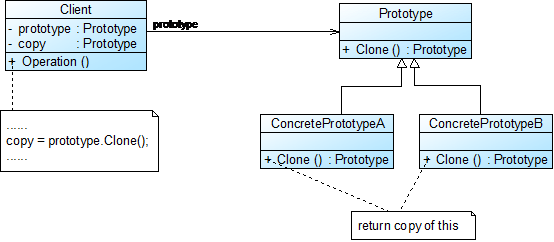
向上擴容和平面擴容
Optimize the application before scaling up or scaling out.
在你進行向上擴容和平面擴容前優化你的應用。
譯注:你可以減少無效的鎖,使用參數化查詢,增加合適的索引等操作來提高磁盤,內存和CPU的利用 率。
Address historical and reporting data.
處理歷史和用於報表的數據。
譯注:一個運行時間很長的系統肯定有很多歷史數據,在現網庫裡一直保存這些數據,肯定會給線上 的應用帶來負面影響,查詢一個小庫和查詢一個大庫的開銷差別很大,所以一般應該把歷史數據的一部分 分到不同的區裡,歷史數據是只讀的,甚至可以放到另外的只讀數據庫裡。用於報表的數據也是,大多都 是歷史數據,可以建立單獨的數據倉庫去存放他們,不要和現網庫放在一起。
Scale up for most applications.
對大多數應用進行向上擴容。
譯注:如果你在處理了歷史數據和報表數據後還有更好的硬件,那就先添加這些新的硬件,比如更快 的CPU和硬盤,更大的內存等,但添加了新的硬件後記著修改你的SQLSERVER的配置以適應這些新硬件,比 如要打開/3G開關以使用更多的內存。
Scale out when scaling up does not suffice or is cost-prohibitive.
在你向上擴容仍不滿足或者向上擴容成本太高的時候使用橫向擴容。
譯注:橫向擴容的時候可能需要對一些表進行水平分區,使這些分區到不同的機器上,而這種辦法可 能需要在多台機器間用SQLSERVER的復制功能復制數據。而且使用大量的PC server做成的聯合服務器在在 災後恢復和容災上也更加復雜,你需要權衡引入這些復雜性和花錢買硬件哪個更值得。
Schema
Devote the appropriate resources to schema design.
給予適當的資源用來進行schema設計。
譯注:在進行架構設計前一定要花費足夠的時間和投入足夠的資源來進行業務邏輯收集,設計及測試 數據模型,如果上線之後再修改數據模型代價將非常高。
Separate online analytical processing (OLAP) and online transaction processing (OLTP) workloads.
分割OLAP和OLTP負載。
譯注:OLAP的特點是經常執行一些長時間的查詢,OLTP的特點是都是小而多的事務,一般在1秒中就得 返回,長時間運行的查詢分析,報表查詢和即席查詢會阻礙插入和其它OLTP的事務。如果需要同時支持兩 種類型的工作,考慮創建一個報表服務器來支持OLAP和報表,可以使用SSAS來支持這些工作。
Normalize first, denormalize later for performance.
先遵守范式設計數據庫,然後再不遵守范式來優化性能。
譯注:遵循范式設計數據庫可以讓數據庫減少冗余,但寫出來的查詢語句卻很復雜,帶有很多join等 ,而且會降低性能,有時候為了防止一些常用的查詢跨表查詢,會在多個表裡存放相同的數據,以提高性 能,但這違反了范式。
Define all primary keys and foreign key relationships.
確定所有的主鍵和外鍵關系。
譯注:選擇合適的主鍵和外鍵關系會很大程度上影響查詢計劃的生成,從而影響性能。另外可考慮使 用聲明性引用完整性 (DRI) ,設置好主外鍵和DRI的情況下,更新主表會自動修改子表,級聯更新和級聯 刪除等,而且性能比觸發器要好。
Define all unique constraints and check constraints.
確定所有的唯一索引和約束。
譯注:唯一索引和檢查約束為查詢計劃提供了更多的信息,比如你做了一個id列不等於0的約束,如果 你一個查詢語句查詢id=0的數據,就不用掃描任何數據表,只檢查約束就可以了。
Choose the most appropriate data type.
