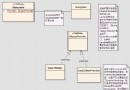
監聽器初始化Job,JobTracker相應TaskTracker心跳,調度器分配task的源碼級分析
JobTracker和TaskTracker分別啟動之後(JobTracker啟動流程源碼級分析,TaskTracker啟動過程源碼級分析),taskTracker會通過心跳與JobTracker通信,並獲取分配它的任務。用戶將作業提交到JobTracker之後,放入相應的數據結構中,靜等被分配。mapreduce job提交流程源碼級分析(三)這篇文章已經分析了用戶提交作業的最後步驟,主要是構造作業對應的JobInProgress並加入jobs,告知所有的JobInProgressListener。
默認調度器創建了兩個Listener:JobQueueJobInProgressListener和EagerTaskInitializationListener,用戶提交的作業被封裝成JobInProgress job加入這兩個Listener。
一、JobQueueJobInProgressListener.jobAdded(job)會將此JobInProgress放入Map<JobSchedulingInfo, JobInProgress> jobQueue中。
二、EagerTaskInitializationListener.jobAdded(job)會將此 JobInProgress放入List<JobInProgress> jobInitQueue中,然後調用resortInitQueue()對這個列表進行排序先按優先級相同則按開始時間;然後喚醒在此對象監視器上等待的所有線程jobInitQueue.notifyAll()。EagerTaskInitializationListener.start()方法已經在調度器start時運行,會創建一個線程JobInitManager implements Runnable,它的run方法主要是監控jobInitQueue列表,一旦發現不為空就獲取第一個JobInProgress,然後創建一個 InitJob implements Runnable初始化線程並放入線程池ExecutorService threadPool(這個線程池在構建EagerTaskInitializationListener對象時由構造方法實現),InitJob線程的 run方法就一句話ttm.initJob(job),調用的是JobTracker的initJob(job)方法對JIP進行初始化,實際調用 JobInProgress.initTasks()對job進行初始化,initTasks()方法代碼如下:
/**
* Construct the splits, etc. This is invoked from an async
* thread so that split-computation doesn't block anyone.
*/
//任務Task分兩種: MapTask 和reduceTask,它們的管理對象都是TaskInProgress 。
public synchronized void initTasks()
throws IOException, KillInterruptedException, UnknownHostException {
if (tasksInited || isComplete()) {
return;
}
synchronized(jobInitKillStatus){
if(jobInitKillStatus.killed || jobInitKillStatus.initStarted) {
return;
}
jobInitKillStatus.initStarted = true;
}
LOG.info("Initializing " + jobId);
final long startTimeFinal = this.startTime;
// log job info as the user running the job
try {
userUGI.doAs(new PrivilegedExceptionAction<Object>() {
@Override
public Object run() throws Exception {
JobHistory.JobInfo.logSubmitted(getJobID(), conf, jobFile,
startTimeFinal, hasRestarted());
return null;
}
});
} catch(InterruptedException ie) {
throw new IOException(ie);
}
// log the job priority
setPriority(this.priority);
//
// generate security keys needed by Tasks
//
generateAndStoreTokens();
//
// read input splits and create a map per a split
//
TaskSplitMetaInfo[] splits = createSplits(jobId);
if (numMapTasks != splits.length) {
throw new IOException("Number of maps in JobConf doesn't match number of " +
"recieved splits for job " + jobId + "! " +
"numMapTasks=" + numMapTasks + ", #splits=" + splits.length);
}
numMapTasks = splits.length;//map task的個數就是input split的個數
// Sanity check the locations so we don't create/initialize unnecessary tasks
for (TaskSplitMetaInfo split : splits) {
NetUtils.verifyHostnames(split.getLocations());
}
jobtracker.getInstrumentation().addWaitingMaps(getJobID(), numMapTasks);
jobtracker.getInstrumentation().addWaitingReduces(getJobID(), numReduceTasks);
this.queueMetrics.addWaitingMaps(getJobID(), numMapTasks);
