我們知道linq是一個很古老的東西,大家也知道,自從用了linq,我們的foreach少了很多,但有一個現實就是我們在實際應用中使用到的卻是屈指可數
的幾個方法,這個系列我會帶領大家看遍linq,好的,廢話不多說,先從Aggregate這個貂毛說起。
一:應用場景
前不久在寫一個項目的時候,我需要撈取營銷活動,剛好營銷活動有兩個類型,一種是普通活動,一個是觸發式活動,由於存放在兩張表中,並且撈取
之後需要做一些實體的轉存,等等計算,所以就有了類似這樣的代碼。
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
Dictionary<int, List<Marketing>> dic = new Dictionary<int, List<Marketing>>();
//普通活動
if (!dic.ContainsKey(1))
dic[1] = new List<Marketing>();
dic[1].Add(new Marketing() { MarketingID = 1, MarketingName = "普通活動1" });
dic[1].Add(new Marketing() { MarketingID = 1, MarketingName = "普通活動2" });
//事件活動
if (!dic.ContainsKey(2))
dic[2] = new List<Marketing>();
dic[2].Add(new Marketing() { MarketingID = 3, MarketingName = "事件活動1" });
dic[2].Add(new Marketing() { MarketingID = 4, MarketingName = "事件活動2" });
}
}
class Marketing
{
public int MarketingID { get; set; }
public string MarketingName { get; set; }
}
}
然後我經過一系列運算之後,又需要把字典中的key=1和key=2的數據扁平到一個list中,那麼這個簡單的計算該怎麼做到呢???
普通的做法: 需要先定義一個List變量,然後一個foreach搞定。
List<Marketing> marketingList = new List<Marketing>();
foreach (var key in dic.Keys)
{
marketingList.AddRange(dic[key]);
}
如果你不會用Aggregate的話,你會覺得這個方法已經非常極致了。。。而事實呢???我們應該還有更牛逼的做法!!!
牛逼的做法:
var marketingList = dic.Keys.Aggregate(Enumerable.Empty<Marketing>(), (total, next) =>
{
return total.Union(dic[next]);
});
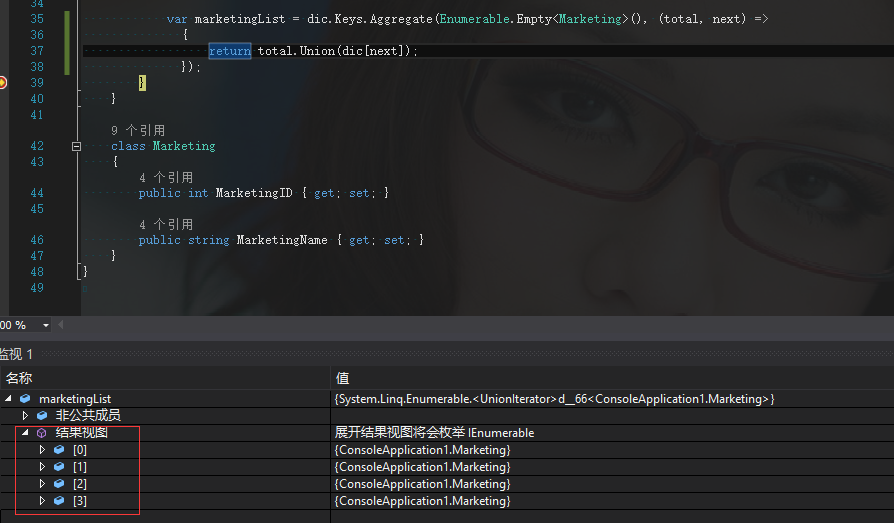
有沒有看到,用lamda這種寫法多麼的連貫,沒有第一種寫法上的斷層,當然很多框架上都有Aggregate這種聚合計算,比如mongodb中同樣也有
Aggregate,下面我們用ILSpy看看Aggregate這種魔法化的代碼是怎麼實現的。
二:探究源碼
當你看到源碼的時候,是不是有一種亮瞎眼的感覺,所謂的Aggregate在內部其實也僅僅是“普通做法”一模一樣的源代碼。。。而Aggregate僅僅做的
是一層代碼封裝,這樣也好,提高了我們開發效率,對吧,如下圖:
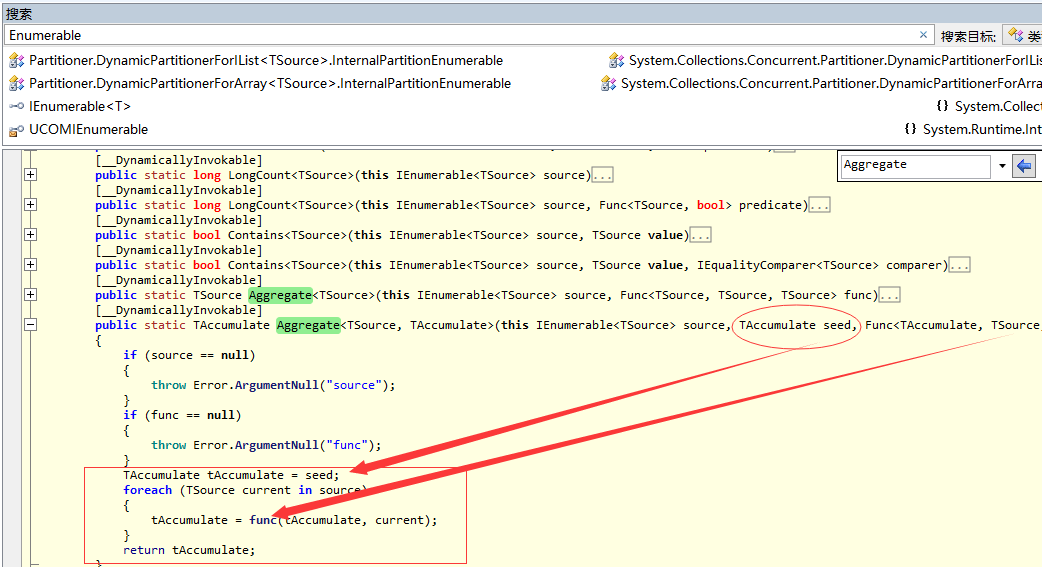
從圖中我們看到了Aggregate有三種重載方法,本篇剛好用到的是第二種重載,第一種看起來就更簡單了,對吧,更何況我們有ILSpy,歡迎大家自行
探索,本篇就說到這裡了,感謝支持~~~
————————————————————————————————————————————————————————————
————————————————————————————————————————————————————————————
友情提示:如果不喜歡看文章,可以移步本系列的 完整版Linq視頻教程 【一包煙的錢哦 】
】
————————————————————————————————————————————————————————————
————————————————————————————————————————————————————————————