上一篇文章介紹了Kinect中語音識別的基本概念,以及一些語音處理方面的術語。在此基礎上使用Kinect麥克風陣列來進行音頻錄制的例子說明了Kinect中音頻處理的核心對象及其配置。本文將繼續介紹Kinect中的語音識別,並以兩個小例子來展示語音識別中的方向識別和語音命令識別。
1. 使用定向麥克風進行波速追蹤(Beam Tracking for a Directional Microphone)
可以使用這4個麥克風來模擬定向麥克風產生的效果,這個過程稱之為波束追蹤(beam tracking),為此我們新建一個WPF項目,過程如下:
1. 創建一個名為KinectFindAudioDirection的WPF項目。
2. 添加對Microsoft.Kinect.dll和Microsoft.Speech.dll的引用。
3. 將主窗體的名稱改為“Find Audio Direction”
4. 在主窗體中繪制一個垂直的細長矩形。
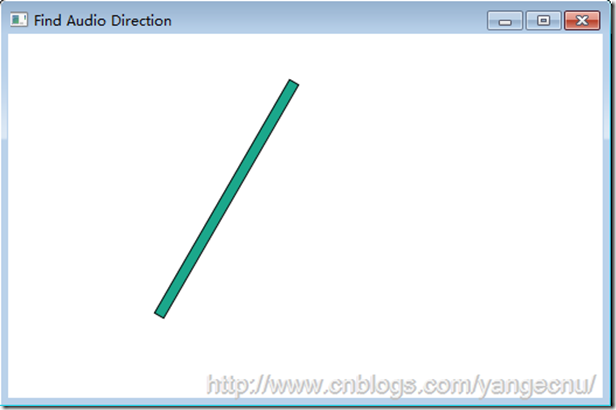
界面上的細長矩形用來指示某一時刻探測到的說話者的語音方向。矩形有一個旋轉變換,在垂直軸上左右擺動,以表示聲音的不同來源方向。前端頁面代碼:
<Rectangle Fill="#1BA78B" HorizontalAlignment="Left" Margin="240,41,0,39" Stroke="Black" Width="10" RenderTransformOrigin="0.5,0">
<Rectangle.RenderTransform>
<TransformGroup>
<ScaleTransform/>
<SkewTransform/>
<RotateTransform Angle="{Binding BeamAngle}"/>
<TranslateTransform/>
</TransformGroup>
</Rectangle.RenderTransform>
</Rectangle>
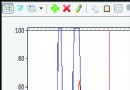
上圖是程序的UI界面。後台邏輯代碼和之前的例子大部分都是相同的。首先實例化一個KinectAudioSource對象,然後將主窗體的DataContext賦值給本身。將BeamAngleMode設置為Adaptive,使得能夠自動追蹤說話者的聲音。我們需要編寫KinectAudioSource對象的BeamChanged事件對應的處理方法。當用戶的說話時,位置發生變化時就會觸發該事件。我們需要創建一個名為BeamAngle的屬性,使得矩形的RotateTransform可以綁定這個屬性。
public partial class MainWindow : Window, INotifyPropertyChanged
{
public MainWindow()
{
InitializeComponent();
this.DataContext = this;
this.Loaded += delegate { ListenForBeamChanges(); };
}
private KinectAudioSource CreateAudioSource()
{
var source = KinectSensor.KinectSensors[0].AudioSource;
source.NoiseSuppression = true;
source.AutomaticGainControlEnabled = true;
source.BeamAngleMode = BeamAngleMode.Adaptive;
return source;
}
private void ListenForBeamChanges()
{
KinectSensor.KinectSensors[0].Start();
var audioSource = CreateAudioSource();
audioSource.BeamAngleChanged += audioSource_BeamAngleChanged;
audioSource.Start();
}
public event PropertyChangedEventHandler PropertyChanged;
private void OnPropertyChanged(string propName)
{
if (PropertyChanged != null)
PropertyChanged(this, new PropertyChangedEventArgs(propName));
}
private double _beamAngle;
public double BeamAngle
{
get { return _beamAngle; }
set
{
_beamAngle = value;
OnPropertyChanged("BeamAngle");
}
}
}
以上代碼中,還需要對BeamChanged事件編寫對應的處理方法。每次當波束的方向發生改變時,就更改BeamAngle的屬性。SDK中使用弧度表示角度。所以在事件處理方法中我們需要將弧度換成度。為了能達到說話者移到左邊,矩形條也能夠向左邊移動的效果,我們需要將角度乘以一個-1。代碼如下:
void audioSource_BeamAngleChanged(object sender, BeamAngleChangedEventArgs e)
{
BeamAngle = -1 * e.Angle;
}
運行程序,然後在房間裡不同地方走動,可以看到矩形條會根據你的位置左右擺動。
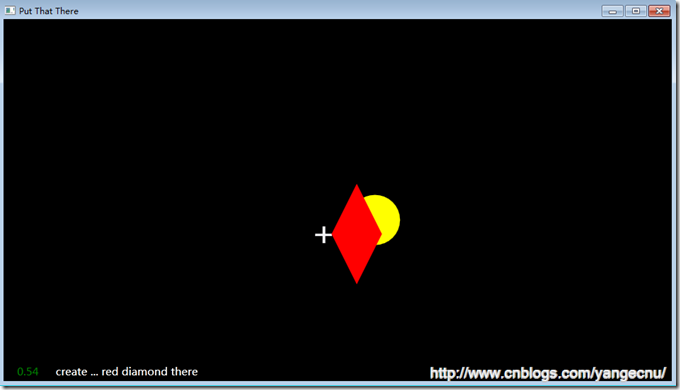
2. 語音命令識別
在這一部分,我們將會結合KinectAudioSource和SpeechRecognitionEngine來演示語音命令識別的強大功能。為了展示語音命令能夠和骨骼追蹤高效結合,我們會使用語音命令向窗體上繪制圖形,並使用命令移動這些圖形到光標的位置。命令類似如下:
