本文討論:
語言定義
編譯器各階段
CLR 抽象堆棧
正確獲得 IL 的工具
本文使用了以下技術:
.NET Framework
編譯器黑客在計算機科學領域算得上名聲遠揚。我曾在“專業開發人員大會”上看到 Anders Hejlsberg 發表一篇演講之後走下演講台時,立即有一群人請求他在書上簽名並擺出各種姿勢要求合影留念的場面。對於那些致力於學習和了解 Lambda 表達式詳情、類型系統和匯編語言的人來說,黑客們的智力都頗具神秘色彩。現在,您也可以通過編寫自己的 Microsoft® .NET Framework 編譯器來分享某些榮耀。
針對 .NET Framework 的編譯器有數百種,用於對數十種語言編寫的代碼進行編譯。這些語言在 .NET CLR 中實現交融,代碼可以平穩地正常運行並執行交互操作,而不會出現沖突。在構建大型軟件系統時,技術精湛的開發人員可以利用這一特性,在程序中添加一些 C# 和 Python 代碼。這些開發人員確實給人留下了深刻印象,但他們無法與真正的大師(即編譯器黑客)相比,因為大師們深刻了解虛擬機、語言設計以及這些語言和編譯器的具體細節。
在本文中,我將帶您了解一個用 C# 編寫的編譯器(“Good for Nothing”編譯器,名稱很貼切)的代碼,並向您介紹構建自己的 .NET 編譯器所需的高級體系結構、原理和 .NET Framework API。首先介紹語言定義,接著探討編譯器的體系結構,然後帶您了解一下用於生成 .NET 程序集的代碼生成子系統。本文的目標是幫助您了解編譯器開發的基礎知識並深入了解各種語言如何有效地針對 CLR 進行編程。我並不是真的要開發一種語言來替代 C# 4.0 或 IronRuby,但是在本討論中仍提供了大量鮮為人知的技術隱秘,相信定能激發您對編譯器開發技術的熱情。
語言定義
軟件語言都是針對特定目的開發的。從改善信息表現形式(例如 Visual Basic®),到提高工作效率(例如 Python,旨在最有效地利用每一行代碼),再到專用化(例如 Verilog,一種供處理器制造商使用的硬件描述語言),甚至只是為了滿足作者的個人喜好(例如,Boo 的創建者對 .NET Framework 情有獨鐘,而對其他可用語言不屑一顧),目的千差萬別,不一而足。
確定目的之後,您便可以設計語言(可將這一過程視為語言藍圖)。計算機語言必須非常精確,以便編程人員准確表達所需的內容,使編譯器可以准確理解和生成所表達的確切內容的可執行代碼。必須指定語言藍圖才能在實施編譯器的過程中消除歧義。為此,可以使用元語法,這種語法用於描述語言的語法。現在存在相當多的元語法,因此,您可以根據個人喜好選擇一種。我將使用一種名為 EBNF (Extended Backus-Naur Form) 的元語法來指定“Good for Nothing”語言。
有必要提一下,EBNF 非常有名:它是圖靈獎得主兼 FORTRAN 主要開發人員 John Backus 發明的。對 EBNF 進行深層次的討論不在本文論述范圍之內,但我會對基本概念進行解釋。
圖 1 中顯示了“Good for Nothing”的語言定義。根據我的語言定義,語句 (stmt) 可以是變量聲明、分配、for 循環,從命令行讀取整數或者輸出到屏幕。語句可以指定多次,以分號分隔。表達式 (expr) 可以是字符串、整數、算術表達式或標識符。標識符 (ident) 的命名方式為:以字母字符開頭,後跟字符或數字等等。很簡單,我已定義了一個提供基本算術功能、一個小型類型系統以及基於控制台的簡單用戶交互的語言語法。
Figure 1 Good for Nothing 語言定義
<stmt> := var <ident> = <expr> | <ident> = <expr> | for <ident> = <expr> to <expr> do <stmt> end | read_int <ident> | print <expr> | <stmt> ; <stmt> <expr> := <string> | <int> | <arith_expr> | <ident> <arith_expr> := <expr> <arith_op> <expr> <arith_op> := + | - | * | / <ident> := <char> <ident_rest>* <ident_rest> := <char> | <digit> <int> := <digit>+ <digit> := 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 <string> := " <string_elem>* " <string_elem> := <any char other than ">
您可能已注意到,在此語言定義中,特性部分的長度很短。我沒有指定數字可以為多大(例如是否可以大於 32 位整數),甚至也未指定是否可以為負數。真正的 EBNF 定義將准確定義這些細節,但是為了簡明起見,在此處的示例中未包含這部分信息。