選擇最適合的數據類型。
譯注:盡量選用比較窄的類型,能用smallint不用int,選擇合適的類型,避免類型轉換,需要類型轉 換的查詢語句有可能不能有效利用索引;避免外鍵列允許為空[不確定];能用varchar的地方不要用Text 字段,Text字段性能不行;盡量少使用sql_variant,雖然靈活,但使用它會帶來更多的類型轉換而降低 性能;因為win2000和.net裡的字符串都是unicode的,所以盡量使用nchar和nvarchar,雖然它比較占空 間,但像存儲電話號碼和郵件等用varchar和char就行了[該條可能有爭議,我不確認]。
Use indexed views for denormalization.
為不遵守范式的表使用索引視圖。
譯注:當你需要join幾個不常變化的表來查詢,像查找表等,可以為他們建立一個視圖索引,視圖索 引像表一樣是物理存在的,能提高性能。
Partition tables vertically and horizontally.
垂直或者水平分割表。
譯注:可以把表垂直分割,把不常訪問的列劃分到別的表裡,以便一個頁裡可以保存更多的行;水平分 割稍微復雜一點,但會帶來更大的靈活性,常見的做法是利用時間字段把歷史數據和存檔數據進行水平分 割,然後使用檢查約束和分區視圖把他們聯合起來;數據依賴路由(Data-dependent routing )是一個 強大的系統,它可以使用表格來保存分區信息,查詢請求會自動路由到相應的分區,從而避免了使用分區 視圖[沒試過這個東西];如果使用分區視圖要確保查詢計劃只訪問相關的表,這個要查看利用分區視圖的 執行計劃的詳細圖表輸出。
查詢
Know the performance and scalability characteristics of queries.
明確影響性能和可擴展性的查詢。
譯注:你得衡量和理解最常用的查詢,這些查詢對性能和可伸縮性影響是最大的。這需要DBA和開發人 員的交互來完成,DBA應該經常監控常用的耗費資源的查詢來告訴架構師和開發人員,開發人員去編寫適 當的索引,或者剛開始的時候開發人員編寫好查詢和索引,提交給DBA,由DBA去優化查詢及去除多余的索 引。
Write correctly formed queries.
編寫正確的form子句。
譯注:不必要的表不要join進來;盡量避免使用DISTINCT從句。
Return only the rows and columns needed.
僅僅返回你需要的行和列。
譯注:select * 不僅會加大網絡流量,而且更容易引起表掃描;使用where語句來限制你返回的行, 對大結果集進行分頁返回。
Avoid expensive operators such as NOT LIKE.
避免像NOT LIKE等耗費性能的操作。
譯注:like後面不要跟前面是通配符的單詞;像<>和not like等謂詞盡量少用,盡量用IF EXISTS和IF NOT EXISTS來取代,這樣可以使用索引。
Avoid explicit or implicit functions in WHERE clauses.
避免在where子句裡使用隱式和顯示的函數。
譯注:不要在列上使用函數,可以在標量上使用函數,如 WHERE DATEADD(day, 15, OrderDate) = '07/23/1996'改成OrderDate = DATEADD(day, -15, '07/23/1996');不要聲明一個char變量去和nchar列 去比較,相反nvarcha和varchar也一樣,在比較的時候會隱式使用Convert函數,進而可能無法使用索引 。
Use locking and isolation level hints to minimize locking.
使用鎖提示和隔離提示來最小化鎖。
譯注:要理解下四種事務隔離級別(Read uncommitted,Read committed,Repeatable read, Serializable),3種基本鎖(共享鎖、更新鎖及獨占鎖)及3種現象(幻影讀,幽靈讀和重復讀)及它們 之間的關系。合理的使用鎖提示( WITH (NOLOCK) ,WITH (READUNCOMMITTED),with(UPDLOCK),with (TABLOCK)和with(readpast)),以及在一個會話裡使用SET TRANSACTION ISOLATION LEVEL命令來改變默 認的事務隔離級別。在select語句上使用nolock鎖提示可以避免不必要的讀鎖,從而不會阻塞其它的寫語 句;在select語句上使用uptlock鎖提示可以讓鎖保持到事務結束,而不是默認上的讀鎖只保持到讀取數 據結束,上了更新鎖別的事務可以讀取數據,但不能獲取鎖[不清楚更新鎖的這個特性會引起死鎖還是會 解決死鎖]。在你批量跟新數據的時候可以使用TABLOCK鎖暗示,這比默認上的一大坨細粒度的頁鎖行鎖開 銷要小很多。
Use stored procedures or parameterized queries.