this.queueMetrics.addWaitingReduces(getJobID(), numReduceTasks);
maps = new TaskInProgress[numMapTasks]; //為每個map tasks生成一個TaskInProgress來處理一個input split
for(int i=0; i < numMapTasks; ++i) {
inputLength += splits[i].getInputDataLength();
maps[i] = new TaskInProgress(jobId, jobFile, //類型是map task
splits[i],
jobtracker, conf, this, i, numSlotsPerMap);
}
LOG.info("Input size for job " + jobId + " = " + inputLength
+ ". Number of splits = " + splits.length);
// Set localityWaitFactor before creating cache
localityWaitFactor =
conf.getFloat(LOCALITY_WAIT_FACTOR, DEFAULT_LOCALITY_WAIT_FACTOR);
/* 對於map task,將其放入nonRunningMapCache,是一個Map<Node,List<TaskInProgress>>,也即對於map task來講,其將會被分配到其input
split所在的Node上。在此,Node代表一個datanode或者機架或者數據中 心。nonRunningMapCache將在JobTracker向TaskTracker分配map task的 時候使用。
*/
if (numMapTasks > 0) {
//通過createCache()方法為這些TaskInProgress對象產生一個未執行任務的Map緩存nonRunningMapCache。
//slave端的TaskTracker向master發送心跳時,就可以直接從這個cache中取任務去執行。
nonRunningMapCache = createCache(splits, maxLevel);
}
// set the launch time
this.launchTime = jobtracker.getClock().getTime();
//
// Create reduce tasks
//
//其次JobInProgress會創建Reduce的監控對象,這個比較簡單,根據JobConf裡指定的Reduce數目創建,
//缺省只創建1個Reduce任務。監控和調度Reduce任務的是TaskInProgress類,不過構造方法有所不同,
//TaskInProgress會根據不同參數分別創建具體的MapTask或者ReduceTask。同樣地,
//initTasks()也會通過createCache()方法產生nonRunningReduceCache成員。
this.reduces = new TaskInProgress[numReduceTasks];
for (int i = 0; i < numReduceTasks; i++) {
reduces[i] = new TaskInProgress(jobId, jobFile, //這是reduce task
numMapTasks, i,
jobtracker, conf, this, numSlotsPerReduce);
/*reducetask放入nonRunningReduces,其將在JobTracker向TaskTracker分配reduce task的時候使用。*/
nonRunningReduces.add(reduces[i]);
}
// Calculate the minimum number of maps to be complete before
// we should start scheduling reduces
completedMapsForReduceSlowstart =
(int)Math.ceil(
(conf.getFloat("mapred.reduce.slowstart.completed.maps",
DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART) *
numMapTasks));
// ... use the same for estimating the total output of all maps
resourceEstimator.setThreshhold(completedMapsForReduceSlowstart);
// create cleanup two cleanup tips, one map and one reduce.
//創建兩個cleanup task,一個用來清理map,一個用來清理reduce.
cleanup = new TaskInProgress[2];
// cleanup map tip. This map doesn't use any splits. Just assign an empty
// split.
TaskSplitMetaInfo emptySplit = JobSplit.EMPTY_TASK_SPLIT;
cleanup[0] = new TaskInProgress(jobId, jobFile, emptySplit,
jobtracker, conf, this, numMapTasks, 1);
cleanup[0].setJobCleanupTask();
// cleanup reduce tip.
cleanup[1] = new TaskInProgress(jobId, jobFile, numMapTasks,
numReduceTasks, jobtracker, conf, this, 1);
cleanup[1].setJobCleanupTask();
// create two setup tips, one map and one reduce.
//創建兩個初始化 task,一個初始化map,一個初始化reduce.
setup = new TaskInProgress[2];
// setup map tip. This map doesn't use any split. Just assign an empty
// split.
setup[0] = new TaskInProgress(jobId, jobFile, emptySplit,
jobtracker, conf, this, numMapTasks + 1, 1);
setup[0].setJobSetupTask();
// setup reduce tip.
