Kinect的麥克風陣列在Kinect設備的下方。這一陣列由4個獨立的水平分布在Kinect下方的麥克風組成。雖然每一個麥克風都捕獲相同的音頻信號,但是組成陣列可以探測到聲音的來源方向。使得能夠用來識別從某一個特定的方向傳來的聲音。麥克風陣列捕獲的音頻數據流經過復雜的音頻增強效果算法處理來移除不相關的背景噪音。所有這些復雜操作在Kinect硬件和Kinect SDK之間進行處理,這使得能夠在一個大的空間范圍內,即使人離麥克風一定的距離也能夠進行語音命令的識別。
在Kinect第一次作為Xbox360的外設發布時,骨骼追蹤和語音識別是Kinect SDK最受開發者歡迎的特性,但是相比骨骼追蹤,語音識別中麥克風陣列的強大功能有一點被忽視了。一部分原因歸於Kinect中的令人興奮的骨骼追蹤系統,另一部分原因在於Xbox游戲操控面板以及Kinect體感游戲沒有充分發揮Kinect音頻處理的優點。
作為一個開始使用Kinect進行應用開發的開發者,Kinect上的麥克風陣列的出現使得基於Kinect應用程序的功能更加強大。雖然Kinect的視覺分析令人印象深刻,但是仍然不能很好的對馬達進行控制。當我們從一種人機交互界面切換到另一種人機交互界面:如從命令行交互應用程序到標簽頁交互界面,再到鼠標圖形用戶界面或者觸摸交互界面時,每一種交互界面都提供了各種最基本的更加容易實現的操作,這個操作就是選擇。進一步,可以說,每一種交互界面都改進了我們對對象進行選擇的能力。奇怪的是,Kinect破壞了這一趨勢。
在Kinect應用程序中,選擇操作是最復雜和難以掌握的行為之一。Xbox360中最初的選擇操作是通過將手放到特定的位置,然後保持一段時間。在《舞林大會》游戲中,通過一個短暫的停頓加上滑動操作來對選擇操作進行了一點改進。這一改進也被應用在了Xbox的操作面板中。另外的對選擇進行改進的操作包括某種特定的手勢,如將胳膊舉起來。
這些問題,可以通過將語音識別指令和骨骼追蹤系統結合起來產生一個復合的姿勢來相對簡單的解決:保持某一動作,然後通過語音執行。菜單的設計也可以通過首先展示菜單項,然後讓用戶說出菜單項的名稱來進行選擇-很多Xbox中的游戲已經使用了這種方式。可以預見,無論是程序開發者還是游戲公司,這種復合的解決方案在未來會越來越多的應用到新的交互方式中,而不用再像以前那樣使用指然後點(point and click)這種方式來選擇。
1. 麥克風陣列
安裝完Microsoft Kinect SDK之後,語音識別的組件會自動安裝。Kinect的麥克風陣列工作在一些語音識別的類庫之上,這些類庫是從Vista系統之時就有的。他們包括語音捕獲DirectX多媒體對象(DirectX Media Object,DMO)以及語音識別API(Speech Recognition API,SAPI)。
在C#中,Kinect SDK提供了對語音捕獲DMO的封裝。語音捕獲DMO最初是被設計用來給麥克風陣列提供API來支持一些功能如回聲消除(acoustic echo cancellation,AEC),自動增益控制(automatic gain control,AGC)和噪聲抑制(noise suppression)。這些功能在SDK的音頻控制類中可以找到。 Kinect SDK中音頻處理對語音捕獲DMO進行了簡單封裝,並專門針對Kinect傳感器進行了性能優化。為了能夠使用Kinect SDK進行語音識別,自動安裝的類庫包括:Speech Platform API, Speech Platform SDK和Kinect for Windows Runtime Language Pack。
語音識別API能夠簡化操作系統自帶的語音識別所需的類庫。例如,如果你想通過普通的麥克風而不是Kinect麥克風陣列添加一些語音指令到桌面應用程序中去,可以使用也可以不使用Kinect SDK。
Kinect for windows 運行語言包是一系列的語言模型,用來在Kinect SDK和語音識別API組件之間進行互操作。就像Kinect骨骼識別需要大量的計算模型來提供決策樹信息來分析節點位置那樣,語音識別API也需要復雜的模型來輔助解釋從Kinect麥克風陣列接收到的語言模型。Kinect語言包提供了這些模型來優化語音指令的識別。
1.1 MSR Kinect Audio
Kinect中處理音頻主要是通過KinectAudioSource這個對象來完成的。KinectAudioSource類的主要作用是從麥克風陣列中提取原始的或者經過處理的音頻流。音頻流可能會經過一系列的算法來處理以提高音頻質量,這些處理包括:降噪、自動增益控制和回聲消除。KinectAudioSource能夠進行一些配置使得Kinect麥克風陣列可以以不同的模式進行工作。也能夠用來探測從那個方向來的哪種音頻信息最先達到麥克風以及用來強制麥克風陣列接受指定方向的音頻信息。