使用存儲過程和參數化查詢。
譯注:存儲過程的好處:邏輯分離,把業務邏輯和數據處理邏輯分離;調整SQL語句不需要重新部署程 序;減少網絡帶寬;提高安全性和集成性,可以給存儲過程指派訪問權限等[不確定是否可以];參數化查 詢可以防止SQL注入;防止查詢計劃重編譯。
Minimize cursor use.
最小化游標的使用。
譯注:游標的使用會反復提取行,加鎖,管理鎖,返回行等一系列操作,要用也盡量用只讀向前游標 ,少用火線游標,它們會增加對tempdb的壓力[不確定]。通常游標用來處理連續的行,如果這個表有主鍵 ,可以用一個wihe語句來取代游標的使用。
Avoid long actions in triggers.
避免在觸發器裡執行長時間的操作。
譯注:觸發器裡操作會引起新的事務,因為一般在觸發器裡寫的都是update,insert和Delete語句,如 果事務過長會影響其它的查詢,如果必須要這麼做,可以使用消息隊列來異步的做。
Use temporary tables and table variables appropriately.
適當的使用臨時表和表變量。
譯注:如果你需要經常的創建臨時表,考慮使用表變量或者真實表。表變量會在存儲過程,函數和批 結束後自動清理,如果大量的請求使用臨時表會引起臨時表和系統表的爭用。特別大的臨時表也是個問題 ,應該用物理表代替。表變量也會使用到臨時表[不確定],所以也不要使用大的表變量,表變量不能參與 查詢計劃的優化,也不能建立索引。對臨時表和表變量要進行合理的評估和測試,考慮它對tempdb的影響 。
Limit query and index hint use.
最小化查詢和索引暗示。
譯注:執行計劃引擎會根據查詢的成本來優化執行計劃,查詢的成本隨著時間會變化,所以硬編碼的 查詢和索引暗示有可能會變得不是最合理。查詢暗示有MERGE, HASH, LOOP, 和FORCE ORDER幾種,它會為 join操作直接選擇一個算法。索引提示是強制指定這個查詢使用表上的某個索引。一般來說還是讓執行計 劃引擎自己選擇最優化的執行計劃,如果有問題你再經過仔細測試和考慮再硬編碼索引和查詢提示。
Fully qualify database objects.
使用數據庫對象的完全限定名。
譯注:就是說使用Nothwind.dbo.Employee,而不用Employee,這樣會名字解析的資源消耗,避免不必 要的Schema鎖和查詢計劃重編譯。
索引
Create indexes based on use.
只創建需要的基本的索引。
譯注:不要在很少訪問的表上創建索引,索引會降低寫性能,不要在bit或者很寬的列上創建索引。
Keep clustered index keys as small as possible.
使聚集索引的鍵盡可能的小。
譯注:因為非聚集索引會使用聚集索引鍵來定位數據行,所以盡量讓聚集索引鍵小。
Consider range data for clustered indexes.
確保聚集索引表示數據的一個范圍。
譯注:當你的where語句裡經常有<,>及between等操作符時,在這些列上建立聚集索引,不一定 非在主鍵上建聚集索引才是合適的,常常應建立在時間字段上,如果這個表是個查找表的話,才會在主鍵 上建立聚集索引,因為查找表一般會直接根據主鍵去定位一個表。
Create an index on all foreign keys.
在所有的外鍵上創建一個索引。
譯注:外鍵一般用於join操作,加個索引總是有用的。
Create highly selective indexes.
創建高選取度的索引。
譯注:不要在bit列上創建索引,選取度的意思就是說該列上的值比較隨機均勻分布,如果該列只有少 數幾種可能的值,訪問索引還得再從索引找到數據頁,還不如表掃描呢。使用DBCC SHOW_STATISTICS可以 查看表的統計信息。
Create a covering index for often-used, high-impact queries.
