前面大概的介紹了一下lighttpd的狀態機。在這篇中,將通過狀態機,看看lighttpd到底是怎樣處理 連接請求的。
在本篇中,我們只介紹lighttpd的最基本功能──處理靜態頁面。lighttpd處理靜態頁面要使用 mod_staticfile.c插件。從名字中也可以看出是用來處理靜態文件的。另外這個插件在配置文件中沒有配 置,是lighttpd默認會加載的。
首先還是把狀態機放這,以便查閱。
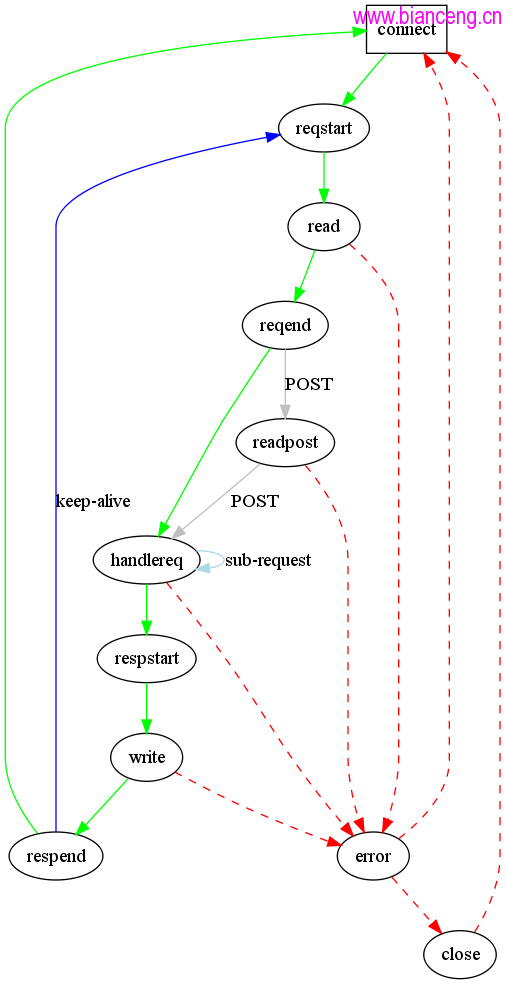
首先,連接建立以後,連接進入CON_STATE_REQUEST_START狀態。在這個狀態中,服務器僅僅是記錄了 做一些標記,如記錄連接開始的時間,讀操作發呆的時間等。接著,連接就進入了CON_STATE_READ狀態。
在READ狀態中,服務器從連接讀取HTTP頭並存放在con->requeset.request。在讀取過程中,可能 一次調用沒有讀取全部的數據,連接的狀態繼續停留在READ,然後,繼續等待剩下的數據可讀。由於這個 連接同時也在作業隊列中,在對作業隊列進行處理的時候,依然會調用 connecion_handle_read_state函 數進行處理,不過,函數中通過con->is_readable來判斷是否有數據可讀,如果沒有,則只是處理一 下以前已經讀取的數據。數據讀取完畢之後,連接進入CON_STATE_REQUEST_END狀態。
在REQUEST_END狀態中,主要就是調用了http_request_parse函數。從函數名字就可以看出來是在解析 request請求。request的請求格式如下:
HTTP Request Message的格式:
---------------------------------------
| methods |sp| URL |sp| Version |\r|\n| -----> Request line (Request)
---------------------------------------
| header field name: |sp| value |\r|\n| -]
--------------------------------------- ]
// ... |---> Header lines (Option)
--------------------------------------- ]
| header field name: |sp| value |\r|\n| -]
---------------------------------------
|\r|\n| -----> blank
---------------------------------------
| |
| Data... | -----> Entity body
| |
---------------------------------------
不熟悉的可以看看RFC2616。
函數首先解析Request line,解析出來的結果分貝存放在:con->request.http_method, con- >request.http_version和con->request.uri
前兩個變量都是枚舉類型,後一個是個buffer。程序的第一個for循環解析完request line後,進入第 二個for循環,這個循環很長,但做的工作很簡單。就是分析header lines。在找到一個header field name以後,就和所有已經定義的field name比較,看看是哪個。確定之後,就將field name和value保存 到con->request.headers中。request.headers是一個array類型變量,存放的是 data_string類型數 據。其中,data_string的key是filed name,value就是field的成員。解析完之後做一些檢查工作。最後 ,判斷此次連接是否有POST數據,如果有則讀取POST數據,否則進入 HANDLE_REQUEST。
在閱讀這個函數的時候,讀者可參考RFC2616中的規定。
在這裡,我們假設有POST數據要讀。這時候,連接進入READ_POST狀態。其實,READ_POST狀態的處理 和READ狀態一樣,在 connection_state_mechine函數中,可以看到這兩個switch分支一樣。主要區別是 在 connection_handle_read_state函數中。connection_handle_read_state函數的前半部分讀取數據, 大家都一樣,在後面處理數據的時候是分開的。對於讀取POST數據,由於數據可能很大,這時候可能會用 到臨時文件來存儲。在程序中,作者對於小於64k的數據,直接存儲在buffer中,如果大於64k則存儲在臨 時文件中。在向臨時文件寫數據的時候,每個臨時文件只寫1M的數據。數據大於1M就在打開一個臨時文件 。POST數據保存在con->requeset_content_queue,這是一個chunkqueue類型的成員變量,它是 chunk 結構體的鏈表,定義如下:
1 typedef struct
2 {
3
4 chunk *first;
5 chunk *last;
6 /**
7 * 這個unused的chunk是一個棧的形式。
8 * 這個指針指向棧頂,而chunk中的next指針則將棧連 接起來。
9 */
10 chunk *unused;
11 size_t unused_chunks;
12 array *tempdirs;
13 off_t bytes_in, bytes_out;
14 } chunkqueue;
unused成員也是一個鏈表,不過這個鏈表是棧的形式,unused指向棧頂。這個棧用來存儲不用的chunk 結構體,如果需要chunk,則先從這個棧中查找有無空閒的。也就是看棧頂是否是NULL。如果chunk不使用 了,可以加到棧頂。這樣可以減少內存分配的時間,提高程序的效率。這時一個很通用的小技巧。 unused_chunks標記棧中有多少數據。
first和last分別指向鏈表的開頭和結尾。