本節盡量不會去介紹一些音頻處理技術方面的較低層次的技術。但是為了使用KinectAudioSource,了解語音捕獲以及語音傳輸中的一些術語可能會對熟悉KinectAudioSource中的一些屬性和方法有所幫助。
回聲消除(acoustic echo cancellation, AEC) 當用戶的聲音從麥克風返回時,就會產生回聲。最簡單的例子就是用戶在打電話時能夠聽到自己的聲音,這些聲音有一些延遲,會在對方那裡重復一段時間。回聲消除通過提取發聲者的聲音模式,然後根據這一模式從麥克風接收到的音頻中挑選出特定的音頻來消除回聲。
回聲抑制(acoustic echo suppression, AES) 它是指通過一系列的算法來進一步消除AEC處理後所遺留的回聲。
自動增益控制(acoustic gain control, AGS) 它涉及到一些算法用來使用戶的聲音的振幅與時間保持一致。例如當用戶靠近或者或遠離麥克風時,聲音會出現變得響亮或更柔和,AGC通過算法使得這一過程變得更加明顯。
波束成形(beamforming) 指的是模擬定向麥克風的算法技術。和只有一個麥克風不同,波速成形技術用於麥克風陣列中 (如Kinect 傳感器上的麥克風陣列)使得麥克風陣列產生和使用多個固定麥克風的效果相同。
中心削波(center clipping) 用來移除在單向傳輸中經AEC處理後殘留的小的回聲。
幀尺寸(Frame Size) AEC算法處理PCM音頻樣本是是一幀一幀處理的。幀尺寸是樣本中音頻幀的大小。
獲取增益邊界(Gain Bounding) 該技術確保麥克風有正確的增益級別。如果增益過高,獲取到的信號可能過於飽和,會被剪切掉。這種剪切有非線性的效果,會使得AEC算法失敗。如果增益過低,信噪比會比較低,也會使得AEC算法失敗或者執行的不好。
噪聲填充(Noise Filling) 向中心削波移除了殘留的回波信號後的部分信號中添加少量的噪音。和留下空白的沉默信號相比,這能夠獲得更好的用戶體驗。
噪聲抑制 (NS) 用於從麥克風接收到的音頻信號中剔除非言語聲音。通過刪除背景噪音,實際講話者的聲音能夠被麥克風更清楚更明確的捕獲到。
Optibeam Kinect傳感器從四個麥克風中能夠獲得11個波束。 這11個波束是邏輯結構,而四個通道是物理結構。Optibeam 是一種系統模式用來進行波束成形。
信噪比(Signal-to-Noise Ratio,SNR) 信號噪聲比用來度量語音信號和總體背景噪聲的比例,信噪比越高越好。
單通道(Single Channel) Kinect傳感器有四個麥克風,因此支持4個通道,單通道是一種系統模式用來關閉波束成形。
KinectAudioSource類提供一些對音頻捕獲多方面的較高層次的控制,雖然它並沒有提供DMO中的所有功能。KinectAudioSource中用來調整音頻處理的各種屬性被稱之為功能(features)屬性。下表中列出了可以調整的功能屬性。Kinect SDK早期的Beta版本視圖提供了DMO中的所有功能以使得能夠有更加強大的控制能力,但是這也極大的增加了復雜度。SDK的正式版本提取了DMO中的所有可能的配置然後將其封裝為特征屬性使得我們不用關心底層的配置細節。對於沒有接觸過這些底層配置屬性的開發者來說,這是一種巨大的解脫。
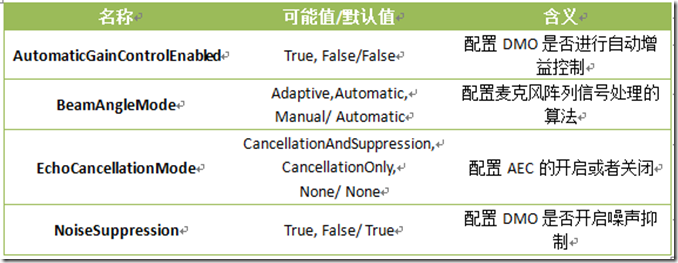
EchoCancellationMode是一個隱藏在不起眼的名稱後面神奇的技術之一。他可能的設置如下表。為了適應AEC,需要給EchoCancellationSpeakerIndex屬性賦一個int值來指定那一個用戶的噪音需要控制。SDK會自動執行活動麥克風的發現和初始化。

BeamAngleMode對底層的DMO系統模式和麥克風陣列屬性進行了抽象封裝。在DMO級別上,他決定了是由DMO還是應用程序進行波束成形。在這一基礎上Kinect for Windows SDK提供了額外的一系列算法來進行波束成行。通常,可以將該屬性設置為Adaptive,將這些復雜的操作交給SDK進行處理。下表展示了每一個可設置值的屬性。

自適應波速成形(Adaptive beamforming)能夠發揮Kinect傳感器的特性優勢,根據骨骼追蹤所找到的游戲者,從而找出正確的聲音源。和骨骼追蹤一樣,Kinect的波束成形特性也能夠使用手動模式,允許應用程序來設定要探測聲音的方向。要使用Kinect傳感器作為定向的麥克風,需要將波束角度模式設定為Manual然後設置KinectAudioSource的ManualBeamAngle屬性。
1.2 語音識別
語音識別可以分為兩類:對特定命令的識別(recognition of command)和對自由形式的語音的識別(recognition of free-form dictation)。自由形式的語音識別需要訓練軟件來識別特定的聲音以提高識別精度。一般做法是讓講話人大聲的朗讀一系列的語料來使得軟件能夠識別講話人聲音的特征模式,然後根據這一特征模式來進行識別。