下面是一個“Good for Nothing”語言程序示例:
var ntimes = 0; print "How much do you love this company? (1-10) "; read_int ntimes; var x = 0; for x = 0 to ntimes do print "Developers!"; end; print "Who said sit down?!!!!!";
您可以將此示例程序與語言定義進行比較,從而更好地理解語法的工作原理。到這裡為止,語言定義就完成了。
高級體系結構
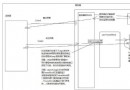
編譯器的任務就是將編程人員創建的高級任務轉換為計算機處理器可以理解和執行的任務。換句話說,編譯器將編譯用“Good for Nothing”語言編寫的程序並將該程序轉換為 .NET CLR 可以執行的程序。編譯器可以通過一系列轉換步驟(將語言分為我們關心的部分並拋棄我們不需要的內容)來實現這一操作。編譯器遵循常規軟件設計原則,將稱為“階段”的松散耦合組件組合在一起以執行轉換步驟。圖 2 顯示了執行編譯器的各階段的組件:掃描器、分析器和代碼生成器。在每個階段中,對語言進行了進一步的分解,有關程序目標的信息將在下一階段介紹。
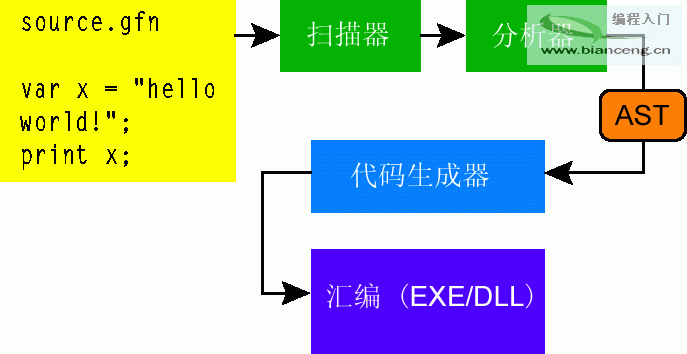
圖 2 編譯器各階段
編譯器奇客通常會將這些階段抽象地分組為前端和後端。前端包括掃描和分析,而後端通常包括代碼生成。前端的任務是發現程序的句法結構,並將程序從文本轉換為稱作“抽象語法樹”(AST) 的高級內存中表示形式(稍後我將對其進行簡短介紹)。後端的任務是獲取 AST 並將其轉換為計算機可以執行的語法。
因為掃描器和分析器通常耦合在一起,而代碼生成器通常緊緊地耦合到目標平台,所以編譯器通常將三個階段分為前端和後端。此設計允許開發人員在語言要求跨平台的情況下替換不同平台的代碼生成器。
我已在本文隨附的代碼下載中提供了“Good for Nothing”編譯器的代碼。在我介紹每個階段的組件以及探討實現細節時,您可以照著操作。
掃描器
掃描器的主要任務是將文本(源文件中的字符流)分解為分析器可以使用的塊(稱作“標記”)。掃描器確定最終發送到分析器的標記,因此能夠引發語法中未定義的內容(如注釋)。對於“Good for Nothing”語言,掃描器關注字符(A-Z 和常用符號)、數字 (0-9)、定義操作的字符(例如 +、-、* 和 /)、用於字符串封裝的問號以及分號。
掃描器將相關字符流一起分組為標記以供分析器使用。例如,字符流“h e l l o w o r l d !”將分組為一個標記“hello world!”。
“Good for Nothing”掃描器非常簡單,僅在實例化時需要一個 System.IO.TextReader。這將啟動掃描進程,如下所示:
public Scanner(TextReader input)
{
this.result = new Collections.List<object>();
this.Scan(input);
}
圖 3 顯示了 Scan 方法,該方法具有一個簡單的 while 循環,用於遍歷文本流中的每個字符並查找在語言定義中聲明的可識別字符。每次找到可識別字符或字符塊時,掃描器都會創建一個標記並將其添加到 List<object>(在這種情況下,我將其作為對象鍵入。但是,我應創建 Token 類或類似內容,以封裝有關標記的詳細信息,如行號和列號)。
Figure 3 掃描器的掃描方法
private void Scan(TextReader input)
{
while (input.Peek() != -1)
{
char ch = (char)input.Peek();
// Scan individual tokens
if (char.IsWhiteSpace(ch))
{
// eat the current char and skip ahead
input.Read();
}
else if (char.IsLetter(ch) || ch == '_')
{
StringBuilder accum = new StringBuilder();
input.Read(); // skip the '"'
if (input.Peek() == -1)
{
throw new Exception("unterminated string literal");
}
while ((ch = (char)input.Peek()) != '"')
{
accum.Append(ch);
input.Read();
if (input.Peek() == -1)
{
throw new Exception("unterminated string literal");
}
}
// skip the terminating "
input.Read();
this.result.Add(accum);
}
...
