8.2 圖的存儲結構
圖的存儲結構除了要存儲圖中各個頂點的本身的信息外,同時還要存儲頂點與頂點之間的所有關系(邊的信息),因此,圖的結構比較復雜,很難以數據元素在存儲區中的物理位置來表示元素之間的關系,但也正是由於其任意的特性,故物理表示方法很多。常用的圖的存儲結構有鄰接矩陣、鄰接表、十字鏈表和鄰接多重表。
8.2.1鄰接矩陣表示法
對於一個具有n個頂點的圖,可以使用n*n的矩陣(二維數組)來表示它們間的鄰接關系。圖8.10和圖8.11中,矩陣A(i,j)=1表示圖中存在一條邊(Vi,Vj),而A(i,j)=0表示圖中不存在邊(Vi,Vj)。實際編程時,當圖為不帶權圖時,可以在二維數組中存放bool值,A(i,j)=true表示存在邊(Vi,Vj),A(i,j)=false表示不存在邊(Vi,Vj);當圖帶權值時,則可以直接在二維數組中存放權值,A(i,j)=null表示不存在邊(Vi,Vj)。
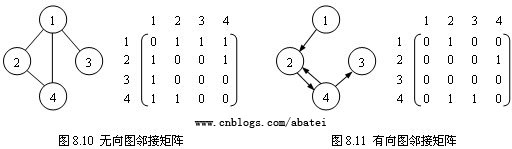
圖8.10所示的是無向圖的鄰接矩陣表示法,可以觀察到,矩陣延對角線對稱,即A(i,j)= A(j,i)。無向圖鄰接矩陣的第i行或第i列非零元素的個數其實就是第i個頂點的度。這表示無向圖鄰接矩陣存在一定的數據冗余。
圖8.11所示的是有向圖鄰接矩陣表示法,矩陣並不延對角線對稱,A(i,j)=1表示頂點Vi鄰接到頂點Vj;A(j,i)=1則表示頂點Vi鄰接自頂點Vj。兩者並不象無向圖鄰接矩陣那樣表示相同的意思。有向圖鄰接矩陣的第i行非零元素的個數其實就是第i個頂點的出度,而第i列非零元素的個數是第i個頂點的入度,即第i個頂點的度是第i行和第i列非零元素個數之和。
由於存在n個頂點的圖需要n2個數組元素進行存儲,當圖為稀疏圖時,使用鄰接矩陣存儲方法將出現大量零元素,照成極大地空間浪費,這時應該使用鄰接表表示法存儲圖中的數據。
8.2.2 鄰接表表示法
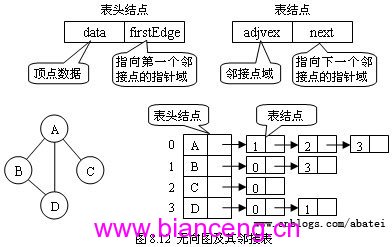
圖的鄰接矩陣存儲方法跟樹的孩子鏈表示法相類似,是一種順序分配和鏈式分配相結合的存儲結構。鄰接表由表頭結點和表結點兩部分組成,其中圖中每個頂點均對應一個存儲在數組中的表頭結點。如這個表頭結點所對應的頂點存在相鄰頂點,則把相鄰頂點依次存放於表頭結點所指向的單向鏈表中。如圖8.12所示,表結點存放的是鄰接頂點在數組中的索引。對於無向圖來說,使用鄰接表進行存儲也會出現數據冗余,表頭結點A所指鏈表中存在一個指向C的表結點的同時,表頭結點C所指鏈表也會存在一個指向A的表結點。
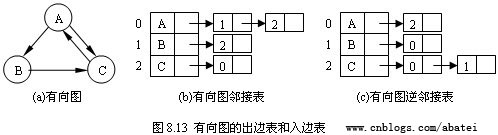
有向圖的鄰接表有出邊表和入邊表(又稱逆鄰接表)之分。出邊表的表結點存放的是從表頭結點出發的有向邊所指的尾頂點;入邊表的表結點存放的則是指向表頭結點的某個頭頂點。如圖8.13所示,圖(b)和(c)分別為有向圖(a)的出邊表和入邊表。
以上所討論的鄰接表所表示的都是不帶權的圖,如果要表示帶權圖,可以在表結點中增加一個存放權的字段,其效果如圖8.14所示。
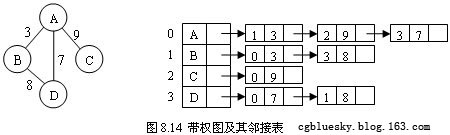
【注意】:觀察圖8.14可以發現,當刪除存儲表頭結點的數組中的某一元素,有可能使部分表頭結點索引號的改變,從而導致大面積修改表結點的情況發生。可以在表結點中直接存放指向表頭結點的指針以解決這個問題(在鏈表中存放類實例即是存放指針,但必須要保證表頭結點是類而不是結構體)。在實際創建鄰接表時,甚至可以使用鏈表代替數組存放表頭結點或使用順序表存代替鏈表存放表結點。對所學的數據結構知識應當根據實際情況及所使用語言的特點靈活應用,切不可生搬硬套。
【例8-1 AdjacencyList.cs】圖的鄰接表存儲結構
using System;
using System.Collections.Generic;
public class AdjacencyList<T>
{
List<Vertex<T>> items; //圖的頂點集合
public AdjacencyList() : this(10) { } //構造方法
public AdjacencyList(int capacity) //指定容量的構造方法
{
items = new List<Vertex<T>>(capacity);