而命令識別(Command recognition)則應用了不同的策略來提高識別精度。和必須識別說話人聲音不同,命令識別限制了說話人所講的詞匯的范圍。基於這一有限的范圍,命令識別可以不需要熟悉講話人的語音模式就可以推斷出說話人想要說的內容。
考慮到Kinect的特性,使用Kinect進行自由形式的語音識別沒有多大意義。Kinect SDK的設計初衷是讓大家能夠簡單容易的使用,因此,SDK提供了Microsoft.Speech類庫來原生支持語音命令的識別。Microsoft.Speech類庫是Microsoft語音識別技術的服務器版本。如果你想使用System.Speech類庫中的語音識別能力,可以使用Windows操作系統內建的桌面版語音識別來通過Kinect的麥克風來建立一個自由語音識別系統。但是通過將Kinect的麥克風和System.Speech類庫組合開發的自由語音識別系統的識別效果可能不會太好。這是因為Kinect for windows運行時語言包,能夠適應從開放空間中的聲音,而不是從麥克風發出的聲音,這些語言模型在 System.Speech 中不能夠使用。
Microsoft.Speech類庫的語音識別功能是通過SpeechRecognitionEngine對象提供的。SpeechRecognitionEngine類是語音識別的核心,它負責從Kinect傳感器獲取處理後的音頻數據流,然後分析和解譯這些數據流,然後匹配出最合適的語音命令。引擎給基本發聲單元一定的權重,如果判斷出發聲包含特定待識別的命令,就通過事件進行進一步處理,如果不包含,直接丟掉這部分音頻數據流。
我們需要告訴SpeechRecognitionEngine從一個特定的稱之為語法(grammars)的對象中進行查找。Grammar對象由一系列的單個單詞或者詞語組成。如果我們不關心短語的部分內容,可以使用語法對象中的通配符。例如,我們可能不會在意命令包含短語"an" apple或者"the" apple,語法中的通配符告訴識別引擎這兩者都是可以接受的。此外,我們還可以添加一個稱之為Choices的對象到語法中來。選擇類(Choices)是通配符類(Wildcard)的一種,它可以包含多個值。但與通配符不同的是,我們可以指定可接受的值的順序。例如如果我們想要識別“Give me some fruit”我們不關心fruit單詞之前的內容,但是我們想將fruit替換為其它的值,如apple,orange或者banana等值。這個語法可以通過下面的代碼來實現。Microsoft.Speech類庫中提供了一個GrammarBuilder類來建立語法(grammars)。
var choices = new Choices();
choices.Add("fruit");
choices.Add("apple");
choices.Add("orange");
choices.Add("banana");
var grammarBuilder = new GrammarBuilder();
grammarBuilder.Append("give");
grammarBuilder.Append("me");
grammarBuilder.AppendWildcard();
grammarBuilder.Append(choices);
var grammar = new Grammar(grammarBuilder);
語法中的單詞不區分大小寫,但是出於一致性考慮,要麼都用大寫,要麼都用小寫。
語音識別引擎使用LoadGrammar方法將Grammars對象加載進來。語音識別引擎能夠加載而且通常是加載多個語法對象。識別引擎有3個事件:SpeechHypothesized,SpeechRecognized和SpeechRecognitionRejected。 SpeechHypothesized事件是識別引擎在決定接受或者拒絕用戶命令之前解釋用戶說話的內容。SpeechRecognitionRejected用來處理識別命令失敗時需要執行的操作。SpeechRecognized是最重要的事件,他在引擎決定接受用戶的語音命令時觸發。該事件觸發時,通過SpeechRecognizedEventArgs對象參數傳遞一些數據。SpeechRecognizedEventArgs類有一個Result屬性,該屬性描述如下:

