機器 學習領域的基本任務是將數值數據轉換為分類數據。例如,如果您擁有一個人員身高(以英 寸為單位)的數據集,如 59.5、64.0 和 75.5,則可能希望將此數值數據轉換為分類數據( 例如 0、1 和 2)來表示矮、中等、高。此過程有時俗稱“數據裝箱”。在機器學習文獻資 料中,此過程通常被稱為“連續數據的離散化”。
在以下幾種情況下,您可能需要將 數據離散化。許多機器學習算法(如 Naive Bayes 分類和預測)僅適用於分類數據。因此, 如果您的原始數據是數值數據,並且您希望應用 Naive Bayes,則必須將數據離散化。您還 可以將數值數據和分類數據混合在一起,如經常在 Excel 電子表格中找到的數據。由於僅極 少數機器學習算法適用於混合數據,因此您可以將數值數據轉換為分類數據,然後使用適用 於分類數據的機器學習算法。例如,可使用分類效用進行數據聚類分析。
可能是由於 這個主題的吸引力不夠,准確描述如何實施離散化算法的可用資源非常少。在本文中,我將 介紹一種強大的離散化算法。雖然這些理念不是最新的,但據我所知,本文中介紹的實現在 此之前未發布過。
了解本文所述觀點的最佳方法是查看圖 1 中所示的演示程序。該 演示設置了 20 個數據點,用於表示人員的身高(以英寸為單位)。圖 2 中的直方圖中顯示 了原始數據。該演示將分析數據並創建一個 Discretizer 對象,然後顯示此對象的內部表示 形式。Discretizer 在名為 data 的已排序(從低值到高值)數組中保留來自原始數據的不 同值的副本。計算所得的類別數為 3,並存儲在成員變量 k 中。
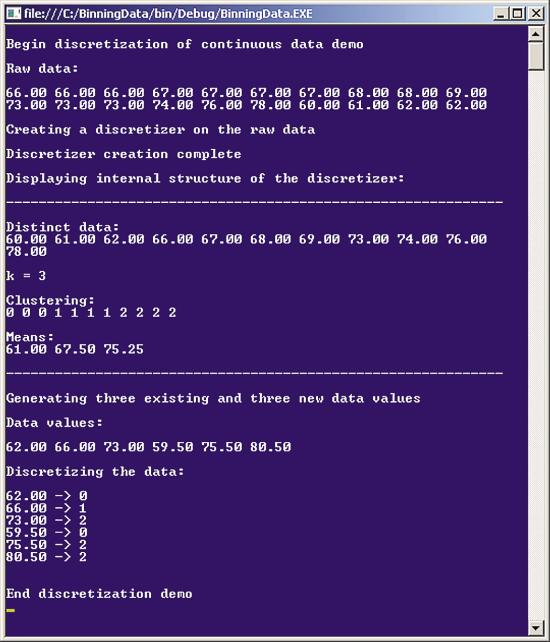
圖 1 將數值數據轉換為分類數據
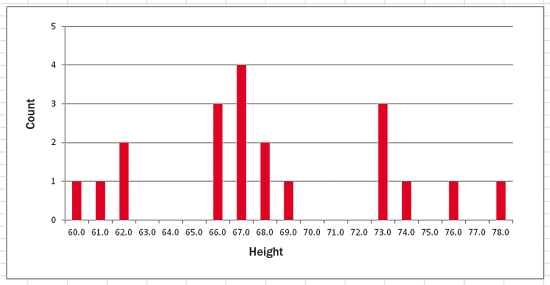
圖 2 要進行分 類的原始數據
已將每個數據點分別分配給這三個類別中的一個類別。每個類別均編碼 為從零開始的整數(即 0 到 2),分配信息存儲在名為 clustering 的數組中。已將前三個 數據點(60.0、61.0、62.0)分配給類別 0。已將接下來的四個數據點(66.0、67.0、68.0 、69.0)分配給類別 1,並將最後的四個數據點(73.0、74.0、76.0、78.0)分配給類別 2 。類別 0 中前三個數據點的算術平均數為 61.00,類別 1 和類別 2 中的數據點的算術平均 數分別為 67.50 和 75.25。
在創建 Discretizer 對象後,演示程序將設置三個現有 數據值(62.0、66.0、73.0)和三個新數據值(59.5、75.5、80.5)。這裡要說明的是,有 時得到的是固定數據集,但在其他情況下,將動態生成新的數據且必須轉換這些數據。 Discretizer 將全部 6 個數值數據點都轉換為分類數據: 分別為 0、1、2 和 0、2、2。
本文假定您至少具備中級編程技能。雖然我使用 C# 對離散化算法進行編碼,但您應 能夠輕松使用其他語言(如 Python 或 Visual Basic)重構代碼。為了將代碼保持在較短的 長度並確保主要思想盡可能清晰,我省略了大多數常規錯誤檢查步驟。演示代碼太長,無法 在本文中完全列出,但 archive.msdn.microsoft. com/mag201308TestRun 上提供了完整的源代碼。