setup[1] = new TaskInProgress(jobId, jobFile, numMapTasks,
numReduceTasks + 1, jobtracker, conf, this, 1);
setup[1].setJobSetupTask();
synchronized(jobInitKillStatus){
jobInitKillStatus.initDone = true;
if(jobInitKillStatus.killed) {
throw new KillInterruptedException("Job " + jobId + " killed in init");
}
}
//JobInProgress創建完TaskInProgress後,最後構造JobStatus並記錄job正在執行中,
//然後再調用JobHistory.JobInfo.logInited()記錄job的執行日志。
tasksInited = true;
JobHistory.JobInfo.logInited(profile.getJobID(), this.launchTime,
numMapTasks, numReduceTasks);
// Log the number of map and reduce tasks
LOG.info("Job " + jobId + " initialized successfully with " + numMapTasks
+ " map tasks and " + numReduceTasks + " reduce tasks.");
}
initTasks方法的主要工作是讀取上傳的分片信息,檢查分片的有效性及要和配置文件中的numMapTasks相等,然後創建 numMapTasks個TaskInProgress作為Map Task。通過createCache方法,將沒有找到對應分片的map放入nonLocalMaps中,獲取分片所在節點,然後將節點與其上分片對應的 map對應起來,放入Map<Node, List<TaskInProgress>> cache之中,需要注意的是還會根據設定的網絡深度存儲父節點(可能存在多個子節點)下所有子節點包含的map,從這可以看出這裡實現了本地化,將這個 cache賦值給nonRunningMapCache表示還未運行的map。然後是創建reduce task,創建numReduceTasks個TaskInProgress,放入nonRunningReduces。這裡需要注意:map和 reduce都是TaskInProgress那以後咋區分呢?其實這兩種的構造函數是不同的,判斷兩種類型的task的根據就是splitInfo有無設置,map task對splitInfo進行了設置,而reduce task則設splitInfo=null。然後是獲取map task完成的最小數量才可以調度reduce task。創建兩個清理task:cleanup = new TaskInProgress[2],一個用來清理map task(這個也是一個map task),一個用來清理reduce task(這個也是一個reduce task),TaskInProgress構造函數的task個數參數都為1,map的splitInfo是 JobSplit.EMPTY_TASK_SPLIT;創建兩個初始化task:setup = new TaskInProgress[2],一個用來初始化map task(這個也是一個map task),一個用來初始化reduce task(這個也是一個reduce task),這4個TaskInProgress都會設置對應的標記為來表示類型。最後是設置一個標記位來表示完成初始化工作。
這樣EagerTaskInitializationListener在JobTracker端就完成了對Job的初始化工作,所有task等待taskTracker的心跳被調度。
來看TaskTracker通過心跳提交狀態的方法JobTracker.heartbeat,該方法代碼:
/**
* The periodic heartbeat mechanism between the {@link TaskTracker} and
* the {@link JobTracker}.
*
* The {@link JobTracker} processes the status information sent by the
* {@link TaskTracker} and responds with instructions to start/stop
* tasks or jobs, and also 'reset' instructions during contingencies.
*/
public synchronized HeartbeatResponse heartbeat(TaskTrackerStatus status,
boolean restarted,
boolean initialContact,
boolean acceptNewTasks,
short responseId)
throws IOException {
if (LOG.isDebugEnabled()) {
LOG.debug("Got heartbeat from: " + status.getTrackerName() +
" (restarted: " + restarted +
" initialContact: " + initialContact +
" acceptNewTasks: " + acceptNewTasks + ")" +
" with responseId: " + responseId);
}
// Make sure heartbeat is from a tasktracker allowed by the jobtracker.
if (!acceptTaskTracker(status)) {
throw new DisallowedTaskTrackerException(status);
}
// First check if the last heartbeat response got through
String trackerName = status.getTrackerName();
long now = clock.getTime();
if (restarted) {
faultyTrackers.markTrackerHealthy(status.getHost());
} else {
faultyTrackers.checkTrackerFaultTimeout(status.getHost(), now);
}
HeartbeatResponse prevHeartbeatResponse =
trackerToHeartbeatResponseMap.get(trackerName);
boolean addRestartInfo = false;
if (initialContact != true) {
// If this isn't the 'initial contact' from the tasktracker,
// there is something seriously wrong if the JobTracker has
// no record of the 'previous heartbeat'; if so, ask the
// tasktracker to re-initialize itself.