}
}
您可以看到,如果代碼遇到 " 字符,它會假設該字符將封裝字符串標記;因此我使用該字符串,並將其打包到 StringBuilder 實例和添加到列表中。在掃描生成標記列表之後,標記將通過一個名為 Tokens 的屬性轉到 parser 類。
分析器
分析器是編譯器的心髒,以多種形式和大小呈現。“Good for Nothing”分析器執行多種任務:確保源程序符合語言定義,如果存在故障,則會處理錯誤的輸出。分析器還會創建代碼生成器使用的程序語法的內存中表示形式,而且,“Good for Nothing”分析器還可以確定要使用的運行時類型。
我首先要做的事情就是看一下程序語法 AST 的內存中表示形式。然後將查看通過掃描器標記創建此語法樹的代碼。將快速、高效、方便地對 AST 格式編寫代碼,並且代碼生成器可以對該格式遍歷多次。圖 4 中顯示了“Good for Nothing”編譯器的 AST。
Figure 4 Good for Nothing 編譯器的 AST
public abstract class Stmt
{
}
// var <ident> = <expr>
public class DeclareVar : Stmt
{
public string Ident;
public Expr Expr;
}
// print <expr>
public class Print : Stmt
{
public Expr Expr;
}
// <ident> = <expr>
public class Assign : Stmt
{
public string Ident;
public Expr Expr;
}
// for <ident> = <expr> to <expr> do <stmt> end
public class ForLoop : Stmt
{
public string Ident;
public Expr From;
public Expr To;
public Stmt Body;
}
// read_int <ident>
public class ReadInt : Stmt
{
public string Ident;
}
// <stmt> ; <stmt>
public class Sequence : Stmt
{
public Stmt First;
public Stmt Second;
}
/* <expr> := <string>
* | <int>
* | <arith_expr>
* | <ident>
*/
public abstract class Expr
{
}
// <string> := " <string_elem>* "
public class StringLiteral : Expr
{
public string Value;
}
// <int> := <digit>+
public class IntLiteral : Expr
{
public int Value;
}
// <ident> := <char> <ident_rest>*
// <ident_rest> := <char> | <digit>
public class Variable : Expr
{
public string Ident;
}
// <arith_expr> := <expr> <arith_op> <expr>
public class ArithExpr : Expr
{
public Expr Left;
public Expr Right;
public BinOp Op;
}
// <arith_op> := + | - | * | /
public enum ArithOp
{
Add,
Sub,
Mul,
Div
}
“Good for Nothing”語言定義的快速概覽顯示了與來自 EBNF 語法的語言定義節點松散匹配的 AST。雖然抽象語法樹會捕獲這些元素的結構,但在封裝語法時最好考慮一下語言定義。
可以通過多種算法進行分析,但探討算法不在本文論述范圍之內。總之,這些算法在遍歷標記流以創建 AST 方面不同。在“Good for Nothing”編譯器中,我使用了名為 LL(從左到右、最左派生)的自上而下的分析器。這僅意味著從左到右讀取文本,並根據下一個可用輸入標記構造 AST。
我的分析器類的構造函數僅采用掃描器創建的標記列表:
public Parser(IList<object> tokens)
{
this.tokens = tokens;
this.index = 0;
this.result = this.ParseStmt();
if (this.index != this.tokens.Count)
throw new Exception("expected EOF");
}
分析工作的核心由 ParseStmt 方法完成,如圖 5 中所示。該方法返回的 Stmt 節點充當樹的根節點,且與語言語法定義的頂級節點相匹配。通過在標識對語言語法(變量聲明和分配、for 循環、read_ints 和輸出)中的 Stmt 節點有用的標記時使用索引作為當前位置,分析器可以遍歷標記列表。如果無法標識標記,則將引發異常。
Figure 5 ParseStmt 方法識別標記
private Stmt ParseStmt()
{
Stmt result;
if (this.index == this.tokens.Count)
{
throw new Exception("expected statement, got EOF");
}
if (this.tokens[this.index].Equals("print"))
{
this.index++;
...
}
else if (this.tokens[this.index].Equals("var"))
{
this.index++;
...
}
else if (this.tokens[this.index].Equals("read_int"))
{
this.index++;
...
}
else if (this.tokens[this.index].Equals("for"))
{
this.index++;
...
}
else if (this.tokens[this.index] is string)
{
this.index++;
...
}
else
{
throw new Exception("parse error at token " + this.index +
": " + this.tokens[this.index]);
}
...