實例化SpeechRecognitionEngine對象需要執行一系列特定的步驟。首先,需要設置識別引擎的ID編號。當安裝了服務器版本的Microsoft語音庫時,名為Microsoft Lightweight Speech Recognizier的識別引擎有一個為SR_MS_ZXX_Lightweight_v10.0的ID值(這個值根據你所安裝的語音庫的不同而不同)。當安裝了Kinect for Windows運行時語音庫時,第二個ID為Server Speech Recognition Language-Kinect(en-US)的語音庫可以使用。這是Kinect中我們可以使用的第二個識別語音庫。下一步SpeechRecognitionEngine需要指定正確的識別語音庫。由於第二個語音識別庫的ID可能會在以後有所改變,我們需要使用模式匹配來找到這一ID。最後,語音識別引擎需要進行配置,以接收來自KinectAudioSource對象的音頻數據流。下面是執行以上過程的樣板代碼片段。
var source = new KinectAudioSource();
Func<RecognizerInfo, bool> matchingFunc = r =>
{
String value;
r.AdditionalInfo.TryGetValue("Kinect", out value);
return "True".Equals(value, StringComparison.InvariantCultureIgnoreCase)
&& "en-US".Equals(r.Culture.Name, StringComparison.InvariantCultureIgnoreCase);
};
RecognizerInfo ri = SpeechRecognitionEngine.InstalledRecognizers().Where(matchingFunc).FirstOrDefault();
var sre = new SpeechRecognitionEngine(ri.Id);
KinectSensor.KinectSensors[0].Start();
Stream s = source.Start();
sre.SetInputToAudioStream(s,new SpeechAudioFormatInfo(EncodingFormat.Pcm, 16000, 16, 1, 32000, 2, null));
sre.Recognize();
SetInputToAudioStream方法的第二個參數用來設置從Kinect獲取的音頻數據流的格式。在上面的代碼中,我們設置音頻編碼格式為Pulse Code Modulation(PCM),每秒接收16000個采樣,每個樣本占16位,只有1個通道,每秒中產生32000字節數據,塊對齊值設置為2。
Grammars加載到語音識別引擎後,引擎必須啟動後才能進行識別,啟動引擎有幾種模式,可以使用同步或者異步模式啟動。另外也可以識別一次或者繼續識別從KinectAudioSource傳來的多條語音命令。下表列出了開始語音識別的可選方法。

在文將使用一些簡單的例子來展示如何使用KinectAudioSource和SpeechRecognitionEngine類。
2. 獲取音頻數據
雖然 KinectAudioSource 類的最主要作用是為語音識別引擎提供音頻數據流,但是它也可以用於其他目的。他還能夠用來錄制 wav 文件。下面的示例將使用KinectAudioSource來開發一個音頻錄音機。使用這個項目作為錄音機,讀者可以修改Kinect sdk中KinectAudioSource的各個參數的默認值的來了解這些參數是如何控制音頻數據流的產生。
2.1 使用音頻數據流
雖然使用的是Kinect的音頻相關類,而不是視覺元素類,但是建立一個Kinect音頻項目的過程大致是類似的。
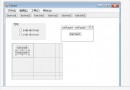
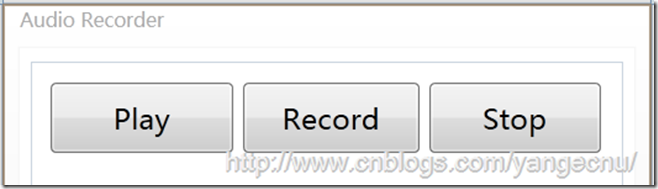
1. 創建一個名為KinectAudioRecorder的WPF應用項目。
2. 添加對Microsoft.Kinect.dll和Microsoft.Speech.dll的引用。
3. 在MainWindows中添加名為Play,Record和Stop三個按鈕。
4. 將主窗體的名稱改為“Audio Recorder”
在VS的設計視圖中,界面看起來應該如下:
令人遺憾的是,C#沒有一個方法能夠直接寫入wav文件。為了能夠幫助我們生成wav文件,我們使用下面自定義的RecorderHelper類,該類中有一個稱之為WAVFORMATEX的結構,他是C++中對象轉換過來的,用來方便我們對音頻數據進行處理。該類中也有一個稱之為IsRecording的屬性來使得我們可以停止錄制。類的基本結構,以及WAVFORMATEX的結構和屬性如下。我們也需要初始化一個私有名為buffer字節數組用來緩存我們從Kinect接收到的音頻數據流。
class RecorderHelper
{
static byte[] buffer = new byte[4096];
static bool _isRecording;
