最近一周比較忙,主要的工作內容是在做一個叫“鍵盤精靈”的東西,簡單來講就是將很多數據放到內存中,對這些數據進行快速檢索,然後找出根據輸入條件最匹配的10條記錄並予以展示。具體和下面兩款炒股軟件的相關功能類似:
數據以文本形式存在文件中,且數據量較大,有近20萬條,每一條記錄有幾個字段,以分隔符分割。當時使用的是6萬條記錄的測試數據,文本文件將近10M,這個模塊加載到內存並建立緩存之後,大概會占用將近70-80M的內存。自我接手以後,主要的任務就是降低內存消耗和提高匹配效率。
一、避免創建不必要的對象
拿到代碼後,第一步就是看設計文檔,然後斷點一步一步的看代碼,大概明白了邏輯之後,發現思路有一些問題。之前的代碼處理流程思路大概是下面這樣的:
將文件讀取到內存,實例化
根據條件對文件進行檢索,並存儲到結果集1中
對結果集1中的結果進行匹配度計算,並存儲到結果集中2
按對結果集2進行匹配度排序,取最匹配的10條記錄,然後返回
這個過程中規中矩。但是其中有很多問題,最大的問題是,臨時變量存儲了太多的中間處理結果,而這些對象在一次查詢完成後又馬上丟棄,大量的臨時對象帶來了很大的GC壓力。舉例來說,當用戶在輸入框中輸入1的時候,假設使用Contains來匹配,那麼從6萬條記錄中找出包含1的記錄可能有4萬多條,然後需要把這4萬多條記錄存儲在臨時變量中進行處理,進一步計算這4萬條記錄的匹配度,然後存儲到一個類似KeyValuePair的集合中,key為匹配度,然後對這個集合按Key進行排序,然後取前10條最優記錄。可以看到,中間創建了大量的臨時變量,使得內存劇增,大量臨時對象創建之後馬上會被回收,GC壓力山大。
而在設計文檔中,只要求返回最最匹配的10條記錄,之前的解決方案中似乎並沒有注意到這一點。所以接手後,第一步就是對上面的處理過程進行精簡。精簡後如下:
將文件讀取到內存,實例化
根據條件對文件進行檢索,如果存在,則:
計算匹配度。
以匹配度為Key,存儲到只有11個容量的SortList中。
如果SortList集合添加記錄後大於10個,則移除最後面一個元素,始終保持著前10個最小(匹配度最優)的記錄。
遍歷完成之後,返回這個集合對象
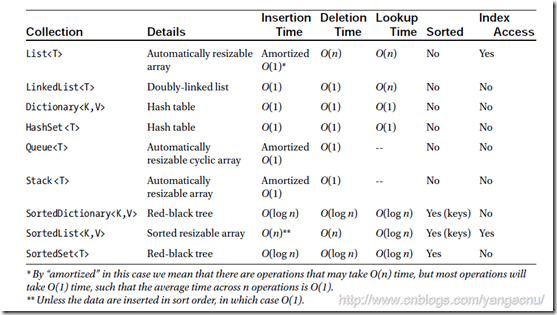
經過這一修改,減少了大量臨時數據對內存的占用,整個過程中,我只是使用一個容量為11的SortList結構存儲中間的過程,每一次插入一個元素,SortList幫我們排好序,然後移除最不匹配的那一個,也就是最後一個元素(從小到大排序,越匹配,值越小)。這裡面的消耗主要是SortList的插入,內部排序和移除記錄。 說到這裡在選擇SortList還是SortDictionary的問題上糾結了一下,於是又找了些資料,SortDictionary在內部使用紅黑樹實現,SortList采用有序數組實現, 在內部排序都為O(logn)的前提下,SortDictionary的O(logn)插入及刪除元素的時間復雜度優於SortList,但是SortDictionary會比SortList占用更多內存。基本來說這是一個查詢速度和內存分配之間的平衡,由於這裡只需要存儲11個對象,所以兩者相差不大。其實即使沒有這種結構,自己也可以實現的,無非就是一個集合,每次添加一個,排好序,然後將最大的那個移除。.NET使用起來方便是因為有很多這些強大的內置數據結構。
經過上面這個小小的修改,內存占用一下子降低了1倍,從原來的70-80M,降低到了30-40M,其實這就是降低內存開銷的一個最基本的原則,那就是避免創建不必要的對象。
二、優化數據類型及算法
越到後面內存的降低越來越困難。仔細看了代碼之後,除了上面之外,代碼中也有一些其他問題,比如,一開始就將大量的對象實例化到內存中,然後一直保存。每一條記錄中的信息比較多,但真正有用的用於搜索匹配的只有下面四個字段,但是整體的實例化會將其他沒有用的字段也一並序列化進去了。導致很多內存被無用的字段占用。
