摘要:本文討論了如何使用C#2.0實現抓取網絡資源的網絡蜘蛛。使用這個程序,可以通過一個入口網址(如http://www.comprg.com.cn)來掃描整個互聯網的網址,並將這些掃描到的網址所指向的網絡資源下載到本地。然後可以利用其他的分析工具對這些網絡資源做進一步地分析,如提取關鍵詞、分類索引等。也可以將這些網絡資源作為數據源來實現象Google一樣的搜索引擎。
關鍵詞:C#2.0,Html,網絡蜘蛛, 鍵樹,正則表達式
一、引言
在最近幾年,以Google為首的搜索引擎越來越引起人們的關注。由於在Google出現之前,很多提供搜索服務的公司都是使用人工從網絡上搜集信息,並將這些信息分類匯總後作為搜索引擎的數據源。如yahoo公司一開始就是通過數千人不停地從網上搜集供查詢的信息。這樣做雖然信息的分類會很人性化,也比較准確,但是隨著互聯網信息爆炸式地增長,通過人工的方式來搜集信息已經不可能滿足網民對信息的需求了。然而,這一切隨著Google的出現而得到了徹底改變。Google一反常規的做法,通過程序7*24地從網上不停地獲取網絡資源,然後通過一些智能算法分析這些被下載到本地的網絡資源,最後將這些分析後的數據進行索引後就形成了一套完整的基本上不需要人工干預的搜索引擎。使用這種模式的搜索引擎甚至可以在幾天之內就可獲取Internet中的所有信息,同時也節省了大量的資金和時間成本。而這種搜索引擎最重要的組成部分之一就是為搜索引擎提供數據源的網絡蜘蛛。也就是說,實現網絡蜘蛛是實現搜索引擎的第一步,也是最重要的一步。
二、網絡蜘蛛的基本實現思想和實現步驟
網絡蜘蛛的主要作用是從Internet上不停地下載網絡資源。它的基本實現思想就是通過一個或多個入口網址來獲取更多的URL,然後通過對這些URL所指向的網絡資源下載並分析後,再獲得這些網絡資源中包含的URL,以此類推,直到再沒有可下的URL為止。下面是用程序實現網絡蜘蛛的具體步驟。
1. 指定一個(或多個)入口網址,並將這個網址加入到下載隊列中(這時下載隊列中只有一個或多個入口網址)。
2. 負責下載網絡資源的線程從下載隊列中取得一個或多個URL,並將這些URL所指向的網絡資源下載到本地(在下載之前,一般應該判斷一下這個URL是否已經被下載過,如果被下載過,則忽略這個URL)。如果下載隊列中沒有URL,並且所有的下載線程都處於休眠狀態,說明已經下載完了由入口網址所引出的所有網絡資源。這時網絡蜘蛛會提示下載完成,並停止下載。
3. 分析這些下載到本地的未分析過的網絡資源(一般為html代碼),並獲得其中的URL(如標簽中href屬性的值)。
4. 將第3步獲得的URL加入到下載隊列中。並重新執行第2步。
三、實現數據的輸入輸出
從實現網絡蜘蛛的步驟中我們可以看出,下載隊列的讀、寫URL的操作一直貫穿於整個系統中。雖然這個下載隊列可以用.Queue類實現,但是各位讀者要清楚地知道,在互聯網上的URL可不是幾十個、幾百個這麼少。而是以千萬計的。這麼多的URL顯然不能保存在內存中的Queue對象中。因此,我們需要將它保存在容量更大的存儲空間中,這就是硬盤。
本文采用了一個普通的文本文件來保存需要下載和分析的URL(這個文本文件也就是下載隊列)。存儲格式是每一行為一個URL。既然將URL都保存在了文本文件中,就需要對這個文本文件進行讀寫。因此,在本節實現了一個用於操作這個文本文件的FileIO類。
在實現FileIO類之前,先來說一下要如何操作這個文本文件。既然要將這個文件作為隊列使用,那麼就需要對這個文件進行追加行和從文件開始部分讀取數據操作。讓我們首先來實現向文件中追加行操作。實現代碼如下:
向文件中追加行的實現代碼
// 這兩個變量為類全局變量
private FileStream fsw;
private StreamWriter sw;
// 創建用於向文件中追加行的文件流和StreamWriter對象
public void OpenWriteFile(string file)
{
if (!File.Exists(file)) // 如果文件不存在,先創建這個文件
File.Create(file).Close();
// 以追加模式打開這個文件
fsw = new FileStream(file, FileMode.Append ,FileAccess.Write, FileShare.ReadWrite);
// 根據創建的FileStream對象來創建StreamWriter對象
sw = new StreamWriter(fsw);
}
// 關閉寫文件流
public void CloseWriteFile()
{
if (fsr != null)
fsw.Close();
}
// 向文件中追加一行字符串
public void WriteLine(string s)
{
sw.WriteLine(s);
sw.Flush(); // 刷新寫入緩沖區,使這一行對於讀文件流可見