}
如果標識了某個標記,則會創建 AST 節點並執行該節點所要求的任何進一步分析。創建輸出 AST 代碼所需的代碼如下所示:
// <stmt> := print <expr>
if (this.tokens[this.index].Equals("print"))
{
this.index++;
Print print = new Print();
print.Expr = this.ParseExpr();
result = print;
}
這裡發生了兩件事情。由於語言定義要求輸出標記後跟表達式,因此可以通過增加索引計數器來丟棄輸出標記,並且可以調用 ParseExpr 方法來獲取 Expr 節點。
圖 6 顯示了 ParseExpr 代碼。該代碼遍歷當前索引的標記列表,標識符合表達式的語言定義要求的標記。在這種情況下,該方法僅查找字符串、整數和變量(由掃描器實例創建),並返回表示這些表達式的適當 AST 節點。
Figure 6 ParseExpr 執行表達式節點分析
// <expr> := <string>
// | <int>
// | <ident>
private Expr ParseExpr()
{
...
if (this.tokens[this.index] is StringBuilder)
{
string value = ((StringBuilder)this.tokens[this.index++]).ToString();
StringLiteral stringLiteral = new StringLiteral();
stringLiteral.Value = value;
return stringLiteral;
}
else if (this.tokens[this.index] is int)
{
int intValue = (int)this.tokens[this.index++];
IntLiteral intLiteral = new IntLiteral();
intLiteral.Value = intValue;
return intLiteral;
}
else if (this.tokens[this.index] is string)
{
string ident = (string)this.tokens[this.index++];
Variable var = new Variable();
var.Ident = ident;
return var;
}
...
}
對於符合“<stmt> ; <stmt>”語言語法定義要求的字符串語句,將使用序列 AST 節點。此序列節點包含兩個指向 stmt 節點的指針,並形成 AST 樹結構的基礎。下面詳細介紹了用於處理序列示例的代碼:
if (this.index < this.tokens.Count && this.tokens[this.index] ==
Scanner.Semi)
{
this.index++;
if (this.index < this.tokens.Count &&
!this.tokens[this.index].Equals("end"))
{
Sequence sequence = new Sequence();
sequence.First = result;
sequence.Second = this.ParseStmt();
result = sequence;
}
}
圖 7 中顯示的 AST 樹是“Good for Nothing”代碼的以下代碼段的運行結果:
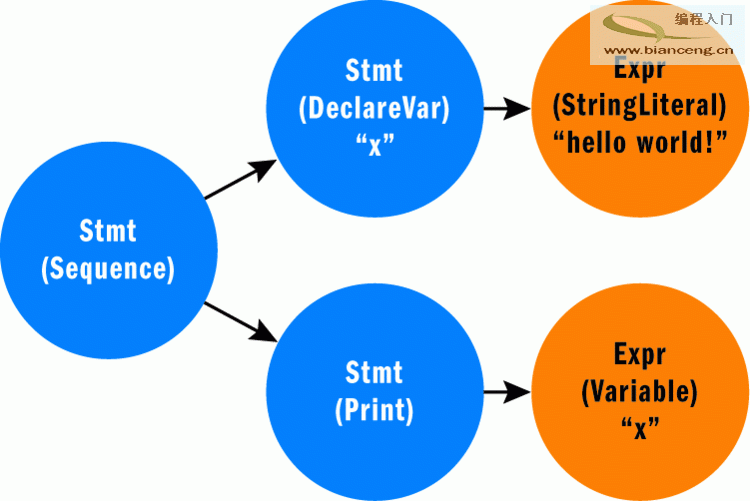
圖 7 helloworld.gfn AST 樹和高級別跟蹤
var x = "hello world!"; print x;
以 .NET Framework 為目標
在獲取執行代碼生成的代碼之前,首先回顧一下我們的目標。因此,下面我將介紹 .NET CLR 提供的編譯器服務,包括基於堆棧的虛擬機、類型系統和用於創建 .NET 程序集的庫。我還將簡要談及標識和診斷編譯器輸出中的錯誤所需的工具。
CLR 是一個虛擬機,也就是說它是一款模擬計算機系統的軟件。與任何計算機一樣,CLR 具有一組它可以執行的低級操作,一組內存服務,以及一種用來定義可執行程序的匯編語言。CLR 使用基於堆棧的抽象數據結構來模擬代碼的執行,並使用一種名為“中間語言”(IL) 的匯編語言來定義可在堆棧上執行的操作。
如果執行了用 IL 定義的計算機程序,則 CLR 將只模擬根據堆棧指定的操作,按指令壓入和彈出要執行的數據。假設要使用 IL 將兩個數值相加。以下代碼演示了 10 + 20 執行過程:
ldc.i4 10 ldc.i4 20 add
第一行 (ldc.i4 10) 將整數 10 壓入堆棧。第二行 (ldc.i4 20) 接著將整數 20 壓入堆棧。第三行 (add) 將這兩個整數彈出堆棧,再將它們相加,然後將結果壓入堆棧。
通過將 IL 和堆棧語義轉換為處理器的基礎計算機語言,可以在運行時通過實時 (JIT) 編譯或預先通過本機映像生成器 (Ngen) 等服務模擬堆棧計算機。
存在許多可用於構建程序的 IL 指令,范圍從基本算法到流控制再到多種調用約定。有關所有 IL 指令的詳細信息,請查看歐洲計算機廠家協會 (ECMA) 規范(位於 msdn2.microsoft.com/aa569283)的第 III 部分。
CLR 的抽象堆棧不只是對整數執行操作。它的類型系統內容非常豐富,包括字符串、整數、布爾型、浮點、雙精度型等。為了使我的語言能夠在 CLR 上安全運行且與其他符合 .NET 的語言進行互操作,我將某些 CLR 類型系統並入自己的程序中。具體說來,“Good for Nothing”語言定義了數字和字符串兩種類型,我已將這兩種類型映射到 System.Int32 和 System.String。