並非想象中那麼容易
初看起來,將數值數據轉換為分類數據似乎是一個容易解決的問題。一種簡單的方法是將原 始源數據劃分為相等的區間。例如,對於演示和圖 2 中的數據,范圍為 78.0 - 60.0 = 18.0。將此范圍除以 k 將得到 3 個區間,區間寬度為 6.0 英寸。這樣一來,介於 60.0 與 66.0 之間的任何數據將分配給類別 0,介於 66.0 與 72.0 之間的數據將分配給類別 1,介 於 72.0 與 78.0 之間的數據將分配給類別 2。此相等區間方法存在的問題是,它忽略了數 據的自然間隔。如果您查看圖 2,就會發現好的離散化算法應在 63.0 和 65.0 之間的某個 位置將數據間隔開,而不是在 66.0 處。
第二種比較樸素的離散化方法是使用相等的 頻率。對於示例數據,因為有 11 個不同的數據點,k 為 3 個類別,11 / 3 = 3(使用整除 截斷),您可以將前三個數據點分配給類別 0,將接下來的三個數據點分配給類別 1,並將 最後的五個數據點分配給類別 2。此相等頻率方法也忽略了數據的自然間隔。
本文中 介紹的離散化算法使用數據聚類分析方法。使用 k 平均值算法(此算法考慮了數據的自然間 隔)對原始數據進行聚類分析,然後使用聚類分析算法所生成的平均值對新數據進行分類。 例如,在圖 1 中,三個平均數為 61.00、67.50 和 75.25。為了將數值 62.5 與一個分類值 關聯,Discretizer 將確定三個平均值中最接近 62.5 的那個值(即 61.0),然後將與 61.0 關聯的聚值(即 0)作為 62.5 的類別值進行分配。
K 平均值聚類分析
K 平均值聚類分析算法相當簡單。該算法有許多變體。在其最基本的形式中,對於 一組給定的數據點和給定數量的聚類 k,初始化過程會將每個數據點分配給隨機選定的聚類 。然後計算每個聚類中數據點的平均值。接下來將掃描每個數據點,並將其重新分配給具有 最接近此數據點的平均值的聚類。計算平均值、重新分配聚類的步驟將重復進行,直至沒有 要重新分配給新聚類的數據點。
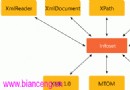
程序的整體結構
圖 1 中所示的演示程序是 單個控制台應用程序。我使用的是 Visual Studio 2012,但演示並沒有明顯的依賴性,任何 版本的 Visual Studio 和 Microsoft .NET Framework 2.0 或更高版本都應該能夠正常工作 。我創建了一個新的 C# 控制台應用程序,並將其命名為 BinningData。加載模板代碼後, 我在解決方案資源管理器窗口中將文件 Program.cs 重命名為更具描述性的 BinningProgram.cs,並且 Visual Studio 將自動重命名程序類。我刪除了源代碼頂部的所 有命名空間引用,對 System 和 Collections.Generic 的引用除外。
圖 3 顯示了程 序的整體結構(編輯了少量內容)。關鍵調用語句可以匯總如下:
double[] rawData = new int[] { 66.0, 66.0, ...