Create a yellow circle, there.
Create a cyan triangle, there.
Put a magenta square, there.
Create a blue diamond, there.
Move that ... there.
Put that ... there.
Move that ... below that.
Move that ... west of the diamond.
Put a large green circle ... there.
程序界面大致如下:
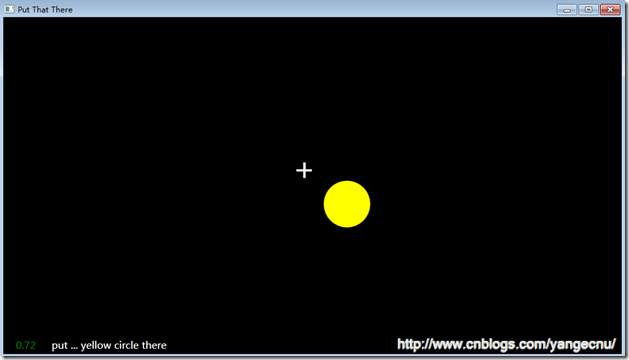
和之前的應用程序一樣,首先創建一下項目的基本結構:
1. 創建一個名為KinectPutThatThere的WPF項目。
2. 添加對Microsoft.Kinect.dll和Microsoft.Speech.dll的引用。
3. 將主窗體的名稱改為“Put That There”
4. 添加一個名為CrossHairs.xaml的用戶自定義控件。
CrossHair用戶控件簡單的以十字光標形式顯示當前用戶右手的位置。下面的代碼顯示了這個自定義控件的XAML文件。注意到對象於容器有一定的偏移使得十字光標的中心能夠處於Grid的零點。
<Grid Height="50" Width="50" RenderTransformOrigin="0.5,0.5">
<Grid.RenderTransform>
<TransformGroup>
<ScaleTransform/>
<SkewTransform/>
<RotateTransform/>
<TranslateTransform X="-25" Y="-25"/>
</TransformGroup>
</Grid.RenderTransform>
<Rectangle Fill="#FFF4F4F5" Margin="22,0,20,0" Stroke="#FFF4F4F5"/>
<Rectangle Fill="#FFF4F4F5" Margin="0,22,0,21" Stroke="#FFF4F4F5"/>
</Grid>
在應用程序的主窗體中,將根節點從grid對象改為canvas對象。Canvas對象使得將十字光標使用動畫滑動到手的位置比較容易。在主窗體上添加一個CrossHairs自定義控件。在下面的代碼中,我們可以看到將Canvas對象嵌套在了一個Viewbox控件中。這是一個比較老的處理不同屏幕分辨率的技巧。ViewBox控件會自動的將內容進行縮放以適應實際屏幕的大小。設置MainWindows的背景色,並將Canvas的顏色設置為黑色。然後在Canvas的底部添加兩個標簽。一個標簽用來顯示SpeechRecognitionEngine將要處理的語音指令,另一個標簽顯示匹配正確的置信度。CrossHair自定義控件綁定了HandTop和HandLeft屬性。兩個標簽分別綁定了HypothesizedText和Confidence屬性。代碼如下:
<Window x:Class="KinectPutThatThere.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:local="clr-namespace:KinectPutThatThere"
Title="Put That There" Background="Black">
<Viewbox>
<Canvas x:Name="MainStage" Height="1080" Width="1920" Background="Black" VerticalAlignment="Bottom">
<local:CrossHairs Canvas.Top="{Binding HandTop}" Canvas.Left="{Binding HandLeft}" />
<Label Foreground="White" Content="{Binding HypothesizedText}" Height="55" FontSize="32" Width="965" Canvas.Left="115" Canvas.Top="1025" />
<Label Foreground="Green" Content="{Binding Confidence}" Height="55" Width="114" FontSize="32" Canvas.Left="0" Canvas.Top="1025" />
</Canvas>
</Viewbox>
</Window>
在後台邏輯代碼中,讓MainWindows對象實現INofityPropertyChanged事件並添加OnPropertyChanged幫助方法。我們將創建4個屬性用來為前台UI界面進行綁定。
public partial class MainWindow : Window, INotifyPropertyChanged
{
private double _handLeft;
public double HandLeft
{
get { return _handLeft; }
set
{
_handLeft = value;
OnPropertyChanged("HandLeft");
}
}
private double _handTop;
public double HandTop
{
get { return _handTop; }
set
{
_handTop = value;
OnPropertyChanged("HandTop");
}
}
private string _hypothesizedText;
public string HypothesizedText
{
get { return _hypothesizedText; }
set
{
_hypothesizedText = value;
OnPropertyChanged("HypothesizedText");
}
}
private string _confidence;