chunk的定義如下:
1 typedef struct chunk
2 {
3
4 enum { UNUSED_CHUNK, MEM_CHUNK, FILE_CHUNK } type;
5 /* 內存中的存儲塊或預讀緩存 */
6 buffer *mem;
7 /* either the storage of the mem-chunk or the read-ahead buffer */
8 struct
9 {
10 /*
11 * filechunk 文件塊
12 */
13
14 buffer *name;/* name of the file */
15 off_t start;/* starting offset in the file */
16 off_t length;/* octets to send from the starting offset */
17
18 int fd;
19 struct
20 {
21 char *start;/* the start pointer of the mmap'ed area */
22 size_t length;/* size of the mmap'ed area */
23 off_t offset; /* start is <n> octet away from the start of the file */
24 } mmap;
25 int is_temp;/* file is temporary and will be
26 deleted if on cleanup */
27
28 } file;
29 off_t offset;/* octets sent from this chunk the size of the
30 * chunk is either -mem-chunk: mem->used - 1 file-chunk: file.length */
31
32 struct chunk *next;
33
34 } chunk;
從名字可以看出,chunk用來表述一塊存儲空間。這個存儲空間可能在內存中,也可能在文件中。mem 成員指向內存中的存儲空間。而file結構體則表示在文件中的存儲空間。tpye成員標記這個塊是內存的還 是文件的。對於在內存中的存儲空間,實際就是一個buffer。這個沒什麼說的。對於文件中的存儲空間, 程序首先會使用mmap函數將文件映射到內存中,mmap結構體的start成員保存映射到內存中的地址。然後 ,對於文件的操作就可以像使用內存一樣。
關於這兩個結構體的操作函數讀者課自行查看。
當POST數據讀取完畢之後,程序進入CON_STATE_REQUEST_END狀態。在這個狀態中,主要調用了是 http_response_prepare函數,然後根據這個函數的返回值進行相應的處理。http_response_prepare函數 定義在 response.c文件中。粗略的浏覽一遍這個函數,你會發現函數中調用了很多 plugins_call_handle_xxxx函數。其實插件系統的接口函數主要是在這個函數中調用,這個函數也是服務 器和插件系統交互的地方。函數定義如下:
1 handler_t http_response_prepare(server * srv, connection * con)
2 {
3 handler_t r;
4 if (con->mode == DIRECT && con->physical.path->used == 0)
5 {
6 char *qstr;
7 /**
8 * Name according to RFC 2396*
9 * (scheme)://(authority)(path)?(query)#fragment
10 * fragment: 用於頁面內部的跳轉。通常不屬於uri的一部分。
11 * 服務器沒有你要對其進行解析,後面的解析中,直接丟棄fragment。
12 */
13 /* 對HTTP頭中的uri進行解析,分析出各個部分的內容。 */
14 switch (r = plugins_call_handle_uri_raw(srv, con))
15 {
16 case HANDLER_GO_ON:
17 break;
18 case HANDLER_FINISHED:
19 case HANDLER_COMEBACK:
20 case HANDLER_WAIT_FOR_EVENT:
21 case HANDLER_ERROR:
22 return r;
23 default:
24 log_error_write(srv, __FILE__, __LINE__, "sd", "handle_uri_raw: unknown return value", r);
25 break;
26 }
27 /*do we have to downgrade to 1.0 ? */
28 if (!con->conf.allow_http11)
29 {
30 con->request.http_version = HTTP_VERSION_1_0;
31 }
32 switch (r = plugins_call_handle_uri_clean(srv, con))
33 {
34 case HANDLER_GO_ON:
35 break;
36 case HANDLER_FINISHED:
37 case HANDLER_COMEBACK:
38 case HANDLER_WAIT_FOR_EVENT:
39 case HANDLER_ERROR:
40 return r;
41 default:
42 log_error_write(srv, __FILE__, __LINE__, "");
43 break;
44 }
45 if (con->request.http_method == HTTP_METHOD_OPTIONS && con ->uri.path->ptr[0] == '*'
46 && con->uri.path_raw->ptr[1] == '\0')
47 {
