握DataGrid的分頁技術。
目前的分頁方法
DataGrid內建的分頁方法是使用諸如“SELECT * FROM <TABLE>”的SQL語句從數據庫表中取出所有的記錄到DataSet中,DataGrid控件綁定到該DataSet之後,它的自動分頁功能會幫你從該DataSet中篩選出當前分頁的數據並顯示出來,其他沒有用的數據將被丟棄。
還有一種方法是使用自定義分頁功能,先將DataGrid的AllowCustomPaging屬性設置為True,再利用DataAdapter的Fill方法將數據的篩選工作提前到填充DataSet時,而不是讓DataGrid幫你篩選:
public int Fill (
DataSet dataSet, //要填充的 DataSet。
int startRecord, //從其開始的從零開始的記錄號。
int maxRecords, //要檢索的最大記錄數。
string srcTable //用於表映射的源表的名稱。
);
該方法首先將來自查詢處的結果填充到DataSet中,再將不需要顯示的數據丟棄。當然,自定義分頁功能需要完成的事情還不止這些,本文將在後面詳細介紹。
以上兩種方法的工作原理都是先從數據庫中取出所有的記錄,然後篩選出有用的數據顯示出來。可見,兩種方法的效率基本上是一致的,因為它們在數據訪問階段並沒有采取有效的措施來減少Access對磁盤的訪問次數。對於小數量的記錄,這種開銷可能是比較小的,如果針對大量數據的分頁,開銷將會非常巨大,從而導致分頁的速度非常的慢。換句話說,就算每個DataGrid分頁面要顯示的數據只是一個擁有幾萬條記錄的數據庫表的其中10條,每次DataGrid進行分頁時還是要從該表中取出所有的記錄。
很多人已經意識到了這個問題,並提出了解決方法:用自定義分頁,每次只從數據庫中取出要顯示的數據。這樣,我們需要在SQL語句上下功夫了。由於Access不支持真正的存儲過程,在編寫分頁算法上就沒有SQL Server那麼自由了。SQL Server可以在存儲過程中利用臨時表來實現高效率的分頁算法,受到了廣泛的采用。而對於Access,我們必須想辦法在一條SQL語句內實現最高效的算法。
用一條SQL語句取得某段數據的方法有好幾種。算法不同,效率也就不同。我經過粗略的測試,發現效率最差的SQL語句執行時耗費的時間大概是效率最高的SQL語句的3倍!而且這個數值會隨著記錄總數的增加而增加。下面將介紹其中兩條常用的SQL語句。
為了方便接下來的討論,我們先約定如下:
變量
說明
變量
說明
@PageSize
每頁顯示的記錄總數
@MiddleIndex
中間頁的索引
@PageCount
分頁總數
@LastIndex
最後一頁的索引
@RecordCount
數據表的記錄總數
@TableName
數據庫表名稱
@PageIndex
當前頁的索引
@PrimaryKey
主鍵字段名稱
@FirstIndex
第一頁的索引
@QueryFields
要查詢的字段集
變量
定義
@PageCount
(int)Math.Ceiling((double)@RecordCount / @PageSize)
@FirstIndex
0
@LastIndex
@PageCount – 1
@MiddleIndex
(int)Math.Ceiling((double)@PageCount / 2) – 1
先讓我們看看效率最差的SQL語句:
SELECT TOP @PageSize * FROM @TableName
WHERE @PrimaryKey NOT IN (
SELECT TOP @PageSize*@PageIndex @PrimaryKey FROM @TableName
ORDER BY @PrimaryKey ASC
) ORDER BY @PrimaryKey ASC
這條SQL語句慢就慢在NOT IN這裡,主SELECT語句遍歷的每個@PrimaryKey的值都要跟子SELECT語句的結果集中的每一個@PrimaryKey的值進行比較,這樣時間復雜度非常大。這裡不得不提醒一下大家,平時編寫SQL語句時應該盡量避免使用NOT IN語句,因為它往往會增加整個SQL語句的時間復雜度。
另一種是使用了兩個TOP和三個ORDER BY的SQL語句,如下所示:
SELECT * FROM (
SELECT TOP @PageSize * FROM (
SELECT TOP @PageSize*(@PageIndex+1) * FROM @TableName
ORDER BY @PrimaryKey ASC
) TableA ORDER BY @PrimaryKey DESC
) TableB ORDER BY @PrimaryKey ASC
這條SQL語句空間復雜度比較大。如果要顯示的分頁面剛好是最後一頁,那麼它的效率比直接SELECT出所有的記錄還要低。因此,對於分頁算法,我們還應該具體情況具體分析,不能一概而論。下面將簡單介紹一下相關概念,如果您對主鍵和索引非常熟悉,可以直接跳過。
有關主鍵和索引的概念
在 ACCESS中,一個表的主鍵(PRIMARY KEY,又稱主索引)必然是唯一索引(UNIQUE INDEX),它的值是不會重復的。除此之外,索引依據索引列的值進行排序,每個索引記錄包含著一個指向它所引用的數據行的指針,這對ORDER BY的執行非常有幫助。我們可以利用主鍵這兩個特點來實現對某條記錄的定位,從而快速地取出某個分頁上要顯示的記錄。