}
public void AddVertex(T item) //添加一個頂點
{ //不允許插入重復值
if (Contains(item))
{
throw new ArgumentException("插入了重復頂點!");
}
items.Add(new Vertex<T>(item));
}
public void AddEdge(T from, T to) //添加無向邊
{
Vertex<T> fromVer = Find(from); //找到起始頂點
if (fromVer == null)
{
throw new ArgumentException("頭頂點並不存在!");
}
Vertex<T> toVer = Find(to); //找到結束頂點
if (toVer == null)
{
throw new ArgumentException("尾頂點並不存在!");
}
//無向邊的兩個頂點都需記錄邊信息
AddDirectedEdge(fromVer, toVer);
AddDirectedEdge(toVer, fromVer);
}
public bool Contains(T item) //查找圖中是否包含某項
{
foreach (Vertex<T> v in items)
{
if (v.data.Equals(item))
{
return true;
}
}
return false;
}
private Vertex<T> Find(T item) //查找指定項並返回
{
foreach (Vertex<T> v in items)
{
if (v.data.Equals(item))
{
return v;
}
}
return null;
}
//添加有向邊
private void AddDirectedEdge(Vertex<T> fromVer, Vertex<T> toVer)
{
if (fromVer.firstEdge == null) //無鄰接點時
{
fromVer.firstEdge = new Node(toVer);
}
else
{
Node tmp, node = fromVer.firstEdge;
do
{ //檢查是否添加了重復邊
if (node.adjvex.data.Equals(toVer.data))
{
throw new ArgumentException("添加了重復的邊!");
}
tmp = node;
node = node.next;
} while (node != null);
tmp.next = new Node(toVer); //添加到鏈表未尾
}
}
public override string ToString() //僅用於測試
{ //打印每個節點和它的鄰接點
string s = string.Empty;
foreach (Vertex<T> v in items)
{
s += v.data.ToString() + ":";
if (v.firstEdge != null)
{
Node tmp = v.firstEdge;
while (tmp != null)
{
s += tmp.adjvex.data.ToString();
tmp = tmp.next;
}
}
s += "\r\n";
}
return s;
}
//嵌套類,表示鏈表中的表結點
public class Node
{
public Vertex<T> adjvex; //鄰接點域
public Node next; //下一個鄰接點指針域
public Node(Vertex<T> value)
{
adjvex = value;
}
}
//嵌套類,表示存放於數組中的表頭結點
public class Vertex<TValue>
{
public TValue data; //數據
public Node firstEdge; //鄰接點鏈表頭指針
public Boolean visited; //訪問標志,遍歷時使用
public Vertex(TValue value) //構造方法
{
data = value;
}
}
}