public static bool IsRecording
{
get
{
return _isRecording;
}
set
{
_isRecording = value;
}
}
struct WAVEFORMATEX
{
public ushort wFormatTag;
public ushort nChannels;
public uint nSamplesPerSec;
public uint nAvgBytesPerSec;
public ushort nBlockAlign;
public ushort wBitsPerSample;
public ushort cbSize;
}
}
為了完成這個幫助類,我們還需要添加三個方法:WriteString,WriteWavHeader和WriteWavFile方法。WriteWavFile方法如下,方法接受KinectAudioSource和FileStream對象,從KinectAudioSource對象中我們可以獲取音頻數據,我們使用FileStream來寫入數據。方法開始寫入一個假的頭文件,然後讀取Kinect中的音頻數據流,然後填充FileStream對象,直到_isRecoding屬性被設置為false。然後檢查已經寫入到文件中的數據流大小,用這個值來改寫之前寫入的文件頭。
public static void WriteWavFile(KinectAudioSource source, FileStream fileStream)
{
var size = 0;
//write wav header placeholder
WriteWavHeader(fileStream, size);
using (var audioStream = source.Start())
{
//chunk audio stream to file
while (audioStream.Read(buffer, 0, buffer.Length) > 0 && _isRecording)
{
fileStream.Write(buffer, 0, buffer.Length);
size += buffer.Length;
}
}
//write real wav header
long prePosition = fileStream.Position;
fileStream.Seek(0, SeekOrigin.Begin);
WriteWavHeader(fileStream, size);
fileStream.Seek(prePosition, SeekOrigin.Begin);
fileStream.Flush();
}
public static void WriteWavHeader(Stream stream, int dataLength)
{
using (MemoryStream memStream = new MemoryStream(64))
{
int cbFormat = 18;
WAVEFORMATEX format = new WAVEFORMATEX()
{
wFormatTag = 1,
nChannels = 1,
nSamplesPerSec = 16000,
nAvgBytesPerSec = 32000,
nBlockAlign = 2,
wBitsPerSample = 16,
cbSize = 0
};
using (var bw = new BinaryWriter(memStream))
{
WriteString(memStream, "RIFF");
bw.Write(dataLength + cbFormat + 4);
WriteString(memStream, "WAVE");
WriteString(memStream, "fmt ");
bw.Write(cbFormat);
bw.Write(format.wFormatTag);
bw.Write(format.nChannels);
bw.Write(format.nSamplesPerSec);
bw.Write(format.nAvgBytesPerSec);
bw.Write(format.nBlockAlign);
bw.Write(format.wBitsPerSample);
bw.Write(format.cbSize);
WriteString(memStream, "data");
bw.Write(dataLength);
memStream.WriteTo(stream);
}
}
}
static void WriteString(Stream stream, string s)
{
byte[] bytes = Encoding.ASCII.GetBytes(s);