“Good for Nothing”編譯器使用名為 System.Reflection.Emit 的基類庫 (BCL) 組件來處理 IL 代碼生成及 .NET 程序集的創建和打包操作。該庫是一個低級庫,它通過 IL 語言提供簡單代碼生成抽象功能而與底層硬件緊密相關。也可通過其他已知 BCL API(包括 System.Xml.XmlSerializer)使用該庫。
創建 .NET 程序集(圖 8 中所示)所需的高級類具有每個邏輯 .NET 元數據抽象的生成器 API,因此一定程度上遵循生成器軟件設計模式。AssemblyBuilder 類用於創建 PE 文件和設置必要的 .NET 程序集元數據元素(如清單)。ModuleBuilder 類用於在程序集內創建模塊。TypeBuilder 類用於創建 Types 及其相關元數據。MethodBuilder 和 LocalBuilder 類則用於將 Methods 和 Locals 分別添加到 Types 和 Methods 中。ILGenerator 類用於使用 OpCodes 類(一個包含所有可能的 IL 指令的大枚舉)為 Methods 生成 IL 代碼。“Good for Nothing”代碼生成器中使用了所有這些 Reflection.Emit 類。
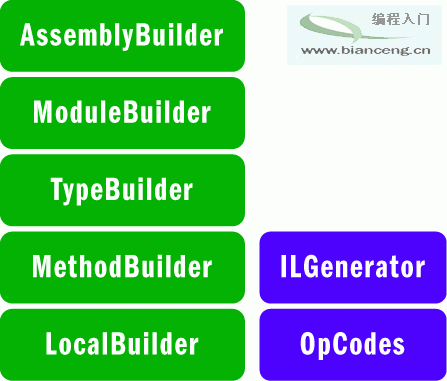
圖 8 用於構建 .NET 程序集的 Reflection.Emit 庫
正確獲得 IL 的工具
即使是經驗最豐富的編譯器黑客,也有可能在代碼生成級別出錯。最常見的故障是 IL 代碼出錯,這會導致堆棧中出現不平衡。如果發現 IL 出錯(在加載程序集或對 IL 執行 JIT 時,具體取決於程序集的信任級別),則 CLR 通常將引發異常。使用名為 peverify.exe 的 SDK 工具可以方便地診斷和修復這些錯誤。該工具將對 IL 進行驗證,確保代碼正確並且可以安全地執行。
例如,下面顯示了一些嘗試將數字 10 與字符串“bad”相加的 IL 代碼:
ldc.i4 10 ldstr "bad" add
對包含此錯誤 IL 的程序集運行 peverify 將導致發生以下錯誤:
[IL]: Error: [C:\MSDNMagazine\Sample.exe : Sample::Main][offset 0x0000002][found ref 'System .String'] Expected numeric type on the stack.
在此示例中,peverify 報告 add 指令期望兩種數值類型相加,卻發現一個是整數類型,另一個是字符串類型。
ILASM(IL 匯編程序)和 ILDASM(IL 反匯編程序)是兩種 SDK 工具,用於將文本 IL 編譯為 .NET 程序集,並將得到的程序集相應地反編譯為 IL。使用 ILASM 可以快速簡便地測試將成為編譯器輸出基礎的 IL 指令流。只需在文本編輯器中創建測試 IL 代碼並將其輸入 ILASM。同時,ILDASM 工具可以快速查看編譯器為特定代碼路徑生成的 IL。其中包括 C# 編譯器等商業編譯器發出的 IL。該工具提供用於查看語言之間類似語句的 IL 代碼的良好方法;換句話說,具有類似結構的其他編譯器可以重用為 C# 的 for 循環生成的 IL 流控制代碼。
代碼生成器
“Good for Nothing”編譯器的代碼生成器嚴重依賴 Reflection.Emit 庫來生成可執行 .NET 程序集。我將介紹和分析類的重要部分;其他部分留待您空閒時細讀。
圖 9 中顯示的 CodeGen 構造函數用於設置 Reflection.Emit 基礎結構,在開始發出代碼之前需要該基礎結構。首先我會定義程序集的名稱並將其傳遞給程序集生成器。在此示例中,我使用源文件名作為程序集名稱。接著定義一個 ModuleBuilder 模塊,使用的名稱與程序集名稱相同。然後在 ModuleBuilder 上定義 TypeBuilder,以僅保留程序集中的類型。沒有定義任何類型作為“Good for Nothing”語言定義的第一個類成員,但至少需要一個類型才能在啟動時保留運行的方法。MethodBuilder 定義 Main 方法來保留將為“Good for Nothing”代碼生成的 IL。我必須對此 MethodBuilder 調用 SetEntryPoint,以便在用戶運行可執行程序時該類能在啟動時運行。然後我使用 GetILGenerator 方法從 MethodBuilder 創建全局 ILGenerator (il)。
Figure 9 CodeGen 構造函數
Emit.ILGenerator il = null;
Collections.Dictionary<string, Emit.LocalBuilder> symbolTable;
public CodeGen(Stmt stmt, string moduleName)
{
if (Path.GetFileName(moduleName) != moduleName)
{
throw new Exception("can only output into current directory!");
}
AssemblyName name = new
AssemblyName(Path.GetFileNameWithoutExtension(moduleName));
Emit.AssemblyBuilder asmb =
AppDomain.CurrentDomain.DefineDynamicAssembly(name,
Emit.AssemblyBuilderAccess.Save);
Emit.ModuleBuilder modb = asmb.DefineDynamicModule(moduleName);