if (prevHeartbeatResponse == null) {
// This is the first heartbeat from the old tracker to the newly
// started JobTracker
if (hasRestarted()) {
addRestartInfo = true;
// inform the recovery manager about this tracker joining back
recoveryManager.unMarkTracker(trackerName);
} else {
// Jobtracker might have restarted but no recovery is needed
// otherwise this code should not be reached
LOG.warn("Serious problem, cannot find record of 'previous' " +
"heartbeat for '" + trackerName +
"'; reinitializing the tasktracker");
return new HeartbeatResponse(responseId,
new TaskTrackerAction[] {new ReinitTrackerAction()});
}
} else {
// It is completely safe to not process a 'duplicate' heartbeat from a
// {@link TaskTracker} since it resends the heartbeat when rpcs are
// lost see {@link TaskTracker.transmitHeartbeat()};
// acknowledge it by re-sending the previous response to let the
// {@link TaskTracker} go forward.
if (prevHeartbeatResponse.getResponseId() != responseId) {
LOG.info("Ignoring 'duplicate' heartbeat from '" +
trackerName + "'; resending the previous 'lost' response");
return prevHeartbeatResponse;
}
}
}
// Process this heartbeat
short newResponseId = (short)(responseId + 1); //響應編號+1
status.setLastSeen(now);
if (!processHeartbeat(status, initialContact, now)) {
if (prevHeartbeatResponse != null) {
trackerToHeartbeatResponseMap.remove(trackerName);
}
return new HeartbeatResponse(newResponseId,
new TaskTrackerAction[] {new ReinitTrackerAction()});
}
// Initialize the response to be sent for the heartbeat
HeartbeatResponse response = new HeartbeatResponse(newResponseId, null);
List<TaskTrackerAction> actions = new ArrayList<TaskTrackerAction>();
boolean isBlacklisted = faultyTrackers.isBlacklisted(status.getHost());
// Check for new tasks to be executed on the tasktracker
if (recoveryManager.shouldSchedule() && acceptNewTasks && !isBlacklisted) {
TaskTrackerStatus taskTrackerStatus = getTaskTrackerStatus(trackerName);
if (taskTrackerStatus == null) {
LOG.warn("Unknown task tracker polling; ignoring: " + trackerName);
} else {
//setup和cleanup的task優先級最高
List<Task> tasks = getSetupAndCleanupTasks(taskTrackerStatus);
if (tasks == null ) {
//任務調度器分配任務
tasks = taskScheduler.assignTasks(taskTrackers.get(trackerName)); //分配任務Map OR Reduce Task
}
if (tasks != null) {
for (Task task : tasks) {
//將任務放入actions列表,返回給TaskTracker
expireLaunchingTasks.addNewTask(task.getTaskID());
if(LOG.isDebugEnabled()) {
LOG.debug(trackerName + " -> LaunchTask: " + task.getTaskID());
}
actions.add(new LaunchTaskAction(task));
}
}
}
}
// Check for tasks to be killed
List<TaskTrackerAction> killTasksList = getTasksToKill(trackerName);
if (killTasksList != null) {
actions.addAll(killTasksList);
}
// Check for jobs to be killed/cleanedup
List<TaskTrackerAction> killJobsList = getJobsForCleanup(trackerName);
if (killJobsList != null) {
actions.addAll(killJobsList);
}
// Check for tasks whose outputs can be saved
List<TaskTrackerAction> commitTasksList = getTasksToSave(status);
if (commitTasksList != null) {
actions.addAll(commitTasksList);
}
// calculate next heartbeat interval and put in heartbeat response
int nextInterval = getNextHeartbeatInterval();
response.setHeartbeatInterval(nextInterval);
response.setActions(