為最常用和最重要的查詢創建覆蓋索引。
譯注:就是說讓查詢成為索引覆蓋查詢,where和select的列都保存在索引裡,可以通過查看執行計劃 來確認是否把最常用的查詢優化成了索引覆蓋查詢,這是提高性能的關鍵操作。
Use multiple narrow indexes rather than a few wide indexes.
使用多個窄的索引比使用少的比較寬的索引好。
譯注:可以為一個表創建多個索引,我們盡量在多個比較窄的列上創建索引,可以靈活使用而且性能 也好,不要在太寬的列上建索引;如果要為一個比較寬的列建立索引的話可以使用CHECKSUM函數來創建哈 希索引。
Create composite indexes with the most restrictive column first.
在最需要進行限制的列上創建聯合索引。
譯注:使用聯合索引的話,記著要讓where語句使用的列在前面,Select的列在後面,因為統計信息只 會存儲第一個列的信息,執行計劃也只會用到第一個字段。
Consider indexes on columns used in WHERE, ORDER BY, GROUP BY, and DISTINCT clauses.
確保索引在where,order by,group by和distinct子句的列上。
譯注:主要是一些進行聚合的和限制條件的列上,還有 MAX, MIN等列上。
Remove unused indexes.
移除用不到的索引。
譯注:可以用DMV或者SQL Profeler來找出來利用率低的索引,刪了它。
Use the Index Tuning Wizard.
使用索引優化向導。
譯注:這個工具可以告訴你盡量在什麼列上創建索引,它會利用統計信息來給出你建議,你可以用SQL PROFILER抓一些信息給這個工具,讓它做出更好的建議。
事務
Avoid long-running transactions.
避免過長的事務。
譯注:事務在開始後會鎖定資源以防止其他事務執行,所以要保持事務盡量短。可以在應用裡開始一 個事務,常用的做法是在開始事務前驗證數據的有效性,當然在事務裡也需要驗證數據,但這已經避免了 好多可能在事務裡回滾的機會。
Avoid transactions that require user input to commit.
避免需要用戶輸入才能提交的事務。
譯注:用戶要是不輸入就一輩子也結束不了事務了。
Access heavily used data at the end of the transaction.
把訪問最不容易使用的數據的代碼放在事務的最後。
譯注:把選擇數據的操作放在事務的開始,更新操作放在後面,可能會引起很大鎖爭用的語句放在最 後,這樣可以讓鎖的時間變的少一些。
Try to access resources in the same order.
使用相同的順序去訪問資源。
譯注:防止死鎖。
Use isolation level hints to minimize locking.
使用隔離級別提示最小化鎖。
譯注:常見的就是在Select上使用with(nolock)來取消鎖,當然得是在你業務邏輯允許的情況下。
Ensure that explicit transactions commit or roll back.
確保顯示的提交事務和回滾。
譯注:所有的事務應該有明確的錯誤處理,在錯誤的時候回滾事務,如果事務不能完成就會一直鎖定 資源。可以使用DBCC OPENTRAN命令來查看打開的事務。
存儲過程
Use Set NOCOUNT ON in stored procedures.
在存儲過程裡使用Set NOCOUNT ON命令。
譯注:如果沒有打開這個選項,存儲過程裡的每一個語句會發送DONE_IN_PROC消息,如果你不告訴調 用者某個語句影響的行數,就打開這個選項。
Do not use the sp_prefix for custom stored procedures.
不要讓自定義的存儲過程以sp_開頭。
譯注:sp_開頭的是系統的存儲過程,如果自己開發的存儲過程也用這個開頭,會增加存儲過程的查找 過程,它會先去master表找。
執行計劃
Evaluate the query execution plan.
評估查詢的執行計劃。
譯注:在查詢分析器裡寫好sql,按ctrl+l就可以看執行計劃了,具體怎麼看大家可以查下資料,如 http://technet.microsoft.com/zh-cn/magazine/2007.11.sqlquery.aspx。
Avoid table and index scans.