}
在實現上述的代碼時要注意,在創建FileStream對象時,必須使用FileShare.ReadWrite,否則這個文件無法被兩個或兩個以上的Stream打開,也就是說下面要介紹的讀文件流將無法操作這個被寫文件流打開的文件。從文件中讀取行的實現代碼如下:
從文件中讀取行的實現代碼
// 這兩個變量為類全局變量
private FileStream fsr;
private StreamReader sr;
// 創建用於讀取文件行的文件流和StreamWriter對象
public void OpenReadFile(string file)
{
if (!File.Exists(file)) // 如果文件不存在,首先創建這個文件
File.Create(file).Close();
fsr = new FileStream(file, FileMode.OpenOrCreate, FileAccess.Read,
FileShare.ReadWrite);
sr = new StreamReader(fsr);
}
// 關閉讀文件流
public void CloseReadFile()
{
if(fsr != null)
fsr.Close();
}
// 從文件中讀取一行
public string ReadLine()
{
if(sr.EndOfStream) // 如果文件流指針已經指向文件尾部,返回null
return null;
return sr.ReadLine();
}
除了上述的讀寫文件的代碼外,FileIO還提供了一個IsEof方法用來判斷文件流指針是否位於文件尾部。IsEof方法的實現代碼如下如下:
IsEof方法的實現代碼
// 用於判斷文件流指針是否位於文件尾部
public bool IsEof()
{
return sr.EndOfStream;
}
FileIO類不僅僅用於對下載隊列的讀寫。在後面我們還會講到,網絡蜘蛛通過多線程下載網絡資源時,每一個線程將自己下載的網絡資源保存在屬於自己的一個目錄中。每個這樣的目錄都有一個index.txt文件,這個文件保存了當前目錄的網絡資源的URL。向index.txt文件中追加URL也用到了FileIO(index.txt不需要讀取,只需要不斷地追加行)。
四、線程類的實現
要想使網絡蜘蛛在有限的硬件環境下盡可能地提高下載速度。最廉價和快捷的方法就是使用多線程。在.net framework2.0中提供了豐富的線程功能。其中的核心線程類是Thread。一般可使用如下的代碼創建並運行一個線程:
在C#中使用線程的演示代碼
private void fun()
{
// 線程要執行的代碼
}
public void testThread()
{
Thread thread;
thread = new Thread(fun); // 創建一個Thread對象,並將fun設為線程運行的方法
thread.Start(); // 運行一個線程
}
雖然上面的代碼比較簡單地創建並運行了一個線程,但是這段代碼看起來仍然不夠透明,也就是客戶端在調用線程時仍然需要顯式地使用Thread類。下面我們來實現一個用於創建線程的MyThread類。C#中的任何類只需要繼承這個類,就可以自動變成一個線程類。MyThread類的代碼如下:
MyThread類的實現代碼
// 任何C#類繼承MyThread後,就會自動變成一個線程類
class MyThread
{
private Thread thread;
public MyThread()
{
thread = new Thread(run); // 創建Thread對象
}
// 用於運行線程代碼的方法,MyThread的子類必須覆蓋這個方法
public virtual void run()
{
}
public void start()
{
thread.Start(); // 開始運行線程,也就是開始執行run方法
}
// 使當前線程休眠millisecondsTimeout毫秒
public void sleep(int millisecondsTimeout)
{
Thread.Sleep(millisecondsTimeout);
}
}
我們可參照如下的代碼使用MyThread類:
測試的ThreadClass類的代碼
class ThreadClass : MyThread
{
public override void run()
{
// 要執行的線程代碼
}
}
// 測試ThreadClass類
public void testThreadClass()
{
ThreadClass tc = new ThreadClass();
tc.start(); // 開始運行線程,也就是執行run方法
}
各位讀者可以看看,上面的代碼是不是要比直接使用Thread類更方便、直觀、易用,還有些面向對象的感覺!