public string Confidence
{
get { return _confidence; }
set
{
_confidence = value;
OnPropertyChanged("Confidence");
}
}
public event PropertyChangedEventHandler PropertyChanged;
private void OnPropertyChanged(string propertyName)
{
if (PropertyChanged != null)
{
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
}
}
}
添加CreateAudioSource方法,在該方法中,將KinectAudioSource對象的AutoGainControlEnabled的屬性設置為false。
private KinectAudioSource CreateAudioSource()
{
var source = KinectSensor.KinectSensors[0].AudioSource;
source.AutomaticGainControlEnabled = false;
source.EchoCancellationMode = EchoCancellationMode.None;
return source;
}
接下來實現骨骼追蹤部分邏輯來獲取右手的坐標,相信看完骨骼追蹤那兩篇文章後這部分的代碼應該會比較熟悉。首先創建一個私有字段_kinectSensor來保存當前的KienctSensor對象,同時創建SpeechRecognitionEngine對象。在窗體的構造函數中,對這幾個變量進行初始化。例外注冊骨骼追蹤系統的Skeleton事件並將主窗體的DataContext對象賦給自己。
KinectSensor _kinectSensor;
SpeechRecognitionEngine _sre;
KinectAudioSource _source;
public MainWindow()
{
InitializeComponent();
this.DataContext = this;
this.Unloaded += delegate
{
_kinectSensor.SkeletonStream.Disable();
_sre.RecognizeAsyncCancel();
_sre.RecognizeAsyncStop();
_sre.Dispose();
};
this.Loaded += delegate
{
_kinectSensor = KinectSensor.KinectSensors[0];
_kinectSensor.SkeletonStream.Enable(new TransformSmoothParameters()
{
Correction = 0.5f,
JitterRadius = 0.05f,
MaxDeviationRadius = 0.04f,
Smoothing = 0.5f
});
_kinectSensor.SkeletonFrameReady += nui_SkeletonFrameReady;
_kinectSensor.Start();
StartSpeechRecognition();
};
}
在上面的代碼中,我們添加了一些TransformSmoothParameters參數來使得骨骼追蹤更加平滑。nui_SkeletonFrameReady方法如下。方式使用骨骼追蹤數據來獲取我們感興趣的右手的關節點位置。這部分代碼和之前文章中的類似。大致流程是:遍歷當前處在追蹤狀態下的骨骼信息。然後找到右手關節點的矢量信息,然後使用SkeletonToDepthImage來獲取相對於屏幕尺寸的X,Y坐標信息。
void nui_SkeletonFrameReady(object sender, SkeletonFrameReadyEventArgs e)
{
using (SkeletonFrame skeletonFrame = e.OpenSkeletonFrame())
{
if (skeletonFrame == null)
return;
var skeletons = new Skeleton[skeletonFrame.SkeletonArrayLength];
skeletonFrame.CopySkeletonDataTo(skeletons);
foreach (Skeleton skeletonData in skeletons)
{
if (skeletonData.TrackingState == SkeletonTrackingState.Tracked)
{
Microsoft.Kinect.SkeletonPoint rightHandVec = skeletonData.Joints[JointType.HandRight].Position;
var depthPoint = _kinectSensor.MapSkeletonPointToDepth(rightHandVec
, DepthImageFormat.Resolution640x480Fps30);
HandTop = depthPoint.Y * this.MainStage.ActualHeight / 480;
HandLeft = depthPoint.X * this.MainStage.ActualWidth / 640;
}
}
}
}
上面是多有設計到手部追蹤的代碼。一旦我們設置好HandTop和HandLeft屬性後,UI界面上的十字光標位置就會自動更新。
