在Web應用程序中,對一個大數據庫結果集進行分頁已經是一個家喻戶曉的問題了。簡單的說,你不希望所有的查詢數據顯示在一個單獨的頁面中,所以帶有分頁的顯示才是更合適的。雖然在傳統的asp裡這並不是一個簡單的任務,但在asp.net中,DataGrid控件把這一過程簡化為只有幾行代碼。因此,在 ASP.net中,分頁很簡單,但是默認的DataGrid分頁事件會從數據庫中把所有的記錄全部讀出來放到ASP.Net web應用程序中。當你的數據在一百萬以上的時候,這將引起嚴重的性能問題(如果你不相信,你可以在你的應用程序中執行一個查詢,然後在任務管理器中查看 ASPnet_wp.exe的內存消耗情況)這也就是為什麼需要自定義分頁行為,這樣可以保證僅獲得當前頁需要的數據記錄。
在網上有很多關於這個問題的文章和帖子,還有一些成熟的解決方案。我寫這篇文章的目的不是向你展示一個可以解決一切問題的存儲過程,而是出於優化已有方法,同時為你提供一個可供測試的應用程序,這樣你就可以根據自己的需要進行開發。
但是我對目前網上介紹的方法不是很滿意。第一,使用了傳統的ADO,很明顯它們是為“古老”的ASP而寫的。剩下的一些方法就是SQL Server存儲過程,並且其中的一些由於相應時間過慢而無法使用,正如你在文章最後所看到的性能結果一樣,但是還是有一些引起了我的注意。
通用化
我要對對目前常用的三個方法進行仔細的分析,它們是臨時表(TempTable),動態SQL(DynamicSQL)和行計數 (Rowcount)。在下文中,我更願意把第二個方法稱為(升序-降序)Asc-Desc方法。我不認為動態SQL是一個好名字,因為你也可以把動態 SQL邏輯應用於另一個方法中。所有這些存儲過程的通病在於,你不得不估計哪些列是你即將要排序的,而不僅僅是估計主鍵列(PK Columns)而已,這可能導致一系列的問題——對於每個查詢來說,你需要通過分頁顯示,也就是說對於每不同的排序列你必須有許多不同的分頁查詢,這意味著你要麼給每個排序列做不同的存儲過程(無論使用哪種分頁方法),也麼你必須借助動態SQL的幫助把這個功能放在一個存儲過程中。這兩個方法對於性能有微小的影響,但是它增加了可維護性,特別是當你需要使用這個方法顯示不同的查詢。因此,在本文中我會嘗試使用動態SQL對所有的存儲過程進行歸納,但是由於一些原因,我們只能對實現部分的通用性,因此你還是得為復雜查詢寫獨立的存儲過程。
允許包括主鍵列在內的所有排序字段的第二個問題在於,如果那些列沒有作適當的索引,那麼這些方法一個也幫不上忙。在所有這些方法中,對於一個分頁源必須先做排序,對於大數據表來說,使用非索引列排序的成本是可以忽略不計的。在這種情況下,由於相應時間過長,所有的存儲過程都是無法在實際情況下使用的。(相應的時間各有不同,從幾秒鐘到幾分鐘不等,這要根據表的大小和所要獲得的第一個記錄而定)。其他列的索引會帶來額外的不希望出現的性能問題,例如如果你每天的導入數據很多,它有可能變得很慢。
臨時表
首先,我准備先來說一下臨時表方法,這是一個廣泛被建議使用的解決方案,我在項目中遇到過好幾次了。下面讓我們來看看這個方法的實質:
CREATE TABLE #Temp(
ID int IDENTITY PRIMARY KEY,
PK /*heregoesPKtype*/
)
INSERT INTO #Temp SELECT PK FROM Table ORDER BY SortColumn
SELECT FROM Table JOIN # Temp temp ON Table.PK = temp .PK ORDER BY temp .ID WHERE ID > @StartRow AND ID< @EndRow
通過把所有的行拷貝到臨時表中,我們可以對查詢進一步的優化(SELECT TOP EndRow …),但是關鍵在於最壞情況——一個包含100萬記錄的表就會產生一個100萬條記錄的臨時表。考慮到這樣的情況,再看看上面文章的結果,我決定在我的測試中放棄該方法