Emit.TypeBuilder typeBuilder = modb.DefineType("Foo");
Emit.MethodBuilder methb = typeBuilder.DefineMethod("Main",
Reflect.MethodAttributes.Static,
typeof(void),
System.Type.EmptyTypes);
// CodeGenerator
this.il = methb.GetILGenerator();
this.symbolTable = new Dictionary<string, Emit.LocalBuilder>();
// Go Compile
this.GenStmt(stmt);
il.Emit(Emit.OpCodes.Ret);
typeBuilder.CreateType();
modb.CreateGlobalFunctions();
asmb.SetEntryPoint(methb);
asmb.Save(moduleName);
this.symbolTable = null;
this.il = null;
}
設置 Reflection.Emit 基礎結構後,代碼生成器將調用用於遍歷 AST 的 GenStmt 方法。這將通過全局 ILGenerator 生成必要的 IL 代碼。圖 10 顯示了 GenStmt 方法的子集,首次調用該方法時,從 Sequence 節點開始,然後繼續根據當前 AST 節點類型執行 AST 切換。
Figure 10 GenStmt 方法的子集
private void GenStmt(Stmt stmt)
{
if (stmt is Sequence)
{
Sequence seq = (Sequence)stmt;
this.GenStmt(seq.First);
this.GenStmt(seq.Second);
}
else if (stmt is DeclareVar)
{
...
}
else if (stmt is Assign)
{
...
}
else if (stmt is Print)
{
...
}
}
DeclareVar(用於聲明一個變量)AST 節點的代碼如下所示:
else if (stmt is DeclareVar)
{
// declare a local
DeclareVar declare = (DeclareVar)stmt;
this.symbolTable[declare.Ident] =
this.il.DeclareLocal(this.TypeOfExpr(declare.Expr));
// set the initial value
Assign assign = new Assign();
assign.Ident = declare.Ident;
assign.Expr = declare.Expr;
this.GenStmt(assign);
}
這裡需要完成的第一件事情是向符號表中添加變量。符號表是核心編譯器數據結構,用於將符號標識符(在這種情況下為基於字符串的變量名稱)與其類型、位置和程序中的范圍相關聯。“Good for Nothing”符號表很簡單,因為所有變量聲明都位於 Main 方法中。因此我使用簡單的 Dictionary<string, LocalBuilder> 將符號與 LocalBuilder 關聯起來。
將符號添加到符號表後,我會將 DeclareVar AST 節點轉換為 Assign 節點,以便為變量分配變量聲明表達式。使用以下代碼生成 Assignment 語句:
else if (stmt is Assign)
{
Assign assign = (Assign)stmt;
this.GenExpr(assign.Expr, this.TypeOfExpr(assign.Expr));
this.Store(assign.Ident, this.TypeOfExpr(assign.Expr));
}
執行此操作可生成 IL 代碼以將表達式加載到堆棧上,然後發出 IL 將表達式存儲在適當的 LocalBuilder 中。
圖 11 中顯示的 GenExpr 代碼獲取 Expr AST 節點,並將加載表達式所需的 IL 發出到堆棧計算機上。StringLiteral 和 IntLiteral 有些類似,因為它們都會將用於加載相應字符串和整數的 IL 指令定向到堆棧上:ldstr 和 ldc.i4。
Figure 11 GenExpr 方法
private void GenExpr(Expr expr, System.Type expectedType)
{
System.Type deliveredType;
if (expr is StringLiteral)
{
deliveredType = typeof(string);
this.il.Emit(Emit.OpCodes.Ldstr, ((StringLiteral)expr).Value);
}
else if (expr is IntLiteral)
{
deliveredType = typeof(int);
this.il.Emit(Emit.OpCodes.Ldc_I4, ((IntLiteral)expr).Value);
}
else if (expr is Variable)
{
string ident = ((Variable)expr).Ident;
deliveredType = this.TypeOfExpr(expr);
if (!this.symbolTable.ContainsKey(ident))
{
throw new Exception("undeclared variable '" + ident + "'");
}