stream.Write(bytes, 0, bytes.Length);
}
使用該幫助方法,我們可以開始建立和配置KinectAudioSource對象。首先添加一個私有的_isPlaying 布爾值來保存是否我們想要播放錄制的wav文件。這能夠幫助我們避免錄音和播放功能同事發生。除此之外,還添加了一個MediaPlayer對象用來播放錄制好的wav文件。_recodingFileName用來保存最近錄制好的音頻文件的名稱。代碼如下所示,我們添加了幾個屬性來關閉和開啟這三個按鈕,他們是:IsPlaying,IsRecording,IsPlayingEnabled,IsRecordingEnabled和IsStopEnabled。為了使得這些對象可以被綁定,我們使MainWindows對象實現INotifyPropertyChanged接口,然後添加一個NotifyPropertyChanged事件以及一個OnNotifyPropertyChanged幫助方法。
在設置各種屬性的邏輯中,先判斷IsRecording屬性,如果為false,再設置IsPlayingEnabled屬性。同樣的先判斷IsPlaying屬性為是否false,然後在設置IsRecordingEnabled屬性。前端的XAML代碼如下:
<Window x:Class="KinectRecordAudio.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Audio Recorder" Height="226" Width="405">
<Grid Width="369" Height="170">
<Button Content="Play" Height="44" HorizontalAlignment="Left" Margin="12,13,0,0" Name="button1" VerticalAlignment="Top" Width="114" Click="button1_Click" IsEnabled="{Binding IsPlayingEnabled}" FontSize="18"></Button>
<Button Content="Record" Height="44" HorizontalAlignment="Left" Margin="132,13,0,0" Name="button2" VerticalAlignment="Top" Width="110" Click="button2_Click" IsEnabled="{Binding IsRecordingEnabled}" FontSize="18"/>
<Button Content="Stop" Height="44" HorizontalAlignment="Left" Margin="248,13,0,0" Name="button3" VerticalAlignment="Top" Width="107" Click="button3_Click" IsEnabled="{Binding IsStopEnabled}" FontSize="18"/>
</Grid>
</Window>
MainWindow構造函數中實例化一個MediaPlayer對象,將其存儲到_mediaPlayer變量中。因為Media Player對象在其自己的線程中,我們需要捕獲播放完成的時間,來重置所有按鈕的狀態。另外,我們使用WPF中的技巧來使得我們的MainWindow綁定IsPlayingEnabled以及屬性。我們將MainPage的DataContext屬性設置給自己。這是提高代碼可讀性的一個捷徑,雖然典型的做法是將這些綁定屬性放置到各自單獨的類中。
public MainWindow()
{
InitializeComponent();
this.Loaded += delegate { KinectSensor.KinectSensors[0].Start(); };
_mplayer = new MediaPlayer();
_mplayer.MediaEnded += delegate { _mplayer.Close(); IsPlaying = false; };
this.DataContext = this;
}
現在,我們准備好了實例化KinectAudioSource類,並將其傳遞給之前創建的RecordHelper類。為了安全性,我們給RecordKinectAudio方法添加了鎖。在加鎖之前我們將IsRunning屬性設置為true,方法結束後,將該屬性設置回false。
private object lockObj = new object();
private void RecordKinectAudio()
{
lock (lockObj)
{
IsRecording = true;