五、用多線程下載網絡資源
一般來說,網絡蜘蛛都是使用多線程來下載網絡資源的。至於如何使用多線程來下載,各個版本的網絡蜘蛛不盡相同。為了方便和容易理解,本文所討論的網絡蜘蛛采用了每一個線程負責將網絡資源下載到一個屬於自己的目錄中,也就是說,每一個線程對應一個目錄。而在當前目錄中下載的網絡資源達到一定的數目後(如5000),這個線程就會再建立一個新目錄,並從0開始計數繼續下載網絡資源。在本節中將介紹一個用於下載網絡資源的線程類DownLoadThread。這個類的主要功能就是從下載隊列中獲得一定數量的URL,並進行下載和分析。在DownLoadThread類中涉及到很多其他重要的類,這些類將在後面的部分介紹。在這裡我們先看一下DownLoadThread類的實現代碼。
DownLoadThread類的代碼
class DownLoadThread : MyThread
{
// ParseResource類用於下載和分析網絡資源
private ParseResource pr = new ParseResource();
private int currentCount = 0; // 當前下載目錄中的網頁數
// 用於向每個線程目錄中的index.txt中寫當前目錄的URL
private FileIO fileIO = new FileIO();
private string path; // 當前的下載目錄(後面帶“\")
private string[] patterns; // 線程不下載符合patterns中的正則表達式的URL
public bool stop = false; // stop為true,線程退出
public int threadID; // 當前線程的threadID,用於區分其他的線程
public DownLoadThread(string[] patterns)
{
pr.findUrl += findUrl; // 為findUrl事件賦一個方法
this.patterns = patterns;
}
// 這是一個事件方法,每獲得一個URL時發生
private void findUrl(string url)
{
Common.addUrl(url); // 將獲得的URL加到下載隊列中
}
private void openFile() // 打開下載目錄中的index.txt文件
{
fileIO.CloseWriteFile();
fileIO.OpenWriteFile(path + Common.indexFile);
}
public override void run() // 線程運行方法
{
LinkedList urls = new LinkedList();
path = Common.getDir(); // 獲得下載目錄
openFile();
while (!stop)
{
// 當下載隊列中沒有URL時,進行循環等待
while (!stop && urls.Count == 0)
{
Common.getUrls(urls, 20); // 從下載隊列中獲得20個url
if (urls.Count == 0) // 如果未獲得url
{
// 通知系統當前線程已處於等待狀態,
// 如果所有的線程都處於等待狀態,
// 說明所有的網絡資源都被下載完了
Common.threadWait(threadID);
sleep(5000); // 當前線程休眠5秒
}
}
StringBuilder sb = new StringBuilder();
foreach (string url in urls) // 循環對這20個url進行循環下載分析
{
if (stop) break;
// 如果當前下載目錄的資源文件數大於等於最大文件數目時,
// 建立一個新目錄,並繼續下載
if (currentCount >= Common.maxCount)
{
path = Common.getDir();
openFile();
currentCount = 0; // 目錄
}
// 每個下載資源文件名使用5位的順序號保存(沒有擴展名),
// 如00001、00002。下面的語句是格式化文件名
string s = string.Format("{0:D5}", currentCount + 1);
sb.Remove(0, sb.Length);
sb.Append(s);
sb.Append(":");
sb.Append(url);
try
{
// 下載和分析當前的url
pr.parse(url, path + s, patterns);
Common.Count++;
// 將當前的url寫入index.txt
fileIO.WriteLine(sb.ToString());
currentCount++;
}
catch (Exception e)
{
}
}
urls.Clear();
}
}
}
}
六、分析網絡資源
對下載的網絡資源進行分析是網絡蜘蛛中最重要的功能之一。這裡網絡資源主要指的是html代碼中標簽的href屬性值。狀態和狀態之間會根據從html文件中讀入的字符進行切換。下面是狀態之間切換的描述。
狀態0:讀入'<'字符後切換到狀態1,讀入其他的字符,狀態不變。
狀態1:讀入'a'或'A',切換到狀態2,讀入其他的字符,切換到狀態0。
狀態2:讀入空格或制表符(\t),切換到狀態3,讀入其他的字符,切換到狀態0。
狀態3:讀入'>',成功獲得一個,讀入其他的字符,狀態不變。為了更容易說明問題。在本文給出的網絡蜘蛛中只提取了html代碼中中的href屬性中的url。本文中所采用的分析方法是分步進行提取href。首先將html代碼中的標簽整個提出來。不包括和前面的字符,如comprg中只提取,而comprg將被忽略,因為這裡並沒有url。