this.il.Emit(Emit.OpCodes.Ldloc, this.symbolTable[ident]);
}
else
{
throw new Exception("don't know how to generate " +
expr.GetType().Name);
}
if (deliveredType != expectedType)
{
if (deliveredType == typeof(int) &&
expectedType == typeof(string))
{
this.il.Emit(Emit.OpCodes.Box, typeof(int));
this.il.Emit(Emit.OpCodes.Callvirt,
typeof(object).GetMethod("ToString"));
}
else
{
throw new Exception("can't coerce a " + deliveredType.Name +
" to a " + expectedType.Name);
}
}
}
變量表達式通過調用 ldloc 並在相應 LocalBuilder 中傳遞,可以僅將方法的本地變量加載到堆棧上。圖 11 中顯示的最後一部分代碼用於將表達式類型轉換為預期類型(稱為“類型強制”)。例如,可能需要在調用中將類型轉換為 print 方法,而將整數轉換為字符串以便可以成功輸出。
圖 12 演示了如何將變量分配給 Store 方法中的表達式。通過符號表查詢變量名稱,然後將對應的 LocalBuilder 傳遞給 stloc IL 指令。這只會從堆棧彈出當前表達式並將表達式分配給本地變量。
Figure 12 存儲變量表達式
else if (stmt is Print)
{
this.GenExpr(((Print)stmt).Expr, typeof(string));
this.il.Emit(Emit.OpCodes.Call,
typeof(System.Console).GetMethod("WriteLine",
new Type[] { typeof(string) }));
}
調用某個方法時,方法參數按後進先出的方式從堆棧彈出。也就是,方法的第一個參數來自堆棧頂項,第二個參數來自第一個的下面,依此類推。
這裡最復雜的代碼就是為“Good for Nothing”for 循環生成 IL 的代碼(參見圖 13)。這與商業編譯器生成此種類型代碼的方法很類似。但是,解釋 for 循環最好的方式是查看生成的 IL(圖 14 中所示)。
Figure 14 For 循環 IL 代碼
// for x = 0
IL_0006: ldc.i4 0x0
IL_000b: stloc.0
// jump to the test
IL_000c: br IL_0023
// execute the loop body
IL_0011: ...
// increment the x variable by 1
IL_001b: ldloc.0
IL_001c: ldc.i4 0x1
IL_0021: add
IL_0022: stloc.0
// TEST
// load x, load 100, branch if
// x is less than 100
IL_0023: ldloc.0
IL_0024: ldc.i4 0x64
IL_0029: blt IL_0011
Figure 13 For 循環代碼
else if (stmt is ForLoop)
{
// example:
// var x = 0;
// for x = 0 to 100 do
// print "hello";
// end;
// x = 0
ForLoop forLoop = (ForLoop)stmt;
Assign assign = new Assign();
assign.Ident = forLoop.Ident;
assign.Expr = forLoop.From;
this.GenStmt(assign);
// jump to the test
Emit.Label test = this.il.DefineLabel();
this.il.Emit(Emit.OpCodes.Br, test);
// statements in the body of the for loop
Emit.Label body = this.il.DefineLabel();
this.il.MarkLabel(body);
this.GenStmt(forLoop.Body);
// to (increment the value of x)
this.il.Emit(Emit.OpCodes.Ldloc, this.symbolTable[forLoop.Ident]);
this.il.Emit(Emit.OpCodes.Ldc_I4, 1);
this.il.Emit(Emit.OpCodes.Add);
this.Store(forLoop.Ident, typeof(int));
// **test** does x equal 100? (do the test)
this.il.MarkLabel(test);
this.il.Emit(Emit.OpCodes.Ldloc, this.symbolTable[forLoop.Ident]);
this.GenExpr(forLoop.To, typeof(int));
this.il.Emit(Emit.OpCodes.Blt, body);
}
IL 代碼首先分配初始 for 循環計數器,然後立即使用 IL 指令 br(分支)跳轉到 for 循環測試。與 IL 代碼左側列出的標簽相似的標簽用於讓運行時知道下一個指令分支到的地方。測試代碼將使用 blt(如果小於則分支)指令檢查變量 x 是否小於 100。如果為 True,則執行循環體,同時遞增 x 變量,然後再次運行測試。