48 /*將key=val加到response的head中。*/
49 response_header_insert(srv, con, CONST_STR_LEN ("Allow"),CONST_STR_LEN("OPTIONS, GET, HEAD, POST"));
50 con->http_status = 200;
51 con->file_finished = 1;
52 return HANDLER_FINISHED;
53 }
54 /**
55 *將請求地址轉換成服務器的物理地址,也就是文件路徑。
56 */
57 buffer_copy_string_buffer(con->physical.doc_root, con- >conf.document_root);
58 buffer_copy_string_buffer(con->physical.rel_path, con- >uri.path);
59 switch (r = plugins_call_handle_docroot(srv, con))
60 {
61 case HANDLER_GO_ON:
62 break;
63 case HANDLER_FINISHED:
64 case HANDLER_COMEBACK:
65 case HANDLER_WAIT_FOR_EVENT:
66 case HANDLER_ERROR:
67 return r;
68 default:
69 log_error_write(srv, __FILE__, __LINE__, "");
70 break;
71 }
72 /**
73 * create physical filename
74 * -> physical.path = docroot + rel_path
75 */
76 buffer_copy_string_buffer(con->physical.path, con- >physical.doc_root);
77 BUFFER_APPEND_SLASH(con->physical.path);
78 buffer_copy_string_buffer(con->physical.basedir, con- >physical.path);
79 if (con->physical.rel_path->used && con- >physical.rel_path->ptr[0] == '/')
80 {
81 buffer_append_string_len(con->physical.path,
82 con->physical.rel_path->ptr + 1,
83 con->physical.rel_path->used - 2);
84 }
85 else
86 {
87 buffer_append_string_buffer(con->physical.path, con- >physical.rel_path);
88 }
89 switch (r = plugins_call_handle_physical(srv, con))
90 {
91 case HANDLER_GO_ON:
92 break;
93 case HANDLER_FINISHED:
94 case HANDLER_COMEBACK:
95 case HANDLER_WAIT_FOR_EVENT:
96 case HANDLER_ERROR:
97 return r;
98 default:
99 log_error_write(srv, __FILE__, __LINE__, "");
100 break;
101 }
102 /*
103 * Noone catched away the file from normal path of execution yet (like mod_access)
104 * Go on and check of the file exists at all
105 */
106 if (con->mode == DIRECT)
107 {
108 char *slash = NULL;
109 char *pathinfo = NULL;
110 int found = 0;
111 stat_cache_entry *sce = NULL;
112 if (HANDLER_ERROR != stat_cache_get_entry(srv, con, con- >physical.path, &sce))
113 {
114 /*file exists */
115 }
116 else
117 {
118 /*not found, perhaps PATHINFO*/
119 /*we have a PATHINFO */
120
121 }
122 switch (r = plugins_call_handle_subrequest_start(srv, con))
123 {
124 case HANDLER_GO_ON:
125 /*request was not handled */
126 break;
127 case HANDLER_FINISHED:
128 default:
129 /* something strange happend */
130 return r;
131 }
132 /*if we are still here, no one wanted the file, status 403 is ok I think*/
133 if (con->mode == DIRECT && con->http_status == 0)
134 {
135 switch (con->request.http_method)
136 {
137 case HTTP_METHOD_OPTIONS:
138 con->http_status = 200;
139 break;
140 default:
141 con->http_status = 403;
142 }
143 return HANDLER_FINISHED;
144 }
