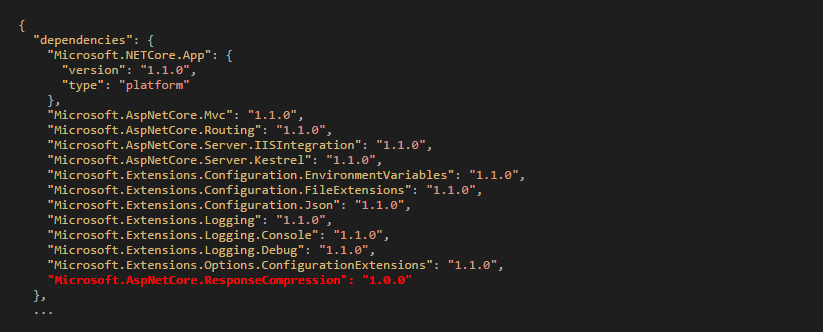
黑帽(black hat)SEO主要是指采取“不怎麼道德”(暫時就這麼形容吧!)的方式進行搜索引擎優化。
1. 注入攻擊,包括Sql注入和Html注入。我經常能看到對Sql注入防范的談論,但對於Html注入,很多人並沒有引起足夠的重視。為了展示Html注入的效果,我們模仿了一個常見的留言本功能。
首先,在頁面聲明中添加兩個屬性設置EnableEventValidation=“false” ValidateRequest=“false” ,這很關鍵,讀者可以試一下如果不這樣設置會有什麼效果。
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.ASPx.cs" Inherits="_Default" EnableEventValidation="false" ValidateRequest="false" %>然後,前台頁面和後台代碼段分別如下:
<ASP:TextBox ID="txtInput" runat="server" Height="95px" Width="405px" TextMode="MultiLine"></ASP:TextBox>程序很簡單,將用戶輸入的內容再顯示出來而已。運行代碼,然後輸入我們的惡意代碼,提交。
<p>Sanitizing <img src=""INVALID-IMAGE" onerror='location.href="http://too.much.spam/"'>!</p>我們會發現頁面自動跳轉到http://too.much.spam/頁面!這就是所謂的“Html注入”。當page頁面render到客戶端後,浏覽器會按一個普通的Html頁面進行解析;當解析到上面的JS代碼時……
為了避免這種入侵,在ASP.Net中,我們最簡單的處理方式就是對輸入的內容進行“Html編碼”。將後台代碼改為:
protected void btnSubmit_Click(object sender, EventArgs e)現在我們再運行代碼,發現源代碼被原樣輸出顯示在頁面,並沒有運行。為什麼呢?查看輸出頁面的源代碼:
<span id="lblShow"><p>Sanitizing <img src=""INVALID-IMAGE" onerror='location.href="http://too.much.spam/"'>!</p></span>
整理後,我們發現如下的映射轉換:
< -- < (less than)
> -- > (greater than)
" -- " (quota)
所以js無法執行,但在頁面顯示時,我們確能看到“原汁原味”的JS內容。
但問題並沒有結束,現實世界中,輸入的內容除了惡意代碼以外,還可能有如下的內容:
<span >黑帽</span>(black hat)SEO主要是指采取<span >“不怎麼道德”</span>(暫時就這麼形容吧!)的方式進行搜索引擎優化。我們希望顯示藍色的文字,但經過編碼後,顯然無法達到我們的效果。為此,我們還需要進行更精確的過濾。這也是為什麼之前我們要設置EnableEventValidation=“false” ValidateRequest=“false”的現實原因。
其實我最先想到的方案是:首先對整個內容進行編碼,然後把我們允許使用的Html標簽再替換回來。這樣是相當保險的,但是在具體的操作中,遇到了很多問題,這個郁悶啊~~~(如果有誰有這種實現的實現代碼,千萬要拿出來大家分享一下呀)。
我先介紹另一種方案:
首先要取出標簽,如,<span style=“ color:blue”>、</span>和<script >,我們的替換范圍僅局限於標簽 < > 之間的內容。
然後獲取所有的標簽名稱、屬性的名稱和值,如果有禁止出現的內容,就替換掉。可能的惡意代碼形式如下所示:
標簽的名稱: <script </script
標簽裡的屬性:<span onclick
屬性的值:<img onerror=“Javascript:'
最後,我們對所有的“惡意單詞”進行替換:
using System;注意代碼中兩處正則表達式的高級用法,貪婪模式和正向預查,詳細可參考貪婪模式和正向預查
這裡我們就可以看到正則表達式說起到的強大作用——操作字符串的無上利器啊!
