除非您一直與世隔絕,否則肯定聽說過“多核轉換”。處理器制造商 Intel 和 AMD 正在 通過增加處理器的內核數來提高硬件性能,而非一味地試圖繼續提高指數級增長的時鐘速度。這種轉換對 軟件開發人員提出了新的要求,他們必須開始考慮以並發方式編寫所有應用程序,以便能夠從這些顯著提 升的計算性能中受益。
為了因應這一挑戰,許多並發庫和語言陸續問世,其中包括針對 Microsoft .NET Framework 的並行 擴展、並行模式庫 (PPL)、並發和協調運行庫 (CCR)、Intel 的線程構建塊 (TBB) 等。這些庫都旨在通 過提供 Parallel.For 和 AsParallel 等結構來減少編寫高效並行應用程序所需的樣板代碼數量。遺憾的 是,盡管這些結構代表了在並行表達方面所取得的巨大進步,但它們卻無法從根本上解決開發人員所面臨 的諸多問題,例如必須了解代碼的執行情況、代碼的構建方式以及硬件對應用程序的性能究竟有何重要影 響等。
盡管軟件行業為處理並發問題而專門開發的編程模型有了長足發展,但似乎並沒有哪種編 程模型能夠在不久的將來神奇般地消除所有與並發相關的問題。至少在最近一段時期內,了解內存和緩存 的工作原理還是相當重要的,因為只有這樣才能編寫出高效的並行程序。
完全歸結為硬件
當然,了解某個應用程序的底層正在發生什麼業已不是新概念了。為達到最佳性能,開發人員需要深入了 解諸如內存訪問等過程會對應用程序的性能產生哪些影響。
當我們談及內存的讀取和寫入時,通 常會忽略這一實事,即目前的硬件已很少會直接讀取或寫入計算機的內存條。內存訪問過慢 - 數量級慢 於數學計算(盡管要比訪問硬盤和網絡資源快很多)。
為解決這種內存訪問較慢的問題,目前大 多數處理器都使用內存緩存來改進應用程序的性能。緩存可分為多個級別,大多數消費級計算機都至少有 兩個級別(被稱為 L1 和 L2),某些計算機的級別會更多。L1 級別最快,但也最昂貴,因此通常計算機 只含有少量此類緩存(我們編寫此專欄所使用的便攜式計算機的 L1 緩存為 128KB)。L2 稍微慢一些, 但較為便宜,因此計算機中的此類緩存要略多一些(上面提到的便攜式計算機的 L2 緩存為 2MB)。
從內存中讀取數據時,會將請求的數據以及它周圍的數據(稱為緩存行)從內存加載到緩存,然 後緩存再將數據提供給程序。這種加載整個緩存行(而不是單個字節)的做法可明顯改進應用程序的性能 。在我們的便攜式計算機上,L1 和 L2 的緩存行均為 64 字節。由於應用程序經常需要連續讀取內存中 的字節(常見於訪問數組及類似對象),應用程序可通過加載緩存行中的一系列數據來避免在每次請求時 都命中主內存,因為很可能要讀取的數據已被加載到緩存中。但是,這將意味著開發人員必須了解應用程 序訪問內存的方式,只有這樣才能最大限度地發揮緩存的作用。
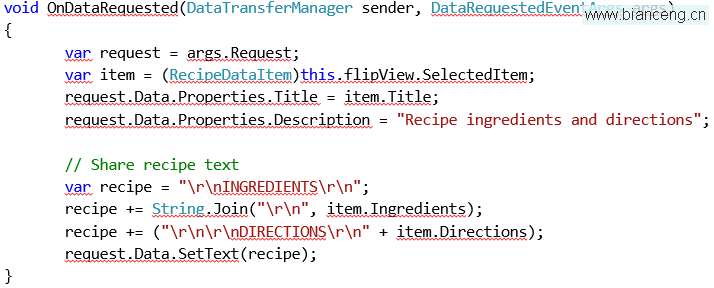
我們來看一下圖 1 中顯示的 C# 程序。我們創建了一個二維數組,應用程序然後將通過兩種方式向其中寫入數據。在第一個代碼段中(在 注釋中標記為 Faster),應用程序將逐行循環,而在各行中還將逐列循環。在第二個代碼段中(在注釋 中標記為 Slower),應用程序將逐列循環,而在各列中將逐行循環。本例中的標簽已經洩露了玄機,盡 管二者之間的唯一區別只是循環順序的變化,但我們在便攜式計算機上的測試表明,Faster 方式的運行 速度幾乎是 Slower 方式的兩倍。
圖 1 內存訪問模式很重要
using System;
using System.Diagnostics;
class Program {
public static void Main() {
const int SIZE = 10000;
int[,] matrix = new int[SIZE, SIZE];
while (true) {
// Faster