舉個例子,假設主鍵字段為INTEGER型,在數據庫表中,記錄的索引已經按主鍵字段的值升序排好(默認情況下),那麼主鍵字段值為“11”的記錄的索引,肯定剛好在值為“12”的記錄的索引前面(假設數據庫表中存在主鍵的值為“12”的記錄)。如果主鍵字段不具備UNIQUE約束,數據庫表中將有可能存在兩個或兩個以上主鍵字段的值為“11”的記錄,這樣就無法確定這些記錄之間的前後位置了。
下面就讓我們看看如何利用主鍵來進行數據的分段查詢吧。
快速分頁法的原理
其實該分頁法是從其他方法衍生而來的。本人對原來的方法認真地分析,發現通過優化和改進可以非常有效地提高它的效率。原算法本身效率很高,但缺乏對具體問題的具體分析。同一個分頁算法,可能在取第一頁的數據時效率非常高,但是在取最後一頁的數據時可能反而效率更低。
經過分析,我們可以把分頁算法的效率狀態分為四種情況:
(1)@PageIndex <= @FirstIndex
(2)@FirstIndex < @PageIndex <= @MiddleIndex
(3)@MiddleIndex < @PageIndex < @LastIndex
(4)@PageIndex >= @LastIndex
狀態(1)和(4)分別表示第一頁和最後一頁。它們屬於特殊情況,我們不必對其使用特殊算法,直接用TOP就可以解決了,不然會把問題復雜化,反而降低了效率。對於剩下的兩種狀態,如果分頁總數為偶數,我們可以看作是從數據庫表中刪掉第一頁和最後一頁的記錄,再把剩下的按前後位置平分為兩部分,即前面的一部分,也就是狀態(2),後面的為另一部分,也就是狀態(3);如果分頁總數為奇數,則屬於中間頁面的記錄歸於前面的部分。這四種狀態分別對應著四組SQL語句,每組SQL語句由升序和降序兩條SQL語句組成。
下面是一個數據庫表,左邊第一列是虛擬的,不屬於該數據庫表結構的一部分,它表示相應記錄所在的分頁索引。該表將用於接下來的SQL語句的舉例中:
PageIndex
ItemId
ProductId
Price
0
001
0011
$12
002
0011
$13
1
003
0012
$13
004
0012
$11
2
005
0013
$14
006
0013
$12
3
007
0011
$13
008
0012
$15
4
009
0013
$12
010
0013
$11
由表可得:@PageSize = 2,@RecordCount = 10,@PageCount = 5
升序的SQL語句
(1)@PageIndex <= @FirstIndex
取第一頁的數據是再簡單不過了,我們只要用TOP @PageSize就可以取出第一頁要顯示的記錄了。
SELECT TOP @PageSize @QueryFields
FROM @TableName
WHERE @Condition
ORDER BY @PrimaryKey ASC
(2)@FirstIndex < @PageIndex <= @MiddleIndex
把取數據表前半部分記錄和取後半部分記錄的SQL語句分開寫,可以有效地改善性能。後面我再詳細解釋這個原因。現在看看取前半部分記錄的SQL語句。先取出當前頁之前的所有記錄的主鍵值,再從中選出最大值,然後取出主鍵值大於該最大值的前@PageSize條記錄。這裡@PrimaryKey的數據類型可以不是INTEGER類型,CHAR、VARCHAR等其他類型照樣可以。
SELECT TOP @PageSize @QueryFields
FROM @TableName
WHERE @PrimaryKey > (
SELECT MAX(@PrimaryKey) FROM (
SELECT TOP @PageSize*@PageIndex @PrimaryKey
FROM @TableName
WHERE @Condition
ORDER BY @PrimaryKey ASC
) TableA
) WHERE @Condition
ORDER BY @PrimaryKey ASC
例如:@PageIndex=1,紅-->黃-->藍
(3)@MiddleIndex < @PageIndex < @LastIndex
接下來看看取數據庫表中後半部分記錄的SQL語句。該語句跟前面的語句算法的原理是一樣的,只是方法稍微不同。先取出當前頁之後的所有記錄的主鍵值,再從中選出最小值,然後取出主鍵值小於該最小值的前@PageSize條記錄。
SELECT * FROM (
SELECT TOP @PageSize @QueryFields
FROM @TableName
WHERE @PrimaryKey < (
SELECT MIN(@PrimaryKey) FROM (
SELECT TOP (@RecordCount-@PageSize*(@PageIndex+1)) @PrimaryKey
FROM @TableName
WHERE @Condition
ORDER BY @PrimaryKey DESC
) TableA
) WHERE @Condition
ORDER BY @PrimaryKey DESC
) TableB
ORDER BY @PrimaryKey ASC