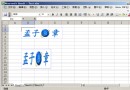
本文使用了一個狀態機來的提取,這個狀態機分為五個狀態(0 至 4)。第一個狀態是初始態,最後一個狀態為終止態,如果到達最後一個狀態,說明已經成功獲得了一個
狀態機如圖1所示。
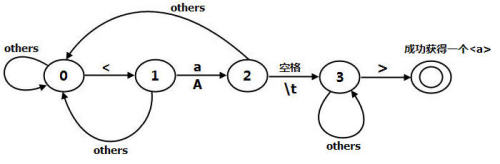
圖1
最後一個雙環的狀態是最終態。下面讓我們來看看獲得的實現代碼。
getA方法的實現
// 獲得html中的
private void getA()
{
char[] buffer = new char[1024];
int state = 0;
String a = "";
while (!sr.EndOfStream)
{
int n = sr.Read(buffer, 0, buffer.Length);
for (int i = 0; i < n; i++)
{
switch (state)
{
case 0: // 狀態0
if (buffer[i] == '<') // 讀入的是'<'
{
a += buffer[i];
state = 1; // 切換到狀態1
}
break;
case 1: // 狀態1
if (buffer[i] == 'a' || buffer[i] == 'A') // 讀入是'a'或'A'
{
a += buffer[i];
state = 2; // 切換到狀態2
}
else
{
a = "";
state = 0; // 切換到狀態0
}
break;
case 2: // 狀態2
if (buffer[i] == ' ' || buffer[i] == '\t') // 讀入的是空格或'\t'
{
a += buffer[i];
state = 3;
}
else
{
a = "";
state = 0; // 切換到狀態0
}
break;
case 3: // 狀態3
if (buffer[i] == '>') // 讀入的是'>',已經成功獲得一個
{
a += buffer[i];
try
{
string url = getUrl(getHref(a)); // 獲得中的href屬性的值
if (url != null)
{
if (findUrl != null)
findUrl(url); // 引發發現url的事件
}
}
catch (Exception e)
{
}
state = 0; // 在獲得一個後,重新切換到狀態0
}
else
a += buffer[i];
break;
}
}
}
}
在getA方法中除了切換到狀態0外,其他的狀態切換都將已經讀入的字符賦給String變量a,如果最後發現變量a中的字符串不可能是後,就將a清空,並切換到狀態0後重新讀入字符。
在getA方法中使用了一個重要的方法getHref來從中獲得href部分。getHref方法的實現如下:
getHref方法的實現
// 從中獲得Href
private String getHref(string a)
{
try
{
string p = @"href\s*=\s*('[^']*'|""[^""]*""|\S+\s+)"; // 獲得Href的正則表達式
MatchCollection matches = Regex.Matches(a, p,
RegexOptions.IgnoreCase |
RegexOptions.ExplicitCapture);
foreach (Match nextMatch in matches)
{
return nextMatch.Value; // 返回href
}
return null;
}
catch (Exception e)
{
throw e;
}
}
在getHref方法中使用了正則表達式從中獲得href。在中正確的href屬性格式有三種情況,這三種情況的主要區別是url兩邊的符號,如單引號、雙引號或沒有符號。這三種情況如下所示:
情況1:comprg
情況2:comprg
情況3:comprg
getHref方法中的p存儲了用於過濾這三種情況的href,也就是說,使用正則表達式可以獲得上述三種情況的href如下:
從情況1獲得得的href:href = "http://www.comprg.com.cn"
從情況2獲得得的href:href = 'http://www.comprg.com.cn'
從情況3獲得得的href:href = http://www.comprg.com.cn
在獲得上述的href後,需要將url提出來。這個功能由getUrl完成,這個方法的實現代碼如下:
getUrl方法的實現
// 從href中提取url
private String getUrl(string href)
{
try
{
if (href == null) return href;
int n = href.IndexOf('='); // 查找'='位置
String s = href.Substring(n + 1);
int begin = 0, end = 0;
string sign = "";
if (s.Contains("\"")) // 第一種情況
sign = "\"";
else if (s.Contains("'")) // 第二種情況
sign = "'";
else // 第三種情況
return getFullUrl(s.Trim());
begin = s.IndexOf(sign);
end = s.LastIndexOf(sign);