Stopwatch sw = Stopwatch.StartNew();
for (int row = 0; row < SIZE; row++) {
for (int column = 0; column < SIZE; column++) {
matrix[row, column] = (row * SIZE) + column;
}
}
Console.WriteLine(sw.Elapsed);
// Slower
sw = Stopwatch.StartNew();
for (int column = 0; column < SIZE; column++) {
for (int row = 0; row < SIZE; row++) {
matrix[row, column] = (row * SIZE) + column;
}
}
Console.WriteLine(sw.Elapsed);
Console.WriteLine("=================");
Console.ReadLine();
}
}
}
這種性能差異是由於矩陣數組組織方式的不同而導致的。數組在內存中是以行優先的次序連續 存儲的,這意味著您可以將矩陣中的各行想象成在內存中依次線性排列。應用程序訪問數組中的值時,相 應的緩存行將包含該值以及請求值周圍的值,它們很可能在同一行中前後緊鄰。因此,訪問同一行的下一 個值的速度要比訪問不同行中的值明顯快很多。在較慢的方式中,我們始終都是在行間跳躍來訪問不同行 中的值,然後訪問各行中的相同列位置。
與啟蒙教育相反 – 共享可能是錯誤的
並行性使得此問題的意義更為重大。我們不僅需 要了解處理器如何訪問內存中的數據以及如何利用其緩存,還需要了解多線程/多處理器如何訪問數據。
在如今的許多系統中,有些緩存並不是在多核之間共享的。由於緩存維護著主內存中數據的備份 ,因此處理器需要實現一種機制,以使主內存與其他緩存中的緩存內容保持同步;這種機制被稱為 “緩存協調性”或“內存協調性”協議。
當今大多數 Intel 處理器使用的 協議都是被稱為 MESI 的協議,這樣命名的原因是為了表示特定的緩存行可能處於的四種狀態:修改 (Modified)、獨占 (Exclusive)、共享 (Shared) 以及無效 (Invalid)。此協議可確保緩存能夠監視系統 中其他緩存的行為,並采取相應的措施來保持一致性,例如當某個緩存請求數據以進行讀取操作時,此協 議會用修改後的數據來刷新主內存。至少來說,這些請求進行內存讀/寫的操作其成本可能會非常高昂( 正如我們曾經講述和演示的那樣)。
遺憾的是,此問題要比乍看上去麻煩得多,因為在數據處於 共享狀態時它並不十分明顯。當兩個線程明確指明需要訪問某個給定的內存位置時就會發生真實共享,這 時可通過緩存協調性協議來保持一致性。但開發人員可能並不知道,當兩個線程訪問截然不同的數據集時 ,可能會發生其他共享,不過由於硬件體系結構細節(如緩存行的大小)的原因,只要采用緩存協調性協 議,這些數據集看起來仍像處於共享狀態一樣。這被稱作“錯誤共享”(如圖 2 所示),在 實際的並行應用程序中,這種共享會導致嚴重的性能問題。
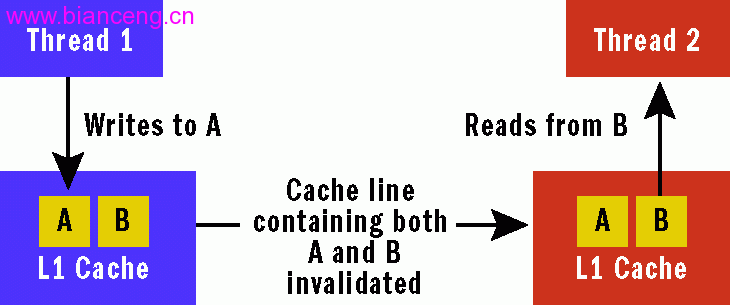
圖 2 緩存協調性和 緩存行
我們來看一下圖 3 中所示的代碼。在此代碼片段中,我們按照每個處理器對應一個 System.Random 實例的原則分配實例。然後我們將多次迭代並行運行它(使用任務並行庫中的 Parallel.For 構造,此並行庫是並行擴展的一部分)。每次迭代都使用其中一個 Random 實例並對其執 行某項操作(在本例中,將不斷調用 Random 實例的 Next)。
圖 3 錯誤共享的示例
static void WithFalseSharing() {
int iterations = Environment.ProcessorCount;