升序-降序
這個方法在子查詢中使用默認排序,在主查詢中使用反向排序,原理是這樣的:
DECLARE @temp TABLE(
PK /* PKType */
NOT NULL PRIMARY
)
INSERT INTO @temp SELECT TOP @PageSize PK FROM
(
SELECT TOP(@StartRow + @PageSize )
PK,
SortColumn /* If sorting column is defferent from the PK,SortColumn must
be fetched as well,otherwise just the PK is necessary
*/
ORDER BY SortColumn
/*
defaultorder–typicallyASC
*/
)
ORDER BY SortColumn
/*
reversed default order–typicallyDESC
*/
SELECT FROM Table JOIN @Temp temp ON Table .PK= temp .PK
ORDER BY SortColumn
/*
defaultorder
*/
行計數
這個方法的基本邏輯依賴於SQL中的SET ROWCOUNT表達式,這樣可以跳過不必要的行並且獲得需要的行記錄:
DECLARE @Sort /* the type of the sorting column */
SET ROWCOUNT @StartRow
SELECT @Sort=SortColumn FROM Table ORDER BY SortColumn
SET ROWCOUNT @PageSize
SELECT FROM Table WHERE SortColumn >= @Sort ORDER BY SortColumn
子查詢
還有兩個方法也是我考慮過的,他們的來源不同。第一個是眾所周知的三角查詢(Triple Query)或者說自查詢方法,在本文中,我也用一個類似的包含所有其他存儲過程的通用邏輯。這裡的原理是連接到整個過程中,我對原始代碼做了一些縮減,因
為recordcount在我的測試中不需要)
SELECT FROM Table WHERE PK IN(
SELECT TOP @PageSize PK FROM Table WHERE PK NOT IN
(
SELECT TOP @StartRow PK FROM Table ORDER BY SortColumn)
ORDER BY SortColumn)
ORDER BY SortColumn
游標
在看google討論組的時候,我找到了最後一個方法。該方法是用了一個服務器端動態游標。許多人試圖避免使用游標,因為游標沒有關系可言,以及有序性導致其效率不高,但回過頭來看,分頁其實是一個有序的任務,無論你使用哪種方法,你都必須回到開始行記錄。在之前的方法中,先選擇所有在開始記錄之前的所有行,加上需要的行記錄,然後刪除所有之前的行。動態游標有一個FETCH RELATIVE選項可以完成魔法般的跳轉。基本的邏輯如下:
DECLARE @PK /* PKType */
DECLARE @tblPK
TABLE(
PK /*PKType*/ NOT NULL PRIMARY KEY
)
DECLARE PagingCursor CURSOR DYNAMICREAD_ONLY FOR
SELECT @PK FROM Table ORDER BY SortColumn
OPEN PagingCursor
FETCH RELATIVE @StartRow FROM PagingCursor INTO @PK
WHILE @PageSize>0 AND @@FETCH_STATUS =0
BEGIN