return getFullUrl(s.Substring(begin + 1, end - begin - 1).Trim());
}
catch (Exception e)
{
throw e;
}
}
在獲得url時有一點應該注意。有的url使用的是相對路徑,也就是沒有“http://host”部分,但將url保存時需要保存它們的完整路徑。這就需要根據相對路徑獲得它們的完整路徑。這個功能由getFullUrl方法完成。這個方法的實現代碼如下:
getFullUrl方法的實現代碼
// 將相對路徑變為絕對路徑
private String getFullUrl(string url)
{
try
{
if (url == null) return url;
if (processPattern(url)) return null; // 過濾不想下載的url
// 如果url前有http://或https://,為絕對路徑,按原樣返回
if (url.ToLower().StartsWith("http://") || url.ToLower().StartsWith("https://"))
return url;
Uri parentUri = new Uri(parentUrl);
string port = "";
if (!parentUri.IsDefaultPort)
port = ":" + parentUri.Port.ToString();
if (url.StartsWith("/")) // url以"/"開頭,直接放在host後面
return parentUri.Scheme + "://" + parentUri.Host + port + url;
else // url不以"/"開頭,放在url的路徑後面
{
string s = "";
s = parentUri.LocalPath.Substring(0, parentUri.LocalPath.LastIndexOf("/"));
return parentUri.Scheme + "://" + parentUri.Host + port + s + "/" + url;
}
}
catch (Exception e)
{
throw e;
}
}
在ParseResource中還提供了一個功能就是通過正則表達式過濾不想下載的url,這個功能將通過processPattern方法完成。實現代碼如下:
processPattern方法的實現代碼
// 如果返回true,表示url符合pattern,否則,不符合模式
private bool processPattern(string url)
{
foreach (string p in patterns)
{
if (Regex.IsMatch(url, p, RegexOptions.IgnoreCase | RegexOptions.ExplicitCapture)
&& !p.Equals(""))
return true;
}
return false;
}
ParseResource類在分析html代碼之前,先將html下載到本地的線程目錄中,再通過FileStream打開並讀取待分析的數據。ParseResource類其他的實現代碼請讀者參閱本文提供的源代碼。
七、鍵樹的實現
在獲取Url的過程中,難免重復獲得一些Url。這些重復的Url將大大增加網絡蜘蛛的下載時間,以及會導致其他的分析工具重復分析同一個html。因此,就需要對過濾出重復的Url,也就是說,要使網絡蜘蛛下載的Url都是唯一的。達到這個目的的最簡單的方法就是將已經下載過的Url保存到一個集合中,然後在下載新的Url之前,在這個集合中查找這個新的Url是否被下載過,如果下載過,就忽略這個Url。
這個功能從表面上看非常簡單,但由於我們處理的是成千上萬的Url,要是將這些Url簡單地保存在類似List一樣的集合中,不僅會占用大量的內存空間,而且當Url非常多時,如一百萬。這時每下載一個Url,就要從這一百萬的Url中查找這個待下載的Url是否存在。雖然可以使用某些查找算法(如折半查找)來處理,但當數據量非常大時,任何查找算法的效率都會大打折扣。因此,必須要設計一種新的存儲結構來完成這個工作。這個新的數據存儲結構需要具有兩個特性:
1. 盡可能地減少存儲Url所使用的內存。
2. 查找Url的速度盡可能地快(最好的可能是查找速度和Url的數量無關)。
下面先來完成第一個特性。一般一個Url都比較長,如平均每個Url有50個字符。如果有很多Url,每個Url占50個字符,一百萬個Url就是會占用50M的存儲空間。而我們保存Url的目的只有一個,就是查找某一個Url是否存在。因此,只需要將Url的Hashcode保存起來即可。由於Hashcode為Int類型,因此,Hashcode要比一個Url字符串使用更少的存儲空間。
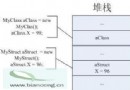
對於第二個特性,我們可以使用數據結構中的鍵樹來解決。假設有一個數是4532。首先將其轉換為字符串。然後每個鍵樹節點有10個(0至9)。這樣4532的存儲結構如圖2所示:
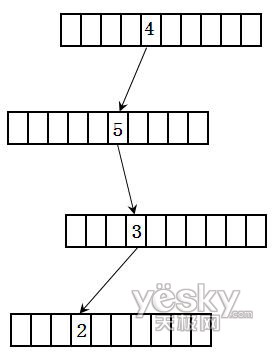
圖2
從上面的數據結構可以看出,查找一個整數只和這個整數的位數有關,和整數的數量無關。這個鍵樹的實現代碼如下:
KeyTree的實現代碼
class KeyTreeNode // 鍵樹節點的結構
{
// 指向包含整數下一個的結點的指針
public KeyTreeNode[] pointers = new KeyTreeNode[10];