Random[] rands = new Random[iterations];
for (int i = 0; i < iterations; i++) rands[i] = new Random();
Parallel.For(0, iterations, i => {
Random r = rands[i];
DoWork(r);
});
}
static void DoWork(Random rand) {
for (int i = 0; i < WORKAMOUNT; i++) rand.Next();
}
本示例中由於存在共享,因此看起來可能並不明顯。此應用程序僅從 rand 數組進行過讀取, 它對要在兩個不同的緩存中進行讀取的同一緩存行十分有效(使用 MESI 協議,該行在兩種情況下可能都 標記為共享)。問題實際在於 Random 實例本身。每個 Random 實例都包含一些狀態,用來在其偽隨機值 序列中生成下一個值,每次調用 Next 時都會計算下一個值並更新內部狀態。由於這些 Random 實例分配 方法的原因,使得它們可以當其在內存中終止時彼此非常接近,從而導致實例間產生錯誤共享,即使從源 代碼角度看循環中涉及的所有線程都是獨立的。
解決錯誤共享問題的方法有多種,但所有這些方 法都要求在內存中分配這些 Random 實例時,應使其彼此間保持足夠的距離,以便它們不會出現在同一緩 存行中。在 .NET 中,內存分配細節被留給運行時處理,這樣一來將需要一些解決方法。
舉例說 明,圖 4 中的代碼顯示的是不會遇到同樣問題的代碼版本。在這一版本中,它在我們所擔心的兩個實例 之間分配了大量額外的 Random 實例,這將確保我們所關注的兩個實例之間有足夠大的距離,從而使其不 會出現錯誤共享(至少在這台計算機中)。在我們的測試中,這一更新版本得到的結果要好很多,在我們 的雙核測試計算機中,其速度是圖 3 中所示代碼的運行速度的六倍。
圖 4 修復錯誤共享的示例
static void WithoutFalseSharing() {
const int BUFFER = 64;
int iterations = Environment.ProcessorCount * BUFFER;
Random[] rands = new Random[iterations];
for (int i = 0; i < iterations; i++) rands[i] = new Random();
Parallel.For(0, iterations, BUFFER, i => {
Random r = rands[i];
DoWork(r);
});
}
static void DoWork(Random rand) {
for (int i = 0; i < WORKAMOUNT; i++) rand.Next();
}
檢測錯誤共享的方法
非常遺憾,錯誤共享很難被發現,因為並不存在專門的指示器能夠明確指 出某種情況是否屬於性能問題。值得慶幸的是,有一些分析指標可在一定程度上確認對錯誤共享的猜測, 有助於在代碼中縮小問題范圍。總之,您需要清楚何時懷疑可能存在錯誤共享,還需要知道在發現問題時 並發代碼中的內存訪問模式。
假設您已判斷出某個並發代碼段是性能的瓶頸。當代碼段出現下列 情況時,可能需要重點關注共享緩存行的效果:
與 CPU 和內存限制有關,使得只有少量 I/O 或 阻塞操作系統調用。
在通過運行性能更強的硬件提高了並行級別後,無法很好地對其進行調節。
對於需要相同的處理數和內存訪問數但不同的遍歷模式的不同輸入數據,偶爾會出現速度明顯下 降的情況。
我們發現可用於辨別錯誤共享效果的最佳提示是 CPU 性能計數器。CPU 自身包含了許 多硬件級別的統計數據,這些信息可反映出 CPU 不同子系統的運行情況。其中的示例包括 L2 緩存未命 中數以及分支預測未命中數。這些計數器的變體可能會隨著處理器型號的不同而異,但盡管這樣,也存在 著一個適用於大多數分析器的通用子集。我們將說明其中的幾個子集,即 L2 緩存未命中數、指令引退和 非終止周期。