actions.toArray(new TaskTrackerAction[actions.size()]));
// check if the restart info is req
if (addRestartInfo) {
response.setRecoveredJobs(recoveryManager.getJobsToRecover());
}
// Update the trackerToHeartbeatResponseMap
trackerToHeartbeatResponseMap.put(trackerName, response);
// Done processing the hearbeat, now remove 'marked' tasks
removeMarkedTasks(trackerName);
return response;
}
一、該方法包括5個參數:A、status封裝了TaskTracker上的各種狀態信息,包括: TaskTracker名稱;TaskTracker主機名;TaskTracker對外的HTTp端口號;該TaskTracker上已經失敗的任務總數;正在運行的各個任務的運行狀態;上次匯報心跳的時間;Map slot總數,即同時運行的Map Task總數;Reduce slot總數;TaskTracker健康狀態;TaskTracker資源(內存、CPU)信息。B、restarted表示TaskTracker是否剛剛重啟。C、initialContact表示TaskTracker是否初次鏈接JobTracker。D、acceptNewTasks表示 TaskTracker是否可以接受新的任務,這通常取決於solt是否有剩余和節點的健康狀況等。E、responseID表示心跳相應編號,用於防止重復發送心跳,沒接收一次心跳後該值加1。
二、acceptTaskTracker(status)檢查心跳是否來自於JobTracker所允許的TaskTracker,當一個 TaskTracker在mapred.hosts(include list是合法的節點列表,只有位於該列表中的節點才可以允許想obTracker發起鏈接請求)指定的主機列表中,不在 mapred.exclude(exclude list是一個非法節點列表,所有位於這個列表中的節點將無法與JobTracker鏈接)指定的主機列表中時,可以接入JobTracker。默認情況下這兩個列表都為空,可在配置文件mapred-site.xml中配置,可動態加載。
三、如果TaskTracker重啟了,則將它標注為健康的TaskTracker,並從黑名單(Hadoop允許用戶編寫一個腳本監控 TaskTracker是否健康,並通過心跳將檢測結果發送給JobTracker,一旦發現不健康,JobTracker會將該T阿克蘇Taskker 加入黑名單,不再分配任務,直到檢測結果為健康)或灰名單(JobTracker會記錄每個TaskTracker被作業加入黑名單的次數#backlist,滿足一定的要求就加入JobTracker的灰名單)中清除,否則,啟動TaskTracker容錯機制以檢查它是否處於健康狀態。
四、獲取該TaskTracker對應的HeartbeatResponse,並檢查。如果不是第一次連接JobTracker,且對應的 HeartbeatResponse等於null(表明JobTracker沒有對應的記錄,可能TaskTracker出錯也可能JobTracker 重啟了),如果JobTracker重啟了,則從recoveryManager中刪除這個trackerName,否則向TaskTracker發送初始化命令ReinitTrackerAction;HeartbeatResponse不等於null,有可能是TaskTracker重復發送心跳,如果是重復發送心跳則返回當前的HeartbeatResponse。
五、更新響應編號(+1);記錄心跳發送時間status.setLastSeen(now);然後調用 processHeartbeat(status, initialContact, now)方法來處理TaskTracker發送過來的心跳,先通過updateTaskTrackerStatus方法更新一些資源統計情況,並替換掉舊的taskTracker的狀態,如果是初次鏈接JobTracker且JobTracker中有此taskTracker的記錄(TT重啟),則需要清空和這個TaskTracker相關的信息,如果不是初次鏈接JobTracker且JobTracker並沒有發現此TaskTracker以前的記錄,則直接返回false;如果初次鏈接JobTracker且包含在黑名單中,則increment the count of blacklisted trackers,然後加入trackerExpiryQueue和 hostnameToTaskTracker;updateTaskStatuses(trackerStatus)更新task的狀態,這個好復雜留待以後分析;updateNodeHealthStatus(trackerStatus, timeStamp)更新節點健康狀態;返回true。若返回false,需要從trackerToHeartbeatResponseMap中刪除對應的trackerName信息並返回給TaskTracker初始化命令ReinitTrackerAction。
六、構造TaskTracker的心跳應答。首先獲取setup和cleanup的tasks,如果tasks==null則用調度器(默認是 JobQueueTaskScheduler)去分配task,tasks = taskScheduler.assignTasks(taskTrackers.get(trackerName)),會獲得Map Task或者Reduce Task,對應assignTasks方法的代碼如下:
//JobQueueTaskScheduler最重要的方法是assignTasks,他實現了工作調度。
@Override
public synchronized List<Task> assignTasks(TaskTracker taskTracker)
throws IOException {
TaskTrackerStatus taskTrackerStatus = taskTracker.getStatus();
ClusterStatus clusterStatus = taskTrackerManager.getClusterStatus();
final int numTaskTrackers = clusterStatus.getTaskTrackers();
final int clusterMapCapacity = clusterStatus.getMaxMapTasks();
final int clusterReduceCapacity = clusterStatus.getMaxReduceTasks();
Collection<JobInProgress> jobQueue =
jobQueueJobInProgressListener.getJobQueue();
//首先它會檢查 TaskTracker 端還可以做多少個 map 和 reduce 任務,將要派發的任務數是否超出這個數,
//是否超出集群的任務平均剩余可負載數。如果都沒超出,則為此TaskTracker 分配一個 MapTask 或 ReduceTask 。
//
// Get map + reduce counts for the current tracker.