145 }
146 switch (r = plugins_call_handle_subrequest(srv, con))
147 {
148 case HANDLER_GO_ON:
149 /*request was not handled, looks like we are done */
150 return HANDLER_FINISHED;
151 case HANDLER_FINISHED:
152 /*request is finished */
153 default:
154 /*something strange happend */
155 return r;
156 }
157 /*can't happen */
158 return HANDLER_COMEBACK;
159 }
上面的代碼刪除了一些代碼,重點突出插件的調用。完整代碼讀者可自行查閱。下面我們開始分析。
首先我們先來看看HTTP協議,前面提到的HTTP Request Messag格式可以看出,在整個HTTP requset head中,只有url和methods可以用來確定請求所對應的插件。比如,對於cgi請求,url中的文件的擴展名 肯定是配置文件中定義的,不會是.html。在http_response_prepare函數中,通過對url的解析,逐步的 調用插件來處理。對url解析的結果存放在 con->uri中。uri的定義如下:
1 typedef struct
2 {
3 buffer *scheme; //http , https and so on
4 buffer *authority; //user:password
5 buffer *path; //www.xxx.com/xxx/xxxx.html
6 buffer *path_raw; //www.xxx.com
7 buffer *query; //key1=data1&key2=data2
8 } request_uri;
uri的定義為:(scheme)://(authority)(path)?(query)#fragment。上面的結構體和這個定義對應。 舉個例子:
http://user:[email protected]/pages/index.html?key1=data1&key2=data2#frag
解析之後:
scheme = http
authority = user:passwd
path = www.google.com/pages/index.html
path_raw = 未進行解碼的path
query = key1=data1&key2=date2
對於path_raw要說明一下。在浏覽器向服務器發送url請求的時候,會對其中的保留字符和不安全字符 進行編碼(具體參見RFC2396),最長見的就是對漢字。編碼的形式是% HEX HEX,一個%加兩個十六進制 的數字。服務器在接受到請求之後,要對這些編碼過的字符進行解碼。path_raw中保存的就是還沒有解碼 的 url,path保存的是已經解碼過的url。
前面的程序已經解析了HTTP頭,HTTP頭中的request line中的uri被存儲在con->request.uri中。 在函數的一開始,對這個uri地址進行解析。對於uri中的query和 fragment部分,服務器不需要進行處理 ,因此將這些部分提取後存儲到con -> uri中,對fragment的處理時直接拋棄,因為fragment是浏覽 器使用的。當解析出url中的path之後,服務器調用插件的 plugins_call_handle_uri_raw函數,在這個 函數中,插件根據分析出的為解碼的url path進行處理。如果沒有插件進行處理,服務器接著調用哪個插 件的plugins_call_handle_uri_clean函數,這個函數自然就是根據解碼過的url path進行處理。這兩個 函數最典型的應用就是proxy服務器。proxy服務器根據解析出來的url地址直接將請求轉發,不需要對請 求進行處理。
當請求仍然沒有被處理時,說明這個請求必須在要被處理。首先服務器調用插件的 plugins_call_handle_docroot函數對處理請求時的根目錄進行設置。對於不同種類的資源,可以設置不 同的根目錄,提供一個虛擬服務器。設置根目錄也可以簡化請求的url地址。
接著,服務器根據根目錄和請求的url地址,拼接處資源在本機上對應的物理地址。比如,doc root = /abc/root, url path = /doc/index.html,得到的物理地址就是/abc/root/doc/index.html。然後服務 器調用插件的 plugins_call_handle_physical函數。這個函數根據得到的物理地址進行相應的處理。
接著,服務器調用插件的plugins_call_handle_subrequest_start函數和 plugins_call_handle_subrequest函數進行最後的處理。
下面總結一下插件接口的作用:
1、plugins_call_handle_uri_raw
在得到http頭中,request line的url地址直接調用,此時的url地址沒有解碼。url地址中不包含 query。
2、plugins_call_handle_uri_clean
對url地址進行解碼之後調用。
以上兩個函數典型的應用時proxy服務器。直接將請求轉發。
3、plugins_call_handle_docroot
設置處理請求時的根目錄。
4、plugins_call_handle_physical
得到請求資源在服務器上的物理地址,根據這個物理地址做相應的處理。
5、plugins_call_handle_subrequest_start
子請求處理開始。
6、plugins_call_handle_subrequest
處理子請求。
最後,連接進入CON_STATE_RESPONSE_START狀態。進入這個狀態之後,服務器根據處理得到的記過准 備給客戶端的response。包括准備response頭和寫數據。這在後面的文章中繼續討論。