INSERT @tblPK(PK) VALUES(@PK)
FETCH NEXT FROM PagingCursor INTO @PK
SET @PageSize = @PageSize - 1
END
CLOSE
PagingCursor
DEALLOCATE
PagingCursor
SELECT FROM Table JOIN @tblPK temp ON Table .PK= temp .PK
ORDER BY SortColumn
復雜查詢的通用化
我在之前指出,所有的存儲過程都是用動態SQL實現通用性的,因此,理論上它們可以用任何種類的復雜查詢。下面有一個基於Northwind數據庫的復雜查詢例子。
SELECT Customers.ContactName AS Customer, Customers.Address + ' , ' + Customers.City + ', '+ Customers.Country
AS Address, SUM([OrderDetails].UnitPrice*[ OrderDetails ] .Quantity)
AS [Totalmoneyspent]
FROM Customers
INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID
INNER JOIN [ OrderDetails ] ON Orders.OrderID = [ OrderDetails].OrderID
WHERE Customers.Country <> 'USA' AND Customers.Country <> 'Mexico '
GROUP BY Customers.ContactName,Customers.Address,Customers.City, Customers.Country
HAVING(SUM([OrderDetails].UnitPrice * [ OrderDetails ] .Quantity)) > 1000
ORDER BY Customer DESC ,Address DESC
返回第二個頁面的分頁存儲調用如下:
EXEC ProcedureName
/*Tables */
'
Customers
INNER JOIN Orders ON Customers.CustomerID=Orders.CustomerID
INNER JOIN [OrderDetails] ON Orders.OrderID=[OrderDetails].OrderID
'
,
/* PK */
'
Customers.CustomerID
'
,
/* ORDERBY */
'
Customers.ContactName DESC,Customers.AddressDESC
'
,
/*PageNumber */
2
,
/*PageSize */
10
,
/*FIElds */
'
Customers.Contact Name AS Customer,
Customers.Address+'' , '' +Customers.City+ '' , '' +Customers.Country ASAddress, SUM([OrderDetails].UnitPrice*[OrderDetails].Quantity)AS[Totalmoneyspent]
'
,
/*Filter */
'
Customers.Country<>'' USA '' ANDCustomers.Country<> '' Mexico ''' ,
/*GroupBy */
'
Customers.CustomerID,Customers.ContactName,Customers.Address,
Customers.City,Customers.Country
HAVING(SUM([OrderDetails].UnitPrice*[OrderDetails].Quantity))>1000