};
Discretizer d = new Discretizer(rawData);
double numericVal = 75.5;
int catVal = d.Discretize(numericVal);
圖 3 演示程序結構
using System;
using System.Collections.Generic;
namespace BinningData
{
class BinningProgram
{
static void Main(string[] args)
{
try
{
Console.WriteLine("\nBegin discretization of continuous data demo\n");
double[] rawData = new double[20] {
66, 66, 66, 67, 67, 67, 67, 68, 68, 69,
73, 73, 73, 74, 76, 78,
60, 61, 62, 62 };
Console.WriteLine("Raw data:");
ShowVector(rawData, 2, 10);
Console.WriteLine("\nCreating a discretizer on the raw data");
Discretizer d = new Discretizer(rawData);
Console.WriteLine("\nDiscretizer creation complete");
Console.WriteLine("\nDisplaying internal structure of the
discretizer:\n");
Console.WriteLine(d.ToString());
Console.WriteLine("\nGenerating three existing and three new data
values");
double[] newData = new double[6] { 62.0, 66.0, 73.0, 59.5, 75.5, 80.5 };
Console.WriteLine("\nData values:");
ShowVector(newData, 2, 10);
Console.WriteLine("\nDiscretizing the data:\n");
for (int i = 0; i < newData.Length; ++i)
{
int cat = d.Discretize(newData[i]);
Console.WriteLine(newData[i].ToString("F2") + " -> " + cat);
}
Console.WriteLine("\n\nEnd discretization demo");
Console.ReadLine();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
Console.ReadLine();
}
} // Main
public static void ShowVector(double[] vector, int decimals,
int itemsPerRow) { .
.
}
} // Program
public class Discretizer
{
public Discretizer(double[] rawData) { .
.
}
private static double[] GetDistinctValues(double[] array) { .
.
}
private static bool AreEqual(double x1, double x2) { .
.
}
public int Discretize(double x) { .
.
}
public override string ToString() { .
.
}
private void InitializeClustering() { .
.
}
private int[] GetInitialIndexes() { .
.
}
private int InitialCluster(int di, int[] initialIndexes) { .
.
}
private void Cluster() { .
.
}
private bool ComputeMeans() { .
.
}
private bool AssignAll() { .
.
}
private int MinIndex(double[] distances) { .
.
}
private static double Distance(double x1, double x2) { .
.
}
}
} // ns
Discretizer 類
Discretizer 類具有 4 個數據成員:
private double[] data;
private int k;
private double[] means;
private int[] clustering;
Discretizer 構造函數使用數值數據來啟用 Discretize 方法,該方法接受數值並返回從 零開始的整數分類值。請注意,Discretizer 將自動確定類別數。
數組數據擁有來自原始數據的不同的值,用於創建聚類分析。整數 k 為分配了數據的聚 類的數目,同時也是數據類別的數目。名為 means 的數組大小為 k,該數組包含在執行聚類 分析算法的過程中的任何給定時間分配給每個聚類的數據點的算術平均值。