L2 緩存未命中數表示因讀取 L2 緩存而導致從主內存加載的次數。如果請求的數據 未在 L2 緩存中出現,或者相應的緩存行由於其他處理器的更新而標記為無效,這時就可能發生 L2 未命 中情況。由於在出現錯誤共享時後一種情況會頻繁發生,因此在診斷此問題時我們需要注意觀察 L2 緩存 未命中計數器中的異常峰值。
每條指令執行周期 (CPI) 是其中一種常用的統計數據,可用來統計 在特征化算法基准時的整體性能。它用來表示在給定的運算期間,CPU 執行每條指令平均花費的時鐘周期 。雖然它並未作為專門的 CPU 性能計數器列出,但可從“指令引退”和“非終止周期 ”計數器中派生而來。
很顯然,此指標高度依賴於硬件(CPU 型號和時鐘速度、緩存體系結 構、內存速度等),通常會在這些硬件特征以外同時引用 CPI 值,以詳細提供某算法在特定硬件上的執 行效率情況。
在診斷錯誤共享時,我們可依據以下事實,即 CPI 測量除了包括 CPU 執行指令所 花的實際時鐘周期,還包括內存訪問延遲的影響和跨處理器緩存同步的開銷(這些都會導致 CPU 出現空 閒,浪費寶貴的時鐘周期)。這看起來非常適合手頭的任務,因為在其他條件都不變的情況下,錯誤共享 會明顯增加跨處理器通信的開銷和對主內存的訪問次數。因此,在出現錯誤共享時,完成同樣的操作會導 致 CPI 值增加。
我們還會注意到的有趣一點是,與 L2 緩存未命中計數器不同,CPI 指標與執行 時間是無關的。因此,可將其用於對持續時間不同的運行進行比較。
使用 Visual Studio 分析器
在 Visual Studio 中,L2 未命中在采樣和基於檢測的分析模式中都可以進行跟蹤,而 CPI 則需 要基於檢測的分析,因為它涉及到使用兩種 CPU 計數器。
要在采樣模式中對 L2 未命中進行分析 ,首先需要在 Visual Studio 中為項目創建一個基於采樣的性能會話。然後利用該會話的屬性將采樣事 件更改為“性能計數器”,再從“Portable Events”(可移植事件) >“Memory Events”(內存事件)類別中選擇“L2 Misses”(L2 未命中)或 從“Platform Events”(平台事件)>“L2 Cache”(L2 緩存)類別中選擇 “L2 Lines In”(L2 行輸入)。(在某些處理器中,L2 未命中被標記為不受支持。)
接下來您即可開始分析您的應用程序。所報告的數字將基於對每個 1M L2 未命中事件所取樣例的 分析。這意味著當按獨占樣本排序時,導致大多數 L2 未命中的函數將位於頂部。
要在檢測模式 下對 L2 未命中和 CPI 進行分析,可從基於檢測的性能會話入手。在此會話的屬性中,啟用 CPU 計數器 的收集,然後選擇感興趣的 CPU 計數器:“L2 緩存未命中”事件(如前所述),同時從 “Portable Events”(可移植事件)>“General”(常規)類別中選擇 “Instructions Retired”(指令引退)和“Non Halted Cycles”(非終止周期 )。
分析器生成的報告會包括大量的新列,用於顯示這些 CPU 計數器中的每個計數器所包含和排除的檢測 ,以及與耗時相關的常規指標。與我們的需求最相符的信息可從每個計數器的各函數排除值中找到。
在訪問較大范圍的內存時,函數中接收到許多 L2 未命中屬於正常現象,尤其是當該范圍大於或相當 於 L2 緩存大小時。但如果已知某個特定函數僅訪問了很小范圍的內存卻導致大量 L2 未命中數,最可能 的原因是這些未命中數是由共享的緩存行觸發的。此采樣測試既可應用於檢測,也可應用於基於采樣的分 析數據。但是,由於不容易判斷在正常情況下會得到哪些結果,因此在應用時最好考慮到具體的情況,例 如在面對不同的設置和並行級別時,可通過交叉引用同一算法的運行來加以應用。