'
值得注意的是,在原始查詢中在ORDER BY語句中使用了別名,但你最好不要在分頁存儲過程中這麼做,因為這樣的話跳過開始記錄之前的行是很消耗時間的。其實有很多種方法可以用於實現,但原則是不要在一開始把所有的字段包括進去,而僅僅是包括主鍵列(等同於RowCount方法中的排序列),這樣可以加快任務完成速度。只有在請求頁中,才獲得所有需要的字段。並且,在最終查詢中不存在字段別名,在跳行查詢中,必須提前使用索引列。
行計數(RowCount)存儲過程有一個另外的問題,要實現通用化,在ORDER BY語句中只允許有一個列,這也是升序-降序方法和游標方法的問題,雖然他們可以對幾個列進行排序,但是必須保證主鍵中只有一個字段。我猜如果用更多的動態SQL是可以解決這個問題的,但是在我看來這不是很值得。雖然這樣的情況很有可能發生,但他們發生的頻率不是很高。通常你可以用上面的原理也獨立的分頁存儲過程。
性能測試
在測試中,我使用了四種方法,如果你有更好的方法的話,我很有興趣知道。不管如何,我需要對這些方法進行比較,並且評估它們的性能。首先我的第一個想法就是寫一個ASP.Net包含分頁DataGrid的測試應用程序,然後測試頁面結果。當然,這無法反映存儲過程的真實響應時間,所以控制台應用程序顯得更加適合。我還加入了一個Web應用程序,但不是為了性能測試,而是一個關於DataGrid自定義分頁和存儲過程一起工作的例子。
在測試中,我使用了一個自動生成得大數據表,大概插入了500000條數據。如果你沒有一張這樣的表來做實驗,你可以點擊這裡下載一段用於生成數據的表設計和存儲過程腳本。我沒有使用一個自增的主鍵列,而是用一個唯一識別碼來識別記錄的。如果我使用上面提到的腳本,你可能會考慮在生成表之後添加一個自增列,這些自增數據會根據主鍵進行數字排序,這也意味著你打算用一個帶有主鍵排序的分頁存儲過程來獲得當前頁的數據。
為了實現性能測試,我是通過一個循環多次調用一個特定的存儲過程,然後計算平均相應時間來實現的。考慮到緩存的原因,為了更准確地建模實際情況——同一頁面對於一個存儲過程的多次調用獲得數據的時間通常是不適合用來做評估的,因此,我們在調用同一個存儲過程時,每一次調用所請求的頁碼應該是隨機的。當然,我們必須假設頁的數量是固定的,10-20頁,不同頁碼的數據可能被獲取很多次,但是是隨機獲取的。
有一點我們很容易注意到,相應時間是由要獲取的頁數據相對於結果集開始的位置的距離決定的,越是遠離結果集的開始位置,就有越多的記錄要跳過,這也是我為什麼不把前20也包括進我的隨機序列的原因。作為替換,我會使用2的n次方個頁面,循環的大小是需要的不同頁的數量*1000,所以,每個頁面幾乎都被獲取了1000次(由於隨機原因,肯定會有所偏差)
結果
這裡有我的測試結果: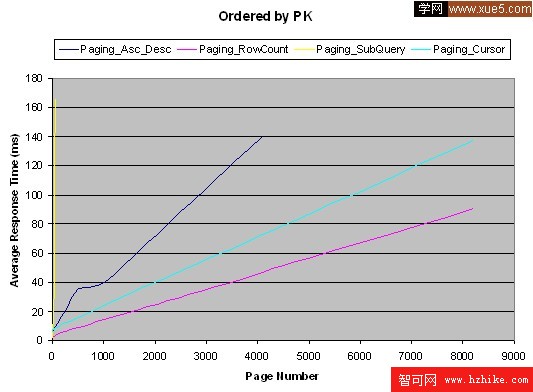
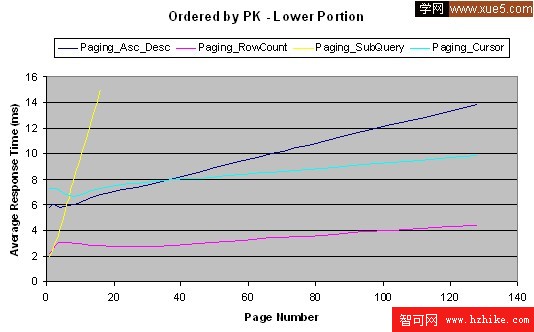
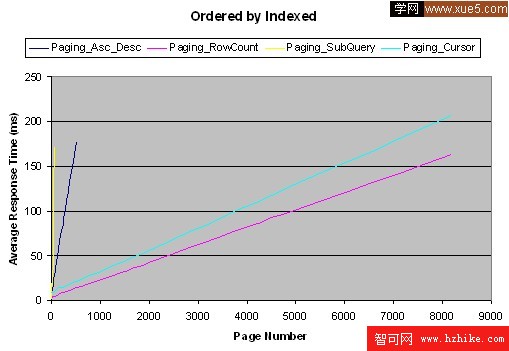
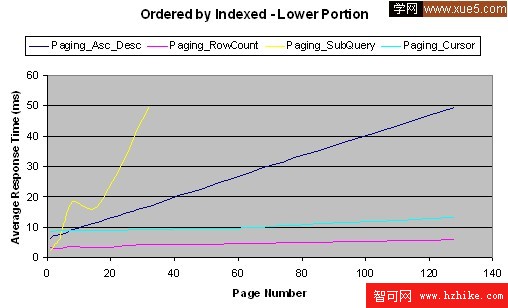
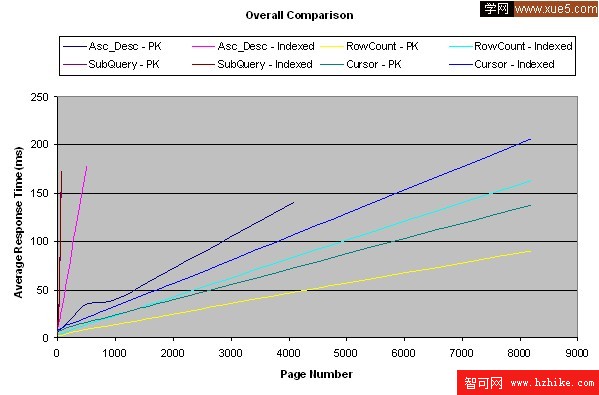
結論
測試是按照從性能最好到最差的順序進行的——行計數、游標、升序-降序、子查詢。有一件事很有趣,通常人們很少會訪問前五頁之後的頁面,因此子查詢方法可能在這種情況下滿足你的需要,這得看你的結果集的大小和對於遠距離(distant)頁面的發生頻率預測,你也很有可能使用這些方法的組合模式。如果是我,在任何情況下,我都更喜歡用行計數方法,它運行起來十分不錯,即使對於第一頁也是如此,這裡的“任何情況”代表了一些很難實現通用化的情況,在這種情況下,我會使用游標。(對於前兩種我可能使用子查詢方法,之後再用游標方法)