AdjacencyList<T>類使用泛型實現了圖的鄰接表存儲結構。它包含兩個內部類,Vertex<Tvalue>類(109~118行代碼)用於表示一個表頭結點,Node類(99~107)則用於表示表結點,其中存放著鄰接點信息,用來表示表頭結點的某條邊。多個Node用next指針相連形成一個單鏈表,表頭指針為Vertex類的firstEdge成員,表頭結點所代表的頂點的所有邊的信息均包含在鏈表內,其結構如圖8.12所示。所不同之處在於:
l Vertex類中包含了一個visited成員,它的作用是在圖遍歷時標識當前節點是否被訪問過,這一點在稍後會講到。
l 鄰接點指針域adjvex直接指向某個表頭結點,而不是表頭結點在數組中的索引。
AdjacencyList<T>類中使用了一個泛型List代替數組來保存表頭結點信息(第5行代碼),從而不再考慮數組存儲空間不夠的情況發生,簡化了操作。
由於一條無向邊的信息需要在邊的兩個頂點分別存儲信息,即添加兩個有向邊,所以58~78行代碼的私有方法AddDirectedEdge()方法用於添加一個有向邊。新的鄰接點信息即可以添加到鏈表的頭部也可以添加到尾部,添加到鏈表頭部可以簡化操作,但考慮到要檢查是否添加了重復邊,需要遍歷整個鏈表,所以最終把鄰接點信息添加到鏈表尾部。
【例8-1 Demo8-1.cs】圖的鄰接表存儲結構測試
using System;
class Demo8_1
{
static void Main(string[] args)
{
AdjacencyList<char> a = new AdjacencyList<char>();
//添加頂點
a.AddVertex('A');
a.AddVertex('B');
a.AddVertex('C');
a.AddVertex('D');
//添加邊
a.AddEdge('A', 'B');
a.AddEdge('A', 'C');
a.AddEdge('A', 'D');
a.AddEdge('B', 'D');
Console.WriteLine(a.ToString());
}
}
運行結果:
A:BCD
B:AD
C:A
D:AB
本例存儲的表如圖8.12所示,結果中,冒號前面的是表頭結點,冒號後面的是鏈表中的表結點。
8.3 圖的遍歷
和樹的遍歷類似,在此,我們希望從圖中某一頂點出發訪遍圖中其余頂點,且使每一個頂點僅被訪問一次,這一過程就叫做圖的遍歷(TraversingGraph)。如果只訪問圖的頂點而不關注邊的信息,那麼圖的遍歷十分簡單,使用一個foreach語句遍歷存放頂點信息的數組即可。但如果為了實現特定算法,就需要根據邊的信息按照一定順序進行遍歷。圖的遍歷算法是求解圖的連通性問題、拓撲排序和求關鍵路徑等算法的基礎。
圖的遍歷要比樹的遍歷復雜得多,由於圖的任一頂點都可能和其余頂點相鄰接,故在訪問了某頂點之後,可能順著某條邊又訪問到了已訪問過的頂點,因此,在圖的遍歷過程中,必須記下每個訪問過的頂點,以免同一個頂點被訪問多次。為此給頂點附設訪問標志visited,其初值為false,一旦某個頂點被訪問,則其visited標志置為true。
圖的遍歷方法有兩種:一種是深度優先搜索遍歷(Depth-First Search 簡稱DFS);另一種是廣度優先搜索遍歷(Breadth_First Search 簡稱BFS)。
8.3.1深度優先搜索遍歷
圖的深度優先搜索遍歷類似於二叉樹的深度優先搜索遍歷。其基本思想如下:假定以圖中某個頂點Vi為出發點,首先訪問出發點,然後選擇一個Vi的未訪問過的鄰接點Vj,以Vj為新的出發點繼續進行深度優先搜索,直至圖中所有頂點都被訪問過。顯然,這是一個遞歸的搜索過程。
現以圖8.15為例說明深度優先搜索過程。假定V1是出發點,首先訪問V1。因V1有兩個鄰接點V2、V3均末被訪問過,可以選擇V2作為新的出發點,訪問V2之後,再找V2的末訪問過的鄰接點。同V2鄰接的有V1、V4和V5,其中V1已被訪問過,而V4、V5尚未被訪問過,可以選擇V4作為新的出發點。重復上述搜索過程,繼續依次訪問V8、V5 。訪問V5之後,由於與V5相鄰的頂點均已被訪問過,搜索退回到V8,訪問V8的另一個鄰接點V6。接下來依次訪問V3和V7,最後得到的的頂點的訪問序列為:V1 → V2 → V4 → V8 → V5 → V6 → V3 → V7。
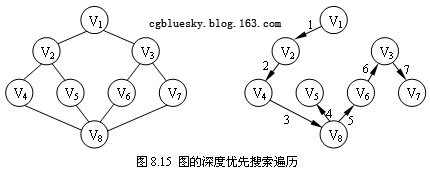