var source = CreateAudioSource();
var time = DateTime.Now.ToString("hhmmss");
_recordingFileName = time + ".wav";
using (var fileStream =
new FileStream(_recordingFileName, FileMode.Create))
{
RecorderHelper.WriteWavFile(source, fileStream);
}
IsRecording = false;
}
}
private KinectAudioSource CreateAudioSource()
{
var source = KinectSensor.KinectSensors[0].AudioSource;
source.BeamAngleMode = BeamAngleMode.Adaptive;
source.NoiseSuppression = _isNoiseSuppressionOn;
source.AutomaticGainControlEnabled = _isAutomaticGainOn;
if (IsAECOn)
{
source.EchoCancellationMode = EchoCancellationMode.CancellationOnly;
source.AutomaticGainControlEnabled = false;
IsAutomaticGainOn = false;
source.EchoCancellationSpeakerIndex = 0;
}
return source;
}
為了保證不對之前錄制好的音頻文件進行再次寫入,我們在每個音頻文件錄制完了之後,使用當前的時間位文件名創建一個新的音頻文件。最後一步就是錄制和播放按鈕調用的方法。UI界面上的按鈕調用Play_Click和Record_Click方法。這些方法只是調用實際對象的Play和Record方法。需要注意的是下面的Record方法,重新開啟了一個新的線程來執行RecordKinectAudio方法。
private void Play()
{
IsPlaying = true;
_mplayer.Open(new Uri(_recordingFileName, UriKind.Relative));
_mplayer.Play();
}
private void Record()
{
Thread thread = new Thread(new ThreadStart(RecordKinectAudio));
thread.Priority = ThreadPriority.Highest;
thread.Start();
}
private void Stop()
{
KinectSensor.KinectSensors[0].AudioSource.Stop();
IsRecording = false;
}
現在就可以使用Kinect來錄制音頻文件了。運行程序,點擊錄制按鈕,然後在房間裡走動,以測試Kinect從不同距離錄制的聲音效果。在CreateAudioSource方法中,麥克風陣列配置為使用自適應波束成形,因此當你說話時,會跟隨錄制。點擊停止錄制按鈕結束錄制。然後點擊播放,就可以播放剛才錄制的音頻文件了。
2.2 對音頻數據進行處理
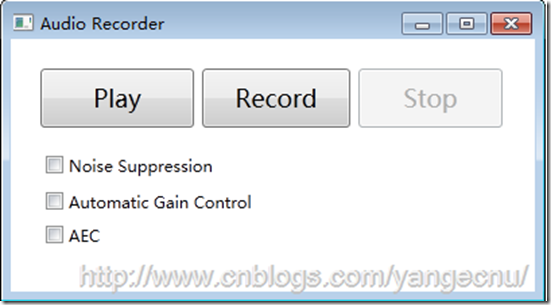
我們可以將之前的例子進行擴展,添加一些屬性配置。在本節中,我們添加對噪音抑制和自動增益屬性開關的控制。下圖顯示了修改後的程序界面。
bool _isNoiseSuppressionOn; bool _isAutomaticGainOn; bool _isAECOn;
使用之前OnPropertyChanged幫助方法,我們能夠創建一個綁定屬性。代碼如下:
public bool IsNoiseSuppressionOn
{
get
{
return _isNoiseSuppressionOn;
}
set
{
if (_isNoiseSuppressionOn != value)
{
_isNoiseSuppressionOn = value;
OnPropertyChanged("IsNoiseSuppressionOn");
}
}
}
public bool IsAutomaticGainOn
{
get
{
return _isAutomaticGainOn;
}
set
{
if (_isAutomaticGainOn != value)
{
_isAutomaticGainOn = value;
OnPropertyChanged("IsAutomaticGainOn");
}
}
}
查看本欄目
邏輯部分代碼寫好後,在界面上添加幾個Checkbox來控制.