//
final int trackerMapCapacity = taskTrackerStatus.getMaxMapSlots();
final int trackerReduceCapacity = taskTrackerStatus.getMaxReduceSlots();
final int trackerRunningMaps = taskTrackerStatus.countMapTasks();
final int trackerRunningReduces = taskTrackerStatus.countReduceTasks();
// Assigned tasks
List<Task> assignedTasks = new ArrayList<Task>();
//
// Compute (running + pending) map and reduce task numbers across pool
//
//計算剩余的map和reduce的工作量:remaining
int remainingReduceLoad = 0;
int remainingMapLoad = 0;
synchronized (jobQueue) {
for (JobInProgress job : jobQueue) {
if (job.getStatus().getRunState() == JobStatus.RUNNING) {
remainingMapLoad += (job.desiredMaps() - job.finishedMaps());
if (job.scheduleReduces()) {
remainingReduceLoad +=
(job.desiredReduces() - job.finishedReduces());
}
}
}
}
// Compute the 'load factor' for maps and reduces
double mapLoadFactor = 0.0;
if (clusterMapCapacity > 0) {
mapLoadFactor = (double)remainingMapLoad / clusterMapCapacity;
}
double reduceLoadFactor = 0.0;
if (clusterReduceCapacity > 0) {
reduceLoadFactor = (double)remainingReduceLoad / clusterReduceCapacity;
}
//
// In the below steps, we allocate first map tasks (if appropriate),
// and then reduce tasks if appropriate. We go through all jobs
// in order of job arrival; jobs only get serviced if their
// predecessors are serviced, too.
//
//
該方法會先獲取集群的基本信息,容量,然後獲取此tasktracker的基本信息(slots及正在運行的task數);然後計算所有運行中的 job的剩余量的總和(remainingReduceLoad和remainingMapLoad);分別計算map和reduce的負載因子(都是兩種類型的剩余占對應的最大容量比)mapLoadFactor、reduceLoadFactor;然後計算 trackerCurrentMapCapacity當前容量這裡會使得集群中的所有tasktracker的負載盡量平均,因為 Math.min((int)Math.ceil(mapLoadFactor * trackerMapCapacity), trackerMapCapacity),mapLoadFactor * trackerMapCapacity會使得該節點當前map的容量和集群整體的負載相近;然後獲取當前tasktracker可用的mapslot,該 tasktracker超過集群目前的負載水平後就不分配task,否則會有空閒的slot等待分配task;然後為每個mapslot選擇一個map task,選擇的過程十分復雜,首先會遍歷jobQueue中的每個處於非運行狀態的JobInProgress,調 JobInProgress.obtainNewNodeOrRackLocalMapTask方法獲取基於節點本地或者機架本地的map task,obtainNewNodeOrRackLocalMapTask會通過調用findNewMapTask獲取map數組中的索引值。
