開發學習之.Net中PE文件的結構。在我們使用了任何支持CLR的語言來創建了源代碼文件之後,無論使用什麼編譯器,編譯出的文件都是一個托管模塊(managed module),這個托管模塊可以在CLR上運行。所以,我們把這種文件稱為托管可執行文件(Managed Executable File)。關於通用PE文件的格式已經在筆記三中間記錄了,這裡只記錄一些托管文件自身比較有特色的部分。
托管執行文件的重要組成部分
1.CLR Header
我們知道,在PE頭中,包含一個數據目錄表(Data Directory Table),這個表的第15項就是一個包含了CLR頭的RVA和大小,可以通過它找到CLR Header。簡單記錄一下CLR Header中的幾個主要的字段:
(1)Flags
這是一個二進制的標記,其可選值包括:
A.COMIMAGE_FLAGS_ILONLY (0x00000001) 文件中只包含純的IL代碼,未嵌入任何Native Code(除了DOS Stub,這個stub會被所有能夠識別CLR的系統忽略掉)。
B.COMIMAGE_FLAGS_32BITREQUIRED (0x00000002) 文件只能被加載到32位的進程空間中。
C.COMIMAGE_FLAGS_STRONGNAMESIGNED (0x00000008) 文件受到強名稱簽名的保護
(2)EntryPointToken
這是一個指明了此PE文件入口點的元數據標志符(MeteData IdentifIEr),它指向一個方法定義或者文件引用,而指向文件引用的唯一可能是:一個多模塊程序集的入口點不在其主模塊中,那麼主模塊裡的入口點標記指向包含入口點的模塊文件。入口點只能出現在可執行文件裡,如果你的代碼裡不包含入口點,IL匯編器會拒絕為你編譯EXE文件。但對於非可執行文件,卻分為兩種情況:如果程序是一個純的托管程序,則不需要入口點;如果程序中即包含IL代碼又包含機器碼(由MC++編譯器和鏈接器生成),則必須把DLLMain()作為入口點函數,它要對程序集裡的非托管代碼進行一些必要的初始化操作。
(3)VTableFixups
要理解這個字段,首先要理解v-table的概念。這是我摘了一個老外的描述,應該很精確,“Certain languages, which choose not to follow the common type system runtime model, may have virtual functions which need to be represented in a v-table. These v-tables are laid out by the compiler, not by the runtime. Finding the correct v-table slot and calling indirectly through the value held in that slot is also done by the compiler”。v-table是為虛方法調用服務的,而VTableFixups包含了一組v-table的地址和大小。
根據筆者當前的認識,v-table只有在此托管文件需要和非托管環境交互的時候才有用(比如這個托管代碼要被一個非托管環境調用),在純的托管環境下可能是沒用的。當然,大家都知道C#作為典型的OO語言,也有虛函數的概念,但它的虛函數實現機制和C++中的v-table的實現方式有什麼不同,我暫時還不清楚。
2.文本段(.Text section)
整個CLR Header是放置在一個文本段中的。這是一個只讀的段,包含了元數據表、IL代碼、引入表等,整個結構如下圖所示:
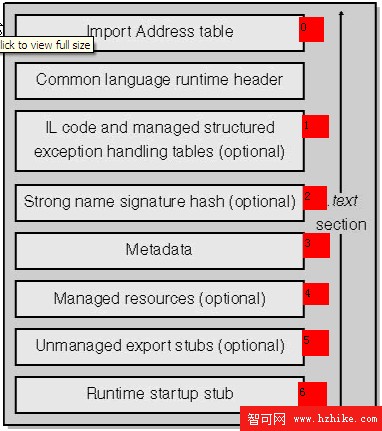
這個段裡的各個部分並非同時生成的,上圖用帶序號的方框來提示這一點,序號低的先生成。
3.資源