避免表和索引掃描。
譯注:看到查詢計劃裡的表掃描和索引掃描應該引起你的注意,看看能不能創建適當的索引而讓操作 改成index seek。不過如果表的數據很少就幾百行的話有時候index scan比index seek性能要好,io少。
Evaluate hash joins.
評估哈希join。
譯注:如果一個字段上沒有索引,在做join裡才會使用hash join,而且這個操作比較耗費CPU,如果 發現你的數據庫進程CPU比較高,可以用profler跟蹤下是否有大量的hash join。一般在並行執行查詢的 時候才會利用hash join,然後再匯集結果,這是hash join的最佳使用場景[不確定我分析的對不對])。
Evaluate bookmarks.
評估bookmarks lookup。
譯注:Bookmark就是非聚集索引葉級頁上的一個指針,指向了數據頁,可能指向聚集索引的根頁,也 可能指向實際的數據行,如果建立了覆蓋索引的話,也許就不用lookup了,只查到非聚集索引的葉級就行 了。lookup操作也不一定都是不好的,如果原有的索引選取度已經很高的話,lookup也不會太耗費性能, 創建覆蓋索引還耗費磁盤空間呢。
Evaluate sorts and filters.
評估Sort和filter。
譯注:排序和過濾都是特別耗費CPU和內存的操作,一般創建合適的索引可以減少這些操作。過濾一般 還會帶來隱式的類型轉換,所以要仔細評估。但排序和過濾也並不總是不好,但它可能表示一些隱患。
Compare actual versus estimated rows and executions.
比較實際和估計行及後續操作。
譯注:有時候查詢計劃會利用不正確的統計信息,比如實際的行已經很少了,但統計信息還是舊的, 就會引起不是最優化的執行計劃。可以使用UPDATE STATISTICS WITH FULLSCAN來強制更新統計信息。
執行計劃重編譯
Use stored procedures or parameterized queries.
使用存儲過程和參數 化查詢。
譯注:最基本的防止執行計劃重編譯的措施,執行計劃的重編譯不一定就是壞事,一些 初始化的執行計劃可能隨著實際數據的變化而不再適用,但用參數化查詢可以有效的防止不必要的執行計 劃重編譯。
Use sp_executesql for dynamic code.
為動態的代碼使用sp_executesql存儲過程。
譯注:sp_executesql可以為你的動態代碼保存執行計劃,但如果每次動態代碼都不一樣的話,執 行計劃也用不上,也就沒緩存的必要了,這個根據需要來吧。
Avoid interleaving data definition language (DDL) and data manipulation language (DML) in stored procedures, including the tempdb database DDL.
避免在存儲過程裡交錯的使用DDL和DML,包括對臨時表。
譯注:如果要 在存儲過程裡寫DDL和DML語句的話,把DDL寫在最前面,然後緊接著寫DML,最後再對新的對象進行操作。 別剛定義了個表,然後往裡插了一些數據,最後又寫給剛定義的表創建了個索引,這樣會導致大量的執行 計劃重編譯。
Avoid cursors over temporary tables.
避免在臨時表上面使用游標。
譯注 :在臨時表的數據上定義游標幾乎總會引起執行計劃重編譯。
SQL XML
Avoid OPENXML over large XML documents.
避免在特別大的XML文檔上使用OPENXML。
譯注:這好像是SQL2000的API ,打開特別大的XML會消耗SQLSERVER的緩存。如果確實要導入特別大的XML文檔的話,考慮使用 XML Bulkload,具體細節請查資料,如 http://blog.500wan.com/u/4/3240/Show.asp?/_articleid/15470.html。
Avoid large numbers of concurrent OPENXML statements over XML documents.
避免在XML文檔上進行大量的並發OPENXML操作 。
譯注:有時候可能想用SQLXML進行批量插入等,但如果該操作非常頻繁,會引起內存和CPU升高 ,應該用其它的辦法來取代,比如SQL2008的批量插入,ado.net的bulk copy等。
以上兩點都是 SQL2000下的SQL XML的注意事項,歡迎大家補充新版本SQLSERVER的XML方面的檢查點。
調優
Use SQL Profiler to identify long-running queries.