(1)首先從失敗task選取合適的task直接返回。findNewMapTask方法會先通過findTaskFromList方法從 failedMaps獲取合適的失敗map並返回(返回條件是A、該tasktracker沒運行過TaskInProgress;B、該 TaskInProgress失敗過的節點數不低於運行taskTracker的主機數,這兩個滿足一個即可),如果有合適的失敗map task,則通過scheduleMap(tip)方法將其加入nonLocalRunningMaps(該task沒有對應的分片信息)或者 runningMapCache(每個分片的存儲Node及其對應的maptask列表,還有Node的父節點Node及對應的maptask列表也要加入),然後返回給obtainNewNodeOrRackLocalMapTask這個maptask在map數組中的索引值,此時從失敗的task中尋找合適的task並不考慮數據的本地性。
final SortedSet<TaskInProgress> failedMaps是按照task attempt失敗次數排序的TaskInProgress集合。
Set<TaskInProgress> nonLocalRunningMaps是no-local且正在運行的TaskInProgress結合。
Map<Node, Set<TaskInProgress>> runningMapCache是Node與運行的TaskInProgress集合映射關系,一個任務獲得調度機會,其TaskInProgress便會添加進來。
(2)如果沒有合適的失敗task,則獲取當前tasktracker對應的Node,然後“從近到遠一層一層地尋找,直到找到合適的 TaskInProgress”(通過不斷獲取父Node)從nonRunningMapCache中獲取此Node的所有map task列表,如果列表不為空則調用findTaskFromList方法從這個列表中獲取合適的TaskInProgress,如果tip!=null 則調用scheduleMap(tip)(上面已經介紹),然後檢查列表是否為空,為空則從nonRunningMapCache清除這個Node的所有信息,再返回給obtainNewNodeOrRackLocalMapTask這個maptask在map數組中的索引值,如果遍歷拓撲最大層數還是沒有合適的task,則返回給obtainNewNodeOrRackLocalMapTask一個值-1,這裡說明如果方法findNewMapTask 的參數maxCacheLevel大於0則是獲取(node-local或者rack-local,後面的其他情況不予考慮),其實就是優先考慮 tasktracker對應Node有分片信息的本地的map(是node-local),然後再考慮父Node(同一個機架rack-local)的,再其他的(跨機架off-switch,這點得看設置的網絡深度,大於2才會考慮),這樣由近及遠的做法會使得減少數據的拷貝距離,降低網絡開銷。
Map<Node, List<TaskInProgress>> nonRunningMapCache是Node與未運行的TaskInProgress的集合映射關系,通過作業的InputFormat可直接獲取。
(3)然後獲取cache大網絡深度的Node;獲取該tasktracker對應Node的最深父Node;剩下的和上面(2)中的類似,只不過這次找的跨機架(或者更高一級,主要看設置的網絡深度)。選擇跨機架的task,scheduleMap(tip);返回給 obtainNewNodeOrRackLocalMapTask這個maptask在map數組中的索引值。
(4)然後是查找nonLocalMaps中有無合適的task,這種任務沒有輸入數據,不需考慮本地性。scheduleMap(tip);返回給obtainNewNodeOrRackLocalMapTask這個maptask在map數組中的索引值。
final List<TaskInProgress> nonLocalMaps是一些計算密集型任務,比如hadoop example中的PI作業。
(5)如果有“拖後腿”的task(hasSpeculativeMaps==true),遍歷runningMapCache,異常從 node-local、rack-local、off-switch選擇合適的“拖後腿”task,返回給 obtainNewNodeOrRackLocalMapTask這個maptask在map數組中的索引值,這不需要 scheduleMap(tip),很明顯已經在runningMapCache中了。
(6)從nonLocalRunningMaps中查找“拖後腿”的task,這是計算密集型任務在拖後腿,返回給obtainNewNodeOrRackLocalMapTask這個maptask在map數組中的索引值。
(7)再找不到返回-1.