圖 13 中的 for 循環代碼生成對計數器變量執行分配和增量操作所需的代碼。還可以對 ILGenerator 使用 MarkLabel 方法來生成分支指令可以分支到的標簽。
總結...幾乎涵蓋所有方面
我已根據簡單的 .NET 編譯器演練了代碼並探討了一些基本原理。本文旨在為您提供構造編譯器這個神秘世界的基礎。盡管在網上您能夠發現一些有價值的信息,但是還應參考一些書籍。我向您推薦以下書籍:《Compiling for the .NET Common Language Runtime》,作者:John Gough(Prentice Hall,2001);《Inside Microsoft IL Assembler》,作者:Serge Lidin(Microsoft Press?,2002);《Programming Language Pragmatics》,作者:Michael L. Scott(Morgan Kaufmann,2000)以及《Compilers: Principles, Techniques, and Tools》,作者:Alfred V. Oho、Monica S. Lam、Ravi Sethi 和 Jeffrey Ullman(Addison Wesley,2006)。
這些書籍完全涵蓋了編寫自己的語言編譯器需要了解的核心內容;不過,我並沒有真正完成對編譯器的討論。對於特別重要的內容,我將查看一些高級主題以更好地為您講解。
動態方法調用
方法調用是所有計算機語言的基礎,但調用存在一個范圍。較新的語言(如 Python)會將方法和調用的綁定延遲到最後一刻,這稱為“動態調用”。流行的動態語言(如 Ruby、JavaScript、Lua,甚至 Visual Basic)都具有這一模式。為了使編譯器發出代碼以執行方法調用,編譯器必須將方法名稱看作一個符號,並將其傳遞給將按照語言語義執行綁定和調用操作的運行庫。
假設您關閉了 Visual Basic 8.0 編譯器中的 Option Strict。方法調用會成為後期綁定,Visual Basic 運行時將在運行時執行綁定和調用操作。
Visual Basic 編譯器不會向 Method1 方法發出 IL 調用指令,而是向名為 CompilerServices.NewLateBinding.LateCall 的 Visual Basic 運行時方法發出調用指令。在此過程中,編譯器將傳入一個對象 (obj) 以及方法 (Method1) 的符號名稱,並傳入所有方法參數。Visual Basic LateCall 方法然後會使用 Reflection 來查詢對象的 Method1 方法,如果找到,則執行基於 Reflection 的方法調用:
Option Strict Off
Dim obj
obj.Method1()
IL_0001: ldloc.0
IL_0003: ldstr "Method1"
...
IL_0012: call object CompilerServices.NewLateBinding::LateCall(object, ... , string, ...)
使用 LCG 快速執行後期綁定
基於 Reflection 的方法調用的速度可能特別慢(請參閱我在網上發表的文章:“Reflection: Dodge Common Performance Pitfalls to Craft Speedy Applications”,網址是 msdn.microsoft.com/msdnmag/issues/05/07/Reflection)。方法綁定和方法調用都比簡單的 IL 調用指令要慢得多。.NET Framework 2.0 CLR 包括一項名為“輕量級代碼生成”(LCG) 的功能,該功能可用於動態創建彈出代碼,從而使用速度更快的 IL 調用指令在調用站點和方法之間搭建橋梁。這將顯著增加方法調用的速度。仍需要查詢對象的方法,如果找到,則可以針對每個重復調用創建和緩存 DynamicMethod 橋接。
圖 15 顯示了一種非常簡單的後期綁定,用於執行 bridge 方法的動態代碼生成。該綁定首先查詢緩存並查看以前是否見過該調用站點。調用站點首次運行時,將生成 DynamicMethod,該方法返回一個對象並將對象數組作為參數。對象數組參數包含的實例對象和參數用於對方法進行最終調用。生成的 IL 代碼將對象數組解壓縮到堆棧上,首先解壓縮實例對象然後解壓縮參數。然後將發出調用指令並將調用結果返回被調用方。
通過委托快速調用 LCG 橋接方法。我只是將橋接方法的參數包裝到一個對象數組中然後進行調用。首次進行調用時,JIT 編譯器將編譯動態方法並執行 IL,然後調用最終方法。
此代碼本質上是由早期綁定靜態編譯器生成的。該編譯器先將實例對象壓入堆棧,然後壓入參數,之後使用調用指令進行方法調用。通過這種巧妙的方法可以將語義延遲到最後一刻,從而滿足在多數動態語言中見到的後期綁定調用語義的要求。
動態語言運行時
如果您想在 CLR 上認真實施動態語言,則必須查看 CLR 團隊在 4 月下旬宣布的動態語言運行時 (DLR)。其中包含構建順利執行同時與 .NET Framework 和其他符合 .NET 語言的生態系統進行互操作的動態語言所需的工具和庫。這些庫提供創建動態語言的用戶需要的所有內容,其中包括對常見動態語言抽象(速度最快的後期綁定方法調用、類型系統互操作性等)、動態類型系統和共享 AST 進行高性能實施,對 Read Eval Print Loop (REPL) 的支持以及其他方面的內容。
深入研究 DLR 不在本文論述范圍之內,但我建議您親自查看它為動態語言提供的服務。有關 DLR 的詳細信息,請查看 Jim Hugunin 的博客 (blogs.msdn.com/hugunin)。
本文配套源碼