// 結束位標志,如果為true,表示當前結點為整數的最後一位
public bool[] endFlag = new bool[10];
}
class KeyTree
{
private KeyTreeNode rootNode = new KeyTreeNode(); // 根結點
// 向鍵樹中添加一個無符號整數
public void add(uint n)
{
string s = n.ToString();
KeyTreeNode tempNode = rootNode;
int index = 0;
for (int i = 0; i < s.Length; i++)
{
index = int.Parse(s[i].ToString()); // 獲得整數每一位的值
if (i == s.Length - 1) // 在整數的最後一位時,將結束位設為true
{
tempNode.endFlag[index] = true;
break;
}
if (tempNode.pointers[index] == null) // 當下一個結點的指針為空時,新建立一個結點對象
tempNode.pointers[index] = new KeyTreeNode();
tempNode = tempNode.pointers[index];
}
}
// 判斷一個整數是否存在
public bool exists(uint n)
{
string s = n.ToString();
KeyTreeNode tempNode = rootNode;
int index = 0;
for (int i = 0; i < s.Length; i++)
{
if (tempNode != null)
{
index = int.Parse(s[i].ToString());
// 當整數的最後一位的結束標志為true時,表示n存在
if((i == s.Length - 1)&& (tempNode.endFlag[index] == true))
return true;
else
tempNode = tempNode.pointers[index];
}
else
return false;
}
return false;
}
}
上面代碼中的KeyTreeNode之所以要使用結束標志,而不根據指針是否為空判斷某個整數的存在,是因為可能存在長度不相等的整數,如4321和432。如果只使用指針判斷。保存4321後,432也會被認為存在。而如果用結束標志後,在值為2的節點的結束標志為false,因此,表明432並不存在。下面的UrlFilter使用了上面的鍵樹來處理Url。
UrlFilter類的實現代碼
// 用於將url重新組合後再加到鍵樹中
// 如http://www.comprg.com.cn和http://www.comprg.com.cn/是一樣的
// 因此,它們的hashcode也要求一樣
class UrlFilter
{
public static KeyTree urlHashCode = new KeyTree();
private static object syncUrlHashCode = new object();
private static string processUrl(string url) // 重新組合Url
{
try
{
Uri uri = new Uri(url);
string s = uri.PathAndQuery;
if(s.Equals("/"))
s = "";
return uri.Host + s;
}
catch(Exception e)
{
throw e;
}
}
private static bool exists(string url) // 判斷url是否存在
{
try
{
lock (syncUrlHashCode)
{
url = processUrl(url);
return urlHashCode.exists((uint)url.GetHashCode());
}
}
catch (Exception e)
{
throw e;
}
}
public static bool isOK(string url)
{
return !exists(url);
}
// 加處理完的Url加到鍵樹中
public static void addUrl(string url)
{
try
{
lock (syncUrlHashCode)
{
url = processUrl(url);
urlHashCode.add((uint)url.GetHashCode());
}
}
catch (Exception e)
{
throw e;
}
}
}
八、其他部分的實現
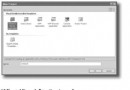
到現在為止,網絡蜘蛛所有核心代碼都已經完成了。下面讓我們做一個界面來使下載過程可視化。界面如圖3所示。
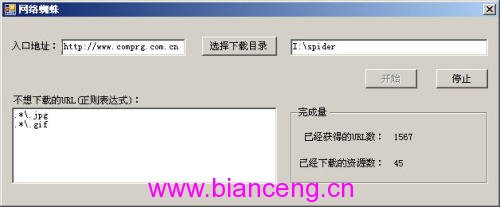
圖3
這個界面主要通過一個定時器每2秒鐘獲得個一次網絡蜘蛛的下載狀態。包括獲得的URL數和已經下載的網絡資源數。其中這些狀態信息都保存在一個Common類的靜態變量中。Common類和主界面的代碼請讀者參閱本文提供的源代碼。
九、結束語
至此,網絡蜘蛛程序已經全部完成了。但在實際應用中,光靠一台機器下載整個的網絡資源是遠遠不夠的。這就需要通過多台機器聯合下載。然而這就會給我們帶來一個難題。就是這些機器需要對已經下載的Url進行同步。讀者可以根據本文提供的例子,將其改成分布式的可多機同時下載的網絡蜘蛛。這樣網絡蜘蛛的下載速度將會有一個質的飛躍。