股票代碼 股票中文名 中文拼音 市場類型 ……
600000 浦發銀行 PFYH 上證A股 ……
所以第一步就是在內存中只存放需要檢索的上面四個關鍵字段,每一條記錄剛開始是使用string[]數據,而不是使用類或者其它結構來保存,也嘗試使用結構提來保存,但是由於四個字段,數據量大,中間還要作為參數傳遞,所以比使用類還大,這裡只是簡單的使用了數組。
除了上面這些之外,為了提高搜索效率,對數據按照0-9,a-z開頭對數據做了切分分塊緩存,這樣當用戶輸入0時,直接從以0為key的塊中讀取數據,這樣速度是加快了,但是大量的緩存也增加了對內存的消耗。緩存的數據基本上和加載到內存中原始的數據一樣大了。並且在搜索的過程中,也是采用的完全搜索,對於17萬條數據的四個字段,每一次查詢要進行170000*4次遍歷比較,才能找出最匹配的10條數據來。
為此,引入了不完全搜索,就是事先對各類型證券,如 股票,基金,債券分類,對每一類按證券代碼進行排序。當用戶設置了搜索的優先級時,依次在每一類中查找,如果找到滿足條件的10條記錄,則立即返回,因為數據已經事先按照證券類型和代碼排好序了,所以後面找到的肯定沒有之前找到的匹配度高,這一改進直接提高了搜索查詢的效率。對有序的數據進行查找效率一般會比無序的數據查找效率高。我們常見的一些查找算法,比如說,二分查找法,前提也是待查找的集合有序排列。
三、采用非托管代碼或者模塊編寫數據處理邏輯
上面的兩部操作雖然減少了將近50-60%的內存占用,但是仍然達不到領導的要求,於是又嘗試並比較了各種 使用不同的數據結構將數據載入到內存中的內存占用大小,包括直接將文件按類型讀成字符串、數組、結構及類,內存占用最小的直接將文件讀成字符串,10M的數據文件讀進內存也會占用20-30M的空間,還不談對其進行處理過程中產生的一些臨時變量對內存的占用。使用dotTrace及CLR Profile等工具檢查之後,發現內存的占用也是這些原始數據。然後以” How to reduce the memory usage of .NET applications” 到網上搜了一下減少.NET內存占用的一些方法,在StackOverflow上看到了這一回答:
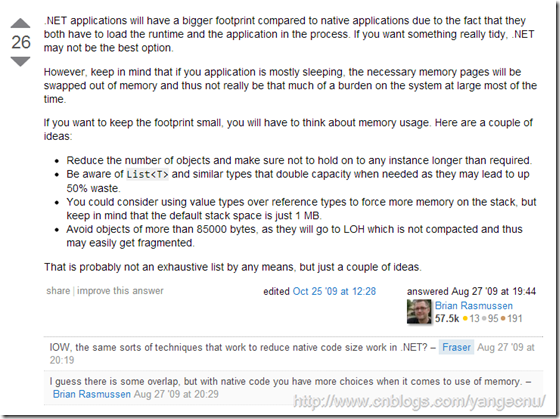
該同學指出.NET應用程序和其他使用本地代碼編寫的程序相比會有較大的內存占用,如果對內存開銷比較在意,.NET可能不是最好的選擇。.NET應用程序的內存一定程度上受垃圾回收的影響。並指出,一些數據結構如List,系統會分配多余的空間。可以使用值類型而不是引用類型,不要創建大對象,以免產生內存碎片等等降低內存占用的建議。
這些都考慮過之後,內存還是達不到要求,所以開始尋找調用非托管代碼的方式來自己更靈活的控制內存的分配與銷毀。但是整個程序都是采用.NET編寫的,全部切換成C或者C++不現實,所以只有兩種方案,一是使用unsafe 代碼,二是將數據加載和檢索模塊采用C或者C++編寫,在.NET中采用P/Invoke技術調用。
剛開始想采用unsafe代碼,對數據的加載及檢索直接在放在unsafe 代碼中。後來覺得代碼有些亂,不同風格的代碼混雜在一起不太好,而且數據加載和檢索的邏輯也比較復雜。所以就直接采用第二種方案,使用C++編寫數據加載和檢索邏輯。然後在.NET裡面調用。
在開始之前,也做了一些評估,比如將同樣的10M的數據加載到內存中,都采用字符串的方式存儲,.NET中會占用20-30M的內存,而在C++中只有9-10M的樣子,而且變動很小。這正是需要的結果。
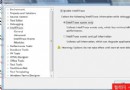
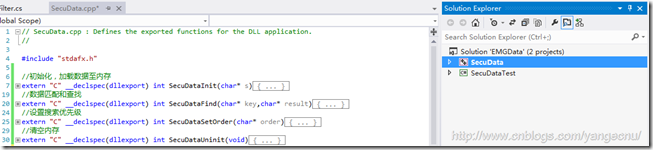