接下來我們需要實現語音識別部分的邏輯。SpeechRecognitionEngine中的StartSpeechRecognition方法必須找到正確的語音識別庫來進行語音識別。下面的代碼展示了如何設置語音識別庫預計如何將KinectAudioSource傳遞給語音識別引起。我們還添加了SpeechRecognized,SpeechHypothesized以及SpeechRejected事件對應的方法。SetInputToAudioStream中的參數和前篇文章中的含義一樣,這裡不多解釋了。注意到SpeechRecognitionEngine和KinectAudioSource都是Disposable類型,因此在整個應用程序的周期內,我們要保證這兩個對象都處於打開狀態。
private void StartSpeechRecognition()
{
_source = CreateAudioSource();
Func<RecognizerInfo, bool> matchingFunc = r =>
{
string value;
r.AdditionalInfo.TryGetValue("Kinect", out value);
return "True".Equals(value, StringComparison.InvariantCultureIgnoreCase)
&& "en-US".Equals(r.Culture.Name, StringComparison.InvariantCultureIgnoreCase);
};
RecognizerInfo ri = SpeechRecognitionEngine.InstalledRecognizers().Where(matchingFunc).FirstOrDefault();
_sre = new SpeechRecognitionEngine(ri.Id);
CreateGrammars(ri);
_sre.SpeechRecognized += sre_SpeechRecognized;
_sre.SpeechHypothesized += sre_SpeechHypothesized;
_sre.SpeechRecognitionRejected += sre_SpeechRecognitionRejected;
Stream s = _source.Start();
_sre.SetInputToAudioStream(s,
new SpeechAudioFormatInfo(
EncodingFormat.Pcm, 16000, 16, 1,
32000, 2, null));
_sre.RecognizeAsync(RecognizeMode.Multiple);
}
要完成程序邏輯部分,我們還需要處理語音識別時間以及語音邏輯部分,以使得引擎能夠直到如何處理和執行我們的語音命令。SpeechHypothesized以及SpeechRejected事件代碼如下,這兩個事件的邏輯很簡單,就是更新UI界面上的label。SpeechRecognized事件有點復雜,他負責處理傳進去的語音指令,並對識別出的指令執行相應的操作。另外,該事件還負責創建一些GUI對象(實際就是命令模式),我們必須使用Dispatcher對象來發揮InterpretCommand到主UI線程中來。
void sre_SpeechRecognitionRejected(object sender, SpeechRecognitionRejectedEventArgs e)
{
HypothesizedText += " Rejected";
Confidence = Math.Round(e.Result.Confidence, 2).ToString();
}
void sre_SpeechHypothesized(object sender, SpeechHypothesizedEventArgs e)
{
HypothesizedText = e.Result.Text;
}
void sre_SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
Dispatcher.BeginInvoke(new Action<SpeechRecognizedEventArgs>(InterpretCommand), e);
}
現在到了程序核心的地方。創建語法邏輯並對其進行解析。本例中的程序識別普通的以“put”或者“create”開頭的命令。前面是什麼我們不關心,緊接著應該是一個顏色,然後是一種形狀,最後一個詞應該是“there”。下面的代碼顯示了創建的語法。
private void CreateGrammars(RecognizerInfo ri)
{
var colors = new Choices();
colors.Add("cyan");
colors.Add("yellow");
colors.Add("magenta");
colors.Add("blue");
colors.Add("green");
colors.Add("red");
var create = new Choices();
create.Add("create");
create.Add("put");
var shapes = new Choices();
shapes.Add("circle");
shapes.Add("triangle");
shapes.Add("square");
shapes.Add("diamond");
var gb = new GrammarBuilder();
gb.Culture = ri.Culture;
gb.Append(create);
gb.AppendWildcard();
gb.Append(colors);
gb.Append(shapes);
gb.Append("there");
var g = new Grammar(gb);
_sre.LoadGrammar(g);
var q = new GrammarBuilder{ Culture = ri.Culture };
q.Append("quit application");
var quit = new Grammar(q);
_sre.LoadGrammar(quit);
}