2. 除了注入攻擊,另一種必須使用的技術是nofollow。因為Google的鏈接價值算法,我們都希望能有高價值的鏈接能指向我們的網站,以提高我們網站的等級。一種簡單的方式就是到其他網站(如新浪)申請一個博客,然後在博客裡添加一條鏈接,指向自己的網站即可。但如果我們自己是新浪,我們當然不願意有其他人這樣做(畢竟我們不知道其他人鏈接指向的網站究竟是好是壞,如果是一個垃圾網站,會牽連到我們自己的)。但是呢,我們也不願意完全禁止掉鏈接的使用(比如簡單的對鏈接進行編碼,讓鏈接失去作用),因為畢竟很多鏈接或許只是內部鏈接,而且一個能直接點擊的鏈接能帶來更好的用戶體驗。
為了解決這個問題,Google給出了一個方法,在鏈接中加上關鍵字nofollow,如下所示:
<a rel=“nofollow” href=“http://too.much.spam”>cool link</a>
這樣,鏈接能直接點擊,但不會帶來鏈接價值——即Google不會認為你認可或推薦了該鏈接指向的網站。看看博客園有沒有這樣做,……,呵呵,好像沒有,很大度喲。不過據說Google也會逐步降低鏈接價值的作用,謠言了,隨他去吧……
就直接上代碼了:
using System;
using System.Text.RegularExpressions;
/// <summary>
/// NoFollow contains the functionality to add rel=nofollow to unstusted links
/// </summary>
public static class NoFollow
{
// the white list of domains (in lower case)
private static string[] whitelist =
{ "SEOASP", "www.SEOegghead.com", "www.cristiandarIE.ro" };
// finds all the links in the input string and processes them using fixLink
public static string FixLinks(string input)
{
// define the match evaluator
MatchEvaluator fixThisLink = new MatchEvaluator(NoFollow.fixLink);
// fix the links in the input string
string fixedInput = Regex.Replace(input,
"(<a.*?>)",
fixThisLink,
RegexOptions.IgnoreCase);
// return the "fixed" input string
return fixedInput;
}
// receives a Regex match that contains a link such as
// <a href="http://too.much.spam/"> and adds ref=nofollow if needed
private static string fixLink(Match linkMatch)
{
// retrIEve the link from the received Match
string singleLink = linkMatch.Value;
// if the link already has rel=nofollow, return it back as it is
if (Regex.IsMatch(singleLink,
@"rel\s*?=\s*?['""]?.*?nofollow.*?['""]?",
RegexOptions.IgnoreCase))
{
return singleLink;
}
// use a named group to extract the URL from the link
Match m = Regex.Match(singleLink,
@"href\s*?=\s*?['""]?(?<url>[^'""]*)['""]?",
RegexOptions.IgnoreCase);
string url = m.Groups["url"].Value;
// if URL doesn't contain http://, assume it's a local link
if (!url.Contains("http://"))
{
return singleLink;
}
// extract the host name (such as www.cristiandarIE.ro) from the URL
Uri uri = new Uri(url);
string host = uri.Host.ToLower();
// if the host is in the whitelist, don't alter it
if (Array.IndexOf(whitelist, host) >= 0)
{
return singleLink;
}
// if the URL already has a rel attribute, change its value to nofollow
string newLink = Regex.Replace(singleLink,
@"(?<a>rel\s*=\s*(?<b>['""]?))((?<c>[^'""\s]*|[^'""]*))(?<d>['""]?)?",
"${a}nofollow${d}",
RegexOptions.IgnoreCase);
// if the string had a rel attribute that we changed, return the new link
if (newLink != singleLink)
{
return newLink;
}
// if we reached this point, we need to add rel=nofollow to our link
newLink = Regex.Replace(singleLink, "<a", @"<a rel=""nofollow""",
RegexOptions.IgnoreCase);
return newLink;
}
}