使用SQL Profiler來標識長時間運行的查 詢。
譯注:現在用DMV和Management studio的報表功能就能看到了。用SQL Profiler的話使用 TSQL_Duration模板能找到長時間運行的查詢,這些查詢會嚴重影響數據庫性能,解決了他們對數據庫性 能提升有很大的作用。
Take note of small queries called often.
注意到最常調用的小的查詢。
譯注:以前可能要抓很長時間的profiler trace,然後用fn_trace_gettable自己生成報表來找出 這些最常用的查詢,現在DMV可以很方便的告訴你,找到這些常用的查詢,然後把他們優化到最好。
Use sp_lock and sp_who2 to evaluate locking and blocking.
使用sp_lock和sp_who2來評估阻 塞和鎖定。
譯注:關於阻塞和鎖定還有好多計數器,也可以結合著來解決問題。在sp_lock的結果 裡要特別注意表鎖,如果有大量的表鎖出現的話可能是導致數據庫性能下降的原因。
Evaluate waittype and waittime in master..sysprocesses.
評估master..sysprocess表裡的waittype和 waittime數據。
譯注:可以通過sysprocesses表查看一些鎖定和阻塞的信息,以幫助排查,但過 程很復雜,提供兩個鏈接給大家http://support.microsoft.com/kb/244455/zh-cn, http://support.microsoft.com/kb/224453/zh-cn
Use DBCC OPENTRAN to locate long-running transactions.
使用DBCC OPENTRAN命令來定位長時間執行的事務。
譯注:多次運行該命令,發 現每次都有相同的事務,可能就一個長時間的事務,應該確認下這是否正常。
測試
Ensure that your transactions logs do not fill up.
確保你的事務日志不會被填滿。
譯注:測試 環境一般數據量很小,事務量也少,要考慮上生產環境後大的事務吞吐量不會讓日志填滿,這可能要設置 合適的日志增長方式及增長量及磁盤空間。
Budget your database growth.
估算你的數據增長。
譯注:根據你的系統的用戶量,活躍度,人均信息量等來估算。
Use tools to populate data.
使用工具來生成測試數據。
Use existing production data.
使用現有的生產環境數據。
譯注:如果你的系統已經上線了,比如在做第二期,你可以把生產環境的真是數據拿下來當測試 數據,這些數據下的測試應該更有真實,更說明問題,他表示了真實的用戶模型。
Use common user scenarios, with appropriate balances between reads and writes.
使用常見的用戶場景,來模擬 適當的讀和寫的平衡。
譯注:一個側重寫的數據庫系統和相對讀比較多的數據庫系統的優化方案 肯定是不一樣的。
Use testing tools to perform stress and load tests on the system.
在你 的系統裡使用測試工具來進行壓力和負載測試。
監控
Keep statistics up to date.
讓統計 信息保持最新。
譯注:最好打開數據庫的統計信息自動更新的選項,如果用profiler監控到 Missing Column Statistics事件,可能是有些列丟失了統計信息,這會造成執行計劃引擎選擇非最優化 的執行計劃,使用sp_updatestats或者 UPDATE STATISTICS來手工更新統計信息。數據庫調優不是一下就 作好了,是一個持續的過程,所以我們要經常監控數據庫的行為。
Use SQL Profiler to tune long- running queries.
使用SQL Profiler去調節長時間的查詢。
譯注:這個操作要定期做,因為隨 著時間的變化,可能會出現一些新的長時間的查詢。
Use SQL Profiler to monitor table and index scans.
使用SQL Profiler監控表和索引掃描。
譯注:同理,也得定期作,因為統計信息會隨時 間變化,從而有可能會引起執行計劃的錯誤決定。
Use Performance Monitor to monitor high resource usage.
使用性能監控器來監控高的資源利用情況。
譯注:SQL有很多計數器,打開性 能計數器可以一個一個的查看都表示什麼意思,內存,CPU,磁盤和網絡一般都列為常規的監控列表中。
Set up an operations and development feedback loop.