obtainNewNodeOrRackLocalMapTask方法只執行到(2),要麼返回一個MapTask要麼返回null(findNewMapTask返回的是-1)這個maptask在map數組中的索引值,不再進行後續步驟。
返回到obtainNewMapTask方法,獲得map數組索引值後,還要獲取該TaskInProgress的task(可能是 MapTask或者ReduceTask,這裡是MapTask),把這個task返回給assignTasks方法,加入分配task列表 assignedTasks,跳出內層for循環,准備為下一個mapslot找合適的MapTask,如果沒有合適的MapTask(node- local或者rack-local),則調用obtainNewNonLocalMapTask獲取(除了上面的(2)不執行,其他都執行)MapTask,加入分配task列表assignedTasks,跳出內層for循環。
然後分配ReduceTask,每次心跳分配不超過1個ReduceTask。和分配mapslot類似,這裡至多分配一個 reduceslot,遍歷jobQueue通過obtainNewReduceTask方法獲取合適的ReduceTask。 obtainNewReduceTask方法會先做一個檢查,和Map Task一樣,會對節點的可靠性和磁盤空間進行檢查;然後判斷Job的map是否運行到該調用reduce的比例,若不到就返回null;然後調用 findNewReduceTask方法獲取reduce的索引值。findNewReduceTask方法會先檢查該Job是否有reduce,沒有就返回-1,檢查此taskTracker是否可以運行reduce任務,然後調用方法findTaskFromList從 nonRunningReduces中選擇合適的TaskInProgress,放入runningReduces中,直接返回給 obtainNewReduceTask對應的索引;如果沒有合適的就從“拖後腿”的runningReduces中通過 findSpeculativeTask方法找出退後退的reduce,放入runningReduces中,直接返回給 obtainNewReduceTask對應的索引;再找不到就直接返回給obtainNewReduceTask方法-1。然後返回到 obtainNewReduceTask方法,獲取相應的ReduceTask,返回給assignTasks方法,加入分配任務列表 assignedTasks中。
在分配mapslot和reduceslot時循環中都有判斷exceededReducePadding真假值的代碼,exceededReducePadding是通過exceededPadding方法來獲取的。在任務調度器 JobQueueTaskScheduler的實現中,如果在集群中的TaskTracker節點比較多的情況下,它總是會想辦法讓若干個 TaskTracker節點預留一些空閒的slots(計算能力),以便能夠快速的處理優先級比較高的Job的Task或者發生錯誤的Task,以保證已經被調度的作業的完成。exceededPadding方法判斷當前集群是否需要預留一部分map/reduce計算能力來執行那些失敗的、緊急的或特殊的任務。
還有一點需要注意的是對於每個slot總是會優先考慮jobQueue中的第一個job的任務(map、reduce),如果分配不成功才會考慮其他Job的,這樣盡量保證優先處理第一個Job。
assignTasks方法最後返回分配任務列表assignedTasks。調度器只分配MapTask和ReduceTask。而作業的其它輔助任務都是交由JobTracker來調度的,如JobSetup、JobCleanup、TaskCleanup任務等。
對於JobQueueTaskScheduler的任務調度實現原則可總結如下:
1.先調度優先級高的作業,統一優先級的作業則先進先出;
2.盡量使集群每一個TaskTracker達到負載均衡(這個均衡是task數量上的而不是實際的工作強度);
3.盡量分配作業的本地任務給TaskTracker,但不是盡快分配作業的本地任務給TaskTracker,最多分配一個非本地任務給 TaskTracker(一是保證任務的並發性,二是避免有些TaskTracker的本地任務被偷走),最多分配一個reduce任務;
4.為優先級或者緊急的Task預留一定的slot;
七、遍歷任務列表tasks,將所有task放入expireLaunchingTasks中監控是否過期 expireLaunchingTasks.addNewTask(task.getTaskID()),然後放入actions.add(new LaunchTaskAction(task))。
八、遍歷taskTracker對應的所有task是否有需要kill的,以及trackerToTasksToCleanup中對應此tasktracker的task需要清理,封裝成KillTaskAction,加入actions中。
九、獲取trackerToJobsToCleanup中對應此tasktracker的所有jobs,封裝成KillJobAction,加入actions中。
十、檢查tasktracker的所有的task中狀態等於TaskStatus.State.COMMIT_PENDING的,封裝成CommitTaskAction,加入actions中。表示這個task的輸出可以保存。
十一、計算下一次心跳間隔與actions一同加入響應信息response。
十二、如果JobTracker重啟了,則將需要將需要恢復的Job列表加入response。response.setRecoveredJobs(recoveryManager.getJobsToRecover())
十三、將trackerName及其響應信息response,加入trackerToHeartbeatResponseMap
十四、因為已經將任務分配出去了,所以需要更新JobTracker的一些數據結構。 removeMarkedTasks(trackerName)從一些相關的數據結構中清除trackerName對應的數據,比如 trackerToMarkedTasksMap、taskidToTrackerMap、trackerToTaskMap、 taskidToTIPMap等。
十五、最後返回響應信息response。