由於對C++不熟,臨時抱佛腳,翻了下C++ Primier Plus中關於字符串和STL的相關章節,並請求其他開發小組給予了一定的協助,定義了基本的接口。為了演示,我創建了兩個工程,一個是名為SecuData的C++ Win32 DLL工程,一個是測試該類庫的名為SecuDataTest的C# WinForm程序。
我在C++中定義好了4個方法,一個初始化加載數據,一個設置搜索優先級,一個查找匹配方法和一個卸載數據方法,具體的算法由於工作原因不便貼出,這裡只是舉一個簡單的例子,方法名及工程結構如下圖:
然後再在.NET中使用P/Invoke技術引入C++ DLL中定義的方法。
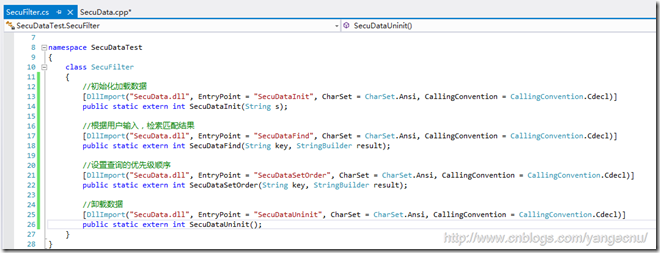
這樣就可以在.NET中調用這些方法了,需要說明的是,方法的傳入值這裡是使用String類型的,第二個StringBuilder類型的參數是方法的真正返回值,方法的整體int型返回值表明方法是否執行成功。在調用查找方法時,第二個StringBuilder參數必須初始化一個最大的查詢結果的大小,因為在C++中會往這個對象中寫入結果,不初始化或者初始化太小都會拋出異常。當然也可以直接返回結構體,這個就需要額外定義,這裡返回的都是字符串。完了自己在.NET裡面對其進行解析。
需要注意的是,調試的時候,如果需要調試C++裡面的代碼,需要指定DLL的生成目錄及啟動目標,並且將C++項目設置為啟動項目,這裡我設定生成DLL的目錄為SecuDataTest項目生成的SecuDataTest.exe文件所在的目錄,調試啟動目標設置為SecuDataTest.exe,這樣在C++項目中設置斷點,啟動.NET Winform程序,當P/Invoke觸發斷點時能夠逐步調試C++代碼。
在發布的時候,最好將默認的動態庫配置修改為靜態庫,這樣VS會把依賴的相關C++庫打包到生成的dll中,部署到客戶機器上不會出現問題。SecuData類庫項目的屬性設置如下圖:
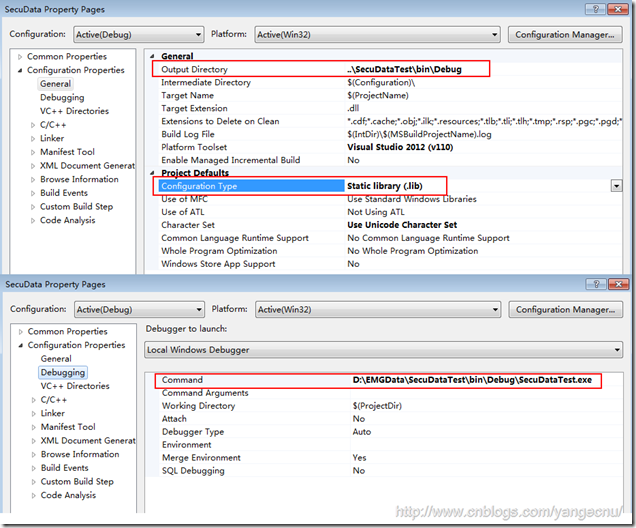
改成這種P/Invoke模式之後,10M數據載到內存中,內存占用只有10M左右,較之前采用.NET的30-40M的內存又降低了很多,而且內存波動比較小,滿足了對內存占用的要求。
采用這種“混搭”方式有一些好處,既有.NET的快速開發,又有C++的靈活的內存分配銷毀模式以及代碼安全性保護。在很多時候,可以將一些對內存占用比較敏感,大數據量的處理邏輯,放在C++中處理,利用靈活的手動內存管理模式降低這部分的內存占用;將核心的數據結構及算法使用C++編寫,可以提高代碼的安全性,提高程序的反編譯難度。
四、結語
.NET應用程序由於需要加載CLR及一些通用類庫,並且具有垃圾收集機制,較其他本地語言如C,C++具有較大的footprint,使用.NET創建一個簡單的Winform可能就會占用近10M的內存,所以隨著開發的進行,內存占用會比較大。當然這些在很多時候是由於開發者自身對.NET底層機制不熟悉,比如在有些地方可以使用值類型而使用引用類型;創建了大量的臨時的周期比較短的對象;使用了過多的靜態變量及成員導致內存被長久占用而得不到回收;以及.NET內部的一些機制,比如集合對象會在內部預先分配多余的空間等等。很多時候因為有.NET的GC機制,使得我們不必去關注對象的銷毀而很”大方”的去創建新對象,去使用一些重型的內置對象,從而導致內存占用過大。解決好這些問題,其實可以降低.NET應用程序的相當大一部分的不必要的內存占用。
除了了解.NET框架的一些內部機制之外,良好的思路,高效數據結構和算法也可以使得問題變得簡單而減少內存的開銷。
最後對於對內存要求比較敏感,可以利用C/C++的手動的靈活的內存管理語言來編寫相應模塊,在.NET中采用P/Invoke技術進行調用來減少一些內存。
以上是我對降低.NET應用程序內存占用的一點兒實踐和總結,希望對您有所幫助。
作者: yangecnu
出處:http://www.cnblogs.com/yangecnu/