名為 clustering 的數組將對在任意給定時間點對數據進行聚類分析的方式進行編碼。數 組 clustering 的索引指示存儲在數組數據中的數據點的索引,而數組 clustering 中的值 指示當前聚類分配。例如,如果 clustering[9] = 2,則 data[9] 的數據點將分配給聚類 2 。
Discretizer 構造函數
Discretizer 構造函數定義為:
public Discretizer(double[] rawData)
{
double[] sortedRawData = new double[rawData.Length];
Array.Copy(rawData, sortedRawData, rawData.Length);
Array.Sort(sortedRawData);
this.data = GetDistinctValues(sortedRawData);
this.clustering = new int[data.Length];
this.k = (int)Math.Sqrt(data.Length); // heuristic
this.means = new double[k];
this.Cluster();
}
第一步是從原始數據中提取不同的值。有多種方法可以做到這一點。此處的代碼會對原始 數據的副本進行排序,然後調用 Helper 方法 GetDistinctValues。在確定不同的值後,可 分配 clustering 數組。
以下是 GetDistinctValues 方法:
private static double[] GetDistinctValues(double[] array)
{
List<double> distinctList = new List<double>();
distinctList.Add(array[0]);
for (int i = 0; i < array.Length - 1; ++i)
if (AreEqual(array[i], array[i + 1]) == false)
distinctList.Add(array[i+1]);
double[] result = new double[distinctList.Count];
distinctList.CopyTo(result);
return result;
}
由於已對源數據進行分類,因此該方法可執行一次掃描來查找兩個連續值不相等的實例。 原始數據的類型為 double,這意味著比較兩個值是否完全相等是不可靠的,因此將使用 Helper 方法 AreEqual:
private static bool AreEqual(double x1, double x2)
{
if (Math.Abs(x1 - x2) < 0.000001) return true;
else return false;
}
方法 AreEqual 使用 0.000001 的任意接近阈值。您可能希望將此值作為輸入參數傳入 Discretizer 對象中。在此情況下,經常會使用一個名為 epsilon 的變量。
從原始數據中提取不同的值後,下一步是確定 k,它既是聚類數又是類別數。此處使用了 一個重要規則,並且 k 將成為數據項數的平方根。替代方法是編寫構造函數,以便將 k 的 值作為參數傳入。基本上,確定 k 的最佳值是一個未解決的機器學習研究問題。
計算出 k 的值後,構造函數將為數組 means 分配空間,然後調用 Cluster 方法。此方 法將對數據進行 k 平均值聚類分析,並且可使用最後的 means 數組中的值來將類別值分配 給任何數值。
聚類分析算法
Discretizer 類的核心是執行 k 平均值聚類分析的代碼。圖 4 列出 了 Cluster 方法。
圖 4 Cluster 方法
private void Cluster()
{
InitializeClustering();
ComputeMeans();
bool changed = true; bool success = true;
int ct = 0;
int maxCt = data.Length * 10; // Heuristic
while (changed == true && success == true && ct < maxCt) {
++ct;
changed = AssignAll();
success = ComputeMeans();
}
}
查看本欄目
Cluster 方法相對較短一些,因為它將所有困難的工作都移交給了 Helper 方法。 InitializeClustering 方法將所有數據點分配給初始聚類。然後使用聚類分配計算分配給每 個聚類的數據點的平均值。
在主聚類分析算法循環中,所有數據點都通過 AssignAll 方法分配給聚類。AssignAll 方法調用 Helper 方法 Distance 和 MinIndex。Distance 方法定義兩個數據點之間的距離 :
private static double Distance(double x1, double x2)
{
return Math.Sqrt((x1 - x2) * (x1 - x2));
}
此處使用的是歐氏距離(定義為方差的平方根)。由於數據點都是單個值而不是向量,而 歐氏距離等同於 Math.Abs(x1 - x2),因此您可能需要使用這種更簡單的計算方法。