下面根據上一節創建的鄰接表存儲結構添加深度優先搜索遍歷代碼。
【例8-2 DFSTraverse.cs】深度優先搜索遍歷
打開【例8-1 AdjacencyList.cs】,在AdjacencyList<T>類中添加以下代碼後,將文件另存為DFSTraverse.cs。
35 public void DFSTraverse() //深度優先遍歷
36 {
37 InitVisited(); //將visited標志全部置為false
38 DFS(items[0]); //從第一個頂點開始遍歷
39 }
40 private void DFS(Vertex<T> v) //使用遞歸進行深度優先遍歷
41 {
42 v.visited = true; //將訪問標志設為true
43 Console.Write(v.data + " "); //訪問
44 Node node = v.firstEdge;
45 while (node != null) //訪問此頂點的所有鄰接點
46 { //如果鄰接點未被訪問,則遞歸訪問它的邊
47 if (!node.adjvex.visited)
48 {
49 DFS(node.adjvex); //遞歸
50 }
51 node = node.next; //訪問下一個鄰接點
52 }
53 }
98 private void InitVisited() //初始化visited標志
99 {
100 foreach (Vertex<T> v in items)
101 {
102 v.visited = false; //全部置為false
103 }
104 }
【例8-2 Demo8-2.cs】深度優先搜索遍歷測試
using System;
class Demo8_2
{
static void Main(string[] args)
{
AdjacencyList<string> a = new AdjacencyList<string>();
a.AddVertex("V1");
a.AddVertex("V2");
a.AddVertex("V3");
a.AddVertex("V4");
a.AddVertex("V5");
a.AddVertex("V6");
a.AddVertex("V7");
a.AddVertex("V8");
a.AddEdge("V1", "V2");
a.AddEdge("V1", "V3");
a.AddEdge("V2", "V4");
a.AddEdge("V2", "V5");
a.AddEdge("V3", "V6");
a.AddEdge("V3", "V7");
a.AddEdge("V4", "V8");
a.AddEdge("V5", "V8");
a.AddEdge("V6", "V8");
a.AddEdge("V7", "V8");
a.DFSTraverse();
}
}
運行結果:
V1 V2 V4 V8 V5 V6 V3 V7
本例參照圖8-15進行設計,運行過程請參照對圖8-15所作的分析。
8.3.2廣度優先搜索遍歷
圖的廣度優先搜索遍歷算法是一個分層遍歷的過程,和二叉樹的廣度優先搜索遍歷類同。它從圖的某一頂點Vi出發,訪問此頂點後,依次訪問Vi的各個未曾訪問過的鄰接點,然後分別從這些鄰接點出發,直至圖中所有已有已被訪問的頂點的鄰接點都被訪問到。對於圖8.15所示的無向連通圖,若頂點Vi為初始訪問的頂點,則廣度優先搜索遍歷頂點訪問順序是:V1 → V2 → V3 → V4 → V5 → V6 → V7 → V8。遍歷過程如圖8.16的所示。
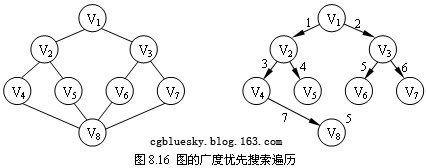
和二叉樹的廣度優先搜索遍歷類似,圖的廣度優先搜索遍歷也需要借助隊列來完成,例8.3演示了這個過程。
【例8-3 BFSTraverse.cs】廣度優先搜索遍歷
打開【例8-2 DFSTraverse.cs】,在AdjacencyList<T>類中添加以下代碼後,將文件另存為BFSTraverse.cs。
54 public void BFSTraverse() //廣度優先遍歷
55 {
56 InitVisited(); //將visited標志全部置為false