上面的代碼中,我們首先創建一個Choices對象,這個對象會在命令解析中用到。在程序中我們需要顏色和形狀對象。另外,第一個單詞是“put”或者“create”,因此我們也創建Choices對象。然後使用GrammarBuilder類將這些對象組合到一起。首先是”put”或者“create”然後是一個占位符,因為我們不關心內容,然後是一個顏色Choices對象,然後是一個形狀Choices對象,最後是一個“there”單詞。
我們將這些語法規則加載進語音識別引擎。同時我們也需要有一個命令來停止語音識別引擎。因此我們創建了第二個語法對象,這個對象只有一個”Quit”命令。然後也將這個語法規則加載到引擎中。
一旦識別引擎確定了要識別的語法,真正的識別工作就開始了。被識別的句子必須被解譯,出別出來想要的指令後,我們必須決定如何進行下一步處理。下面的代碼展示了如何處理識別出的命令,以及如何根據特定的指令來講圖形元素繪制到UI界面上去。
private void InterpretCommand(SpeechRecognizedEventArgs e)
{
var result = e.Result;
Confidence = Math.Round(result.Confidence, 2).ToString();
if (result.Confidence < 95 && result.Words[0].Text == "quit" && result.Words[1].Text == "application")
{
this.Close();
}
if (result.Words[0].Text == "put" || result.Words[0].Text == "create")
{
var colorString = result.Words[2].Text;
Color color;
switch (colorString)
{
case "cyan": color = Colors.Cyan;
break;
case "yellow": color = Colors.Yellow;
break;
case "magenta": color = Colors.Magenta;
break;
case "blue": color = Colors.Blue;
break;
case "green": color = Colors.Green;
break;
case "red": color = Colors.Red;
break;
default:
return;
}
var shapeString = result.Words[3].Text;
Shape shape;
switch (shapeString)
{
case "circle":
shape = new Ellipse();
shape.Width = 150;
shape.Height = 150;
break;
case "square":
shape = new Rectangle();
shape.Width = 150;
shape.Height = 150;
break;
case "triangle":
var poly = new Polygon();
poly.Points.Add(new Point(0, 0));
poly.Points.Add(new Point(150, 0));
poly.Points.Add(new Point(75, -150));
shape = poly;
break;
case "diamond":
var poly2 = new Polygon();
poly2.Points.Add(new Point(0, 0));
poly2.Points.Add(new Point(75, 150));
poly2.Points.Add(new Point(150, 0));
poly2.Points.Add(new Point(75, -150));
shape = poly2;
break;
default:
return;
}
shape.SetValue(Canvas.LeftProperty, HandLeft);
shape.SetValue(Canvas.TopProperty, HandTop);
shape.Fill = new SolidColorBrush(color);
MainStage.Children.Add(shape);
}
}
查看本欄目
方法中,我們首先檢查語句識別出的單詞是否是”Quit”如果是的,緊接著判斷第二個單詞是不是”application”如果兩個條件都滿足了,就不進行繪制圖形,直接返回。如果有一個條件不滿足,就繼續執行下一步。
InterpretCommand方法然後判斷第一個單詞是否是“create”或者“put”,如果不是這兩個單詞開頭就什麼也不執行。如果是的,就判斷第三個單詞,並根據識別出來的顏色創建對象。如果第三個單詞沒有正確識別,應用程序也停止處理。否則,程序判斷第四個單詞,根據接收到的命令創建對應的形狀。到這一步,基本的邏輯已經完成,最後第五個單詞用來確定整個命令是否正確。命令處理完了之後,將當前受的X,Y坐標賦給創建好的對象的位置。
運行程序後,按照語法設定的規則就可以通過語音以及骨骼追蹤協作來創建對象了。
有一點遺憾的是,Kinect的語音識別目前不支持中文,即使在5月份發布的SDK1.5版本增加的識別語言種類中也沒有中文,也有可能是因為目前Xbox和kinect沒有在中國大陸銷售的原因吧。所以大家只有用英語進行測試了。
3. 結語
本文接上文,用一個顯示語音來源方向的例子展示了語音識別中的方向識別。用一個簡單的語音識別結合骨骼追蹤來演示了如何根據語音命令來執行一系列操作。在語音命令識別中詳細介紹了語音識別語法對象邏輯的建立,以及語音識別引擎相關事件的處理。希望本文對您了解Kinect SDK中的語音識別有所幫助。
下文將介紹在Kinect開發中可能會用到的一些第三方類庫和開發工具,敬請期待!
作者: yangecnu(yangecnu's Blog on 博客園)
出處:http://www.cnblogs.com/yangecnu/