在以下情況下,循環將退出:clustering 數組未發生更改(由 AssignAll 的返回值指示 ),因分配給聚類的值的計數為零而無法計算 means 數組或達到最大循環計數器值。此處向 maxCt 任意分配一個為數據點數的 10 倍的值。通常,聚類分析算法此時會極快聚合,且達 到 maxCt 的循環退出條件很可能因邏輯錯誤得到滿足,因此您可能需要檢查這一點。
由於聚類分析過程反復將值重新分配給聚類,因此分配給聚類的值的數目有可能會變為零 ,從而導致無法計算平均值。Helper 方法 ComputeMeans 嘗試計算所有 k 平均值,但如果 計數為零,則將回 false。圖 5 顯示了該方法。
圖 5 ComputeMeans 方法
private bool ComputeMeans()
{
double[] sums = new double[k];
int[] counts = new int[k];
for (int i = 0; i < data.Length; ++i)
{
int c = clustering[i]; // Cluster ID
sums[c] += data[i];
counts[c]++;
}
for (int c = 0; c < sums.Length; ++c)
{
if (counts[c] == 0)
return false; // fail
else
sums[c] = sums[c] / counts[c];
}
sums.CopyTo(this.means, 0);
return true; // Success
}
初始化聚類分析
聚類分析初始化過程有些復雜。假定數據包含圖 1 所示的 11 個已排 序的值,且已將 k(聚類數)設置為 3。初始化之後,目標是通過數組成員聚類分析使單元 格 0 到 2 中擁有三個 0 值,單元格 3 到 5 中擁有三個 1 值,單元格 6 到 10 中擁有其 余五個 2 值。換句話說,應按頻率均勻分配聚類分析。
第一步是生成邊值 {3, 6, 9},這會隱式定義 0-2、3-5 和 6-更大數字的區間。可通過 Helper 方法 GetInitialIndexes 來做到這一點,這只是將數據點數除以聚類數:
private int[] GetInitialIndexes()
{
int interval = data.Length / k;
int[] result = new int[k];
for (int i = 0; i < k; ++i)
result[i] = interval * (i + 1);
return result;
}
第二步是使用邊值定義計算給定數據索引值的聚類值的 Helper 方法:
private int InitialCluster(int di, int[] initialIndexes)
{
for (int i = 0; i < initialIndexes.Length; ++i)
if (di < initialIndexes[i])
return i;
return initialIndexes.Length - 1; // Last cluster
}
第三步是將所有數據索引分配給聚類:
private void InitializeClustering()
{
int[] initialIndexes = GetInitialIndexes();
for (int di = 0; di < data.Length; ++di)
{
int c = InitialCluster(di, initialIndexes);
clustering[di] = c;
}
}
實際上,初始化過程是本文中之前所述的相等頻率方法。
Discretize 方法
對數據進行聚類分析後,means 數組中的最終值可用於將從零開始的分類值分配給數值。 Discretize 方法為:
public int Discretize(double x)
{
double[] distances = new double[k];
for (int c = 0; c < k; ++c)
distances[c] = Distance(x, data[means[c]]);
return MinIndex(distances);
}
此方法計算從輸入值 x 到每個 k 平均值的距離,然後返回最接近平均值的索引,該平均 值既是聚類 ID 又是分類值。例如,如果最終平均值為 61.00、67.50 和 75.25,且 x 為 70.00,則 x 與這些平均值的距離為:mean[0] = sqrt((70.00 - 61.00)^2) = sqrt(81.00) = 9.00。同樣地,mean[1] = sqrt((70.00 - 67.50)^2) = 2.50,且 mean[2] = sqrt ((70.00 - 75.25)^2) = 5.25。最小距離為 2.50(位於索引 [1] 處),因此會將 70.00 分 配給分類值 1。
總結
本文中顯示的代碼可按原樣使用,以便您能夠實現針對機器學習的高質量的從數值數據到 分類數據的轉換。您可能需要在類庫中封裝 Discretizer 類而不是將代碼直接嵌入到應用程 序中。
您可能需要自定義的主要功能是對類別數 k 的確定。一種可能性是設置一個阈值。如果 低於該阈值,則每個數據點將生成一個類別值。例如,假定您正在處理人員的年齡數據。假 定這些年齡的范圍介於 1 和 120 之間。由於只有 120 個可能不同的值,因此您只需將 k 設置為 120,而不是將 k 計算為 120 的平方根(這將為您提供 10 個類別)。
下載代碼示例