在托管文件中可以嵌入兩種不同類型的資源:非托管的平台相關的資源,或者托管資源。這兩種資源存儲在PE文件的不同section裡(其中托管資源已經在上面的文本段內出現過了,不是嗎?),其中非托管資源被放在一個單獨的.rsrc段裡,而托管資源放在文本段裡。
需要注意的是,IL匯編器在每個托管可執行文件中只能嵌入一個資源文件(.RES)。IL反匯編器會定位到這個section,然後把section中的所有內容作為一個.RES文件釋放出來。
三.元數據的結構
使用過.Net的Reflection功能的人對元數據可能多少都有點概念,它是對整個托管模塊的邏輯結構的完整描述,包含了所有在模塊中聲明和引用的元素。從結構上來說,所有元數據類似於一個關系數據庫,裡面的數據體現為一組交叉引用的表(而不是樹或者什麼其他數據結構),並且任何數據都只有一份(其他用到這個數據的位置都將包含一個指向此數據的引用)。從用途上來說,這些表分為三類:定義表(definition table)、引用表(reference table)和清單表(manifest table)。
整個元數據是一個二進制的數據塊,你只能通過工具來查看已生成程序集的元數據信息,如ildasm.exe(你可以在“視圖”菜單裡找到關於元數據信息顯示的命令)。
(1)元數據結構概覽
下面貼出來的顯示信息,是我用ildasm.exe統計了自己寫的一個很小的Demo程序中的元數據信息,先放在這裡,可以和後面提到的內容相互參考:
CLR meta-data size : 1260可以看到,在元數據中除了上面我們提到的那些表以外,還有一些用於記錄UserString,Guid的堆數據,後面會提到。
(2)元數據中的父子關系
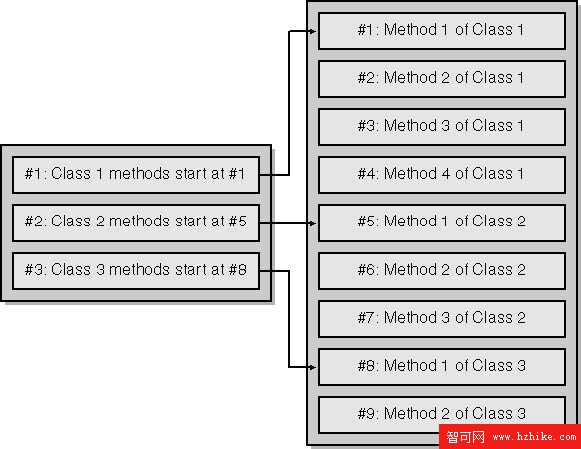
元數據中包含很多“父子關系”,如“類--方法”、“方法--參數”等等。如果你想找到和某個父數據對應的所有子數據,遍歷這個子數據所在的表可是個糟糕的選擇。事實上,對於這種一對多關系,匯編器在構造元數據表的時候,並不僅僅使用數據間的引用關系,而且使用了數據的排列順序來幫助定位。每個父數據都只含有一個指向其第一個子數據的引用,其子數據的結尾靠下一個父數據的起始引用來定位。這就要求子數據要依照他們的父數據來排序(符合這種條件的元數據被稱為“優化的”、“壓縮的”元數據,而IL匯編器一般都是生成這種元數據)。下圖是書中給出的class-method父子關系的元數據表示意圖:
(3)元數據結構
前面曾經提到過,元數據其實就是一個二進制的數據塊,所以元數據的內部,就是一個個的named stream。這些stream又分為兩種類型,除了前面提到過的Table,還有一類是以Heap的形式體現(見上文代碼段中的注釋)。下圖是書中給出的一個完整的元數據結構圖:
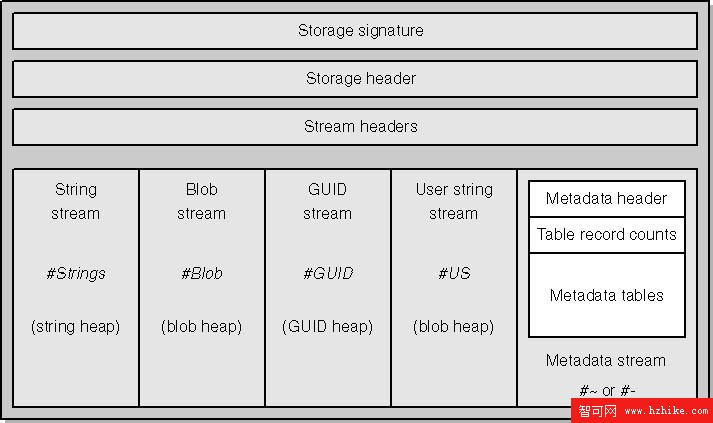
上面以#開頭的就是元數據中可能出現的6個命名流,他們的用途分別是
#Strings:用來存儲元數據項的名字,如類名、方法名等 //Heap Stream
#Blob: 用來存儲一些內部的對象實例,如默認值什麼的 //Heap Stream
#US: 用戶定義的字符串常量 //Heap Stream
#GUID: 包含各種全局統一標志符 //Heap Stream
#~: “優化的”、“壓縮的”元數據,裡面的元數據表以優化方式存儲(我們在父子關系中剛剛提到過的) //Table Stream
#-: 非優化的元數據(和#~不能共存) //Table Stream
其中(#~或#-)、#GUID、#Strings是必不可少的。
另外,元數據既然被存儲在很多表裡,那麼CLR是如何定位一個元數據項的呢(怎麼樣定位到某個表的某一行)?這裡,它使用了一種叫做Token的機制,每個token占4個字節,其中高位字節表示表序號,剩余三個字節表示表內的行序號。具體這些序號被稱為RID(record index),其中行序號從1開始,表序號從0開始。