<CheckBox Content="Noise Suppression" Height="16" HorizontalAlignment="Left" Margin="16,77,0,0" VerticalAlignment="Top" Width="142" IsChecked="{Binding IsNoiseSuppressionOn}" />
<CheckBox Content="Automatic Gain Control" Height="16" HorizontalAlignment="Left" Margin="16,104,0,0" VerticalAlignment="Top" IsChecked="{Binding IsAutomaticGainOn}"/>
<CheckBox Content="AEC" Height="44" HorizontalAlignment="Left" IsChecked="{Binding IsAECOn}" Margin="16,129,0,0" VerticalAlignment="Top" />
最後在CreateAudioSource方法中綁定這些值.
private KinectAudioSource CreateAudioSource()
{
var source = KinectSensor.KinectSensors[0].AudioSource;
source.BeamAngleMode = BeamAngleMode.Adaptive;
source.NoiseSuppression = _isNoiseSuppressionOn;
source.AutomaticGainControlEnabled = _isAutomaticGainOn;
return source;
}
運行程序,然後選中這幾個選項,試著錄音,可以看到噪聲抑制在提高錄音效果的作用了。當你在房間裡來回走動,並提高或者降低聲音時,自動增益控制的效果會更加明顯。其它屬性配置的效果可能比較細微,沒有這兩個效果明顯。讀者可以自己添加幾個CheckBox進行測試。
2.3 去除回聲
回聲消除不單是KinectAudioSource類的一個屬性,他還是Kinect的核心技術之一。要測試這一特性可能會比之前的測試要復雜。
要測試AEC的效果,需要在界面上添加一個CheckBox。然後創建一個IsAECOn屬性來設置和保存這個設置的值。最後將CheckBox的IsCheck屬性綁定到IsAECOn屬性上。
我們將會在CreateAudioSource方法中配置這一屬性。代碼如下:
if (IsAECOn)
{
source.EchoCancellationMode = EchoCancellationMode.CancellationOnly;
source.AutomaticGainControlEnabled = false;
IsAutomaticGainOn = false;
source.EchoCancellationSpeakerIndex = 0;
}
上面的代碼中SystemMode屬性必須設置為Optibeam或者echo cancelation。需要關閉自動增益控制,因為在AEC下面不會起作用。另外,如果AutomaticGainOn屬性不為false的話,需要將其設置為false。這樣界面上的UI展現邏輯就有一點從沖突。AEC配置接下來需要找到我們使用的麥克風,以及正在使用麥克風的講話人,以使得AEC算法能夠從數據流中提取到需要的音頻數據。運行程序,你可以播放之前錄制的音頻文件來測試這一特征。
3. 結語
本文簡要介紹了Kinect中語音識別的基本概念,以及一些語音處理方面的術語。在此基礎上以一個使用Kinect麥克風陣列來進行音頻錄制的例子展現了Kinect中音頻處理的核心對象及其配置,限於篇幅原因,本文介紹到這裡。
作者: yangecnu(yangecnu's Blog on 博客園)
出處:http://www.cnblogs.com/yangecnu/