57 BFS(items[0]); //從第一個頂點開始遍歷
58 }
59 private void BFS(Vertex<T> v) //使用隊列進行廣度優先遍歷
60 { //創建一個隊列
61 Queue<Vertex<T>> queue = new Queue<Vertex<T>>();
62 Console.Write(v.data + " "); //訪問
63 v.visited = true; //設置訪問標志
64 queue.Enqueue(v); //進隊
65 while (queue.Count > 0) //只要隊不為空就循環
66 {
67 Vertex<T> w = queue.Dequeue();
68 Node node = w.firstEdge;
69 while (node != null) //訪問此頂點的所有鄰接點
70 { //如果鄰接點未被訪問,則遞歸訪問它的邊
71 if (!node.adjvex.visited)
72 {
73 Console.Write(node.adjvex.data + " "); //訪問
74 node.adjvex.visited = true; //設置訪問標志
75 queue.Enqueue(node.adjvex); //進隊
76 }
77 node = node.next; //訪問下一個鄰接點
78 }
79 }
80 }
【例8-3 Demo8-3.cs】廣度優先搜索遍歷測試
using System;
class Demo8_3
{
static void Main(string[] args)
{
AdjacencyList<string> a = new AdjacencyList<string>();
a.AddVertex("V1");
a.AddVertex("V2");
a.AddVertex("V3");
a.AddVertex("V4");
a.AddVertex("V5");
a.AddVertex("V6");
a.AddVertex("V7");
a.AddVertex("V8");
a.AddEdge("V1", "V2");
a.AddEdge("V1", "V3");
a.AddEdge("V2", "V4");
a.AddEdge("V2", "V5");
a.AddEdge("V3", "V6");
a.AddEdge("V3", "V7");
a.AddEdge("V4", "V8");
a.AddEdge("V5", "V8");
a.AddEdge("V6", "V8");
a.AddEdge("V7", "V8");
a.BFSTraverse(); //廣度優先搜索遍歷
}
}
運行結果:
V1 V2 V3 V4 V5 V6 V7 V8
運行結果請參照圖8.16進行分析。
8.3.3 非連通圖的遍歷
以上討論的圖的兩種遍歷方法都是相對於無向連通圖的,它們都是從一個頂點出發就能訪問到圖中的所有頂點。若無向圖是非連通圖,則只能訪問到初始點所在連通分量中的所有頂點,其他連通分量中的頂點是不可能訪問到的(如圖8.17所示)。為此需要從其他每個連通分量中選擇初始點,分別進行遍歷,才能夠訪問到圖中的所有頂點,否則不能訪問到所有頂點。為此同樣需要再選初始點,繼續進行遍歷,直到圖中的所有頂點都被訪問過為止。
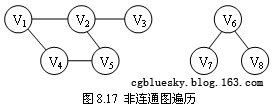
上例的代碼只需對DFSTraverse()方法和BFSTraverse()方法稍作修改,便可以遍歷非連通圖。
public void DFSTraverse() //深度優先遍歷
{
InitVisited(); //將visited標志全部置為false
foreach (Vertex<T> v in items)
{
if (!v.visited) //如果未被訪問
{
DFS(v); //深度優先遍歷
}
}
}
public void BFSTraverse() //廣度優先遍歷
{
InitVisited(); //將visited標志全部置為false
foreach (Vertex<T> v in items)
{
if (!v.visited) //如果未被訪問
{
BFS(v); //廣度優先遍歷
}
}
}