經常安排運維人員和開發人員的相互交 流。
譯注:這句直譯譯不出來,大概是這個意思,開發人員一般不具備生產環境的訪問權限,運 維人員應該經常把生產環境的數據庫情況反饋給開發人員,開發人員也應該告訴運維人員應該注意觀察些 什麼。
部署上的考慮
Use default server configuration settings for most applications.
為大多數的應用使用默認的服務配置。
譯注:不要輕易的修改SQLSERVER的配置 項,這樣做很可能會降低數據庫的性能和可伸縮性,下面這個鏈接列舉了一些常見的SQL配置,是SQL2000 的http://support.microsoft.com/default.aspx?scid=kb;en-us;319942。
Locate logs and the tempdb database on separate devices from the data.
把tempdb數據庫和日志放在不同的存儲設備 上。
譯注:修改數據會記錄日志,如果你用到臨時表的話會有數據寫在tempdb裡,把他們兩個和 主數據庫放在不同的磁盤上能大量的提高性能。
Provide separate devices for heavily accessed tables and indexes.
為大量訪問的表和索引提供單獨的設備。
譯注:如果你的某給表或者索 引預計會有I/O瓶頸,把他們放到不同的文件組,甚至放在不同的磁盤裡以減少瓶頸的發生。
Use the correct RAID configuration.
使用正確的磁盤陣列配置。
譯注:對數據庫服務器來說,要使 用硬件的raid,別用windows的跨區卷帶區卷等作的軟riad,那會增加CPU消耗。常用的RAID是raid 5和 raid 0+1,你選擇RAID的級別,要綜合考慮成本、性能和可用性的的要求。RAID5比RAID 0+1成本低,讀 性能比寫性能好,raid0+1成本更高一些,但提供了更好的寫性能,比如tempdb更應該用raid 0+1.關於 raid的選擇,大家看http://storage.it168.com/h/2007-06-12/200706121108656.shtml。當然有錢的話 還可以用san,如dell的cx300,cx500,cx700等。
Use multiple disk controllers.
使用多個磁盤控 制器。
譯注:讓一個磁盤控制器管理多個磁盤可能會引起瓶頸。
Pre-grow databases and logs to avoid automatic growth and fragmentation performance impact.
估算你的數據庫和日志 的增長趨勢,以避免因自動增長和隨便對性能的影響。
譯注:如果你啟用了文件自動增長,要確 定一個合理的增長選項,你可以選擇按百分比增長,還是每次增長一個固定的大小,盡量每次長的大一些 ,這樣可以盡量避免頻繁變動數據庫大小。甚至你可以用計數器監控磁盤的使用,而在業務低谷的時候去 擴盤或者收縮文件,而不是啟用自動增長和自動收縮。關於這些配置可參考: http://support.microsoft.com/kb/315512/zh-cn。
Maximize available memory.
最大化可用的內 存。
譯注:啟用AWE,打開/3G開關。監控SQLServer:Buffer Manager:Buffer cache hit ratio 計數器,應該在90左右,這個值太低說明緩存命中率太低,應該添加更大的內存。Memory:Available Bytes計數器如果顯示太少,表示可用內存太少了,需要加大內存;SQLSERVER有一個Buffer pool來管理 內存,如果SQLServer:Buffer Manager: Free pages計數器持續小於4達兩秒以上,數據庫就會變的很慢 ,你就得加大數據庫或者用profeler查看是不是有大量的hash操作或者排序操作。另外如果你的機器上運 行多個數據庫,你不要讓其中一台數據庫把物理內存全占了。
Manage index fragmentation.
管理 索引碎片。
譯注:數據庫運行時間長了,肯定會造成索引碎片,使用DBCC SHOWCONTIG命令可以查 看碎片情況,你可以刪除索引,重建索引,使用DBCC DBREINDEX 或DBCC INDEXDEFRAG 命令來去除索引碎 片,其中前兩種方法會鎖定資源,以導致用戶無法進行有效的操作,DBCC INDEXDEFRAG可以在線的重建索 引而不鎖定資源。SQL2005有聯機重建索引的功能。
Keep database administrator tasks in mind.
保持數據庫管理員的應做的思考和任務。
譯注:這句不知道咋翻譯,考慮備份對性能的 影響,統計信息更新,DBCC檢查,索引重建等。