您還可以嘗試更高級的方法。在檢測分析模式中,因某個給定函數而導致 L2 未命中的准確數量將在 “L2 Misses Exclusive”(L2 未命中獨占)列中報告。如果您粗略知道此函數引用的內存數量,也可以 利用這些數字來估計 L2 未命中數與總預期內存讀取情況的比較。但這一技術需要密切關注體系結構的細 節,如緩存行大小以及所用 CPU 計數器的實際行為等。
為說明此情況,圖 5 列示了在某個測試分析會話中收集的 L2 未命中統計數據。測試的應用程序將運 行四個重復遍歷的線程,並更新一個在內存中共占用約 100KB 的結構數組。測試計算機有四個 CPU(雙 槽雙核),L2 緩存總計為 4MB。
圖 5 某個測試會話中的 L2 未命中統計數據
在本示例中,我們無需考慮某個精確計算的體系結構細節即可從 L2 統計數據中辨別出錯誤共享情況 。很明顯,大量的分片讀取導致了 L2 未命中。雖然應用程序僅引用 100KB 的唯一內存(此數值足以為 L2 緩存提供足夠的分配空間),但報告的“L2 Lines In”(L2 行輸入)值卻接近總內存引用的數量級 。
有時,頻繁而短暫的函數調用可能會導致檢測的分析引入過量開銷,從而干擾運行時行為並因此影響 分析結果。在這些情況下,最好的辦法是依靠基於采樣的分析來收集 L2 統計數據。圖 3 和圖 4 中的示 例就是由於調用了大量 Random.Next 而導致出現這種情況。使用采樣方法來分析此示例時,我們得到了 如圖 6 所示的結果。盡管並不如圖 5 所示的結果那樣直觀,但我們在這裡判斷錯誤共享的線索是 L2 未 命中計數清楚表明,大量的分片 Random.Next 調用 (3.5M/40M) 導致了緩存重新加載,而從每個線程的 視角來看,引用的數據在內存中已知是完全保持靜態的。正常情況下的采樣結果如圖 6 所示,這也佐證 了這種說法。
圖 6 Random.Next 示例的 L2 未命中統計數據
特定函數的 CPI 指標可作為以下兩個性能計數器的比率進行計算:“獨占非終止周期”和“獨占指令 引退”。這需要使用兩個單獨的基於采樣的分析會話,因為這些計數器中只有一個可在給定的運行中進行 分析。
如前所述,對於某個給定算法的 CPI,它將高度依賴它所運行的硬件。因此,非常有必要僅針 對類似的硬件進行比較。使用此指標的方法之一就是比較同一運算在不同並發級別的不同運行情況。如果 在並發級別被降低時由於執行時間的差異而難以比較 L2 統計數據,則這會非常有用,因為 CPI 與運行 時間無關。
如果使用相同的數據在較少的 CPU 中運行時,同樣的算法得到的 CPI 值明顯偏小,則說 明該算法在較高並發級別對硬件的使用效率較低。如果該 CPI 指標關注的主要是代碼的計算部分,這樣 就排除了軟件同步的影響,從而更加明確地指出硬件效率的降低可能是由於緩存的影響而導致的。
錯誤共享僅僅是理論上的嗎?
對錯誤共享問題的描述聽起來相當深奧,就像是您在現實中從來不會遇 到的事。但此問題確實存在,並且在現實世界中常常會出人意料地發生。
盡管在編寫並行應用程序時 可以不考慮錯誤共享(取決於檢測此類問題的性能測試),但是在應用程序開發的設計和實施階段,始終 考慮到錯誤共享問題會很有好處。既然您已厭倦了編寫並行應用程序,那大概您會更加關注性能。如果您 竭盡全力設計您的應用程序,以使其能夠很好地適應多核環境,但最後卻發現很多並行加速設計成果都由 於錯誤共享而被抵消時,可能會感到非常失望。
另一件要牢記的事情是錯誤共享問題並非總能通過測 試輕松發現。此行為在某種程度上具有非確定性,可能會因硬件的不同而異(例如由於緩存行大小的不同 ),並可能會在正常更改代碼後發生徹底的改變。事實上,過去在編寫單線程應用程序時常被用來改善應 用程序性能的許多優化措施實際上會在多線程應用程序中導致嚴重的錯誤共享問題。如果您正在開發的應 用程序要求較高的性能,則必須在流程中及早考慮錯誤共享問題,只有這樣才有可能獲得最後的成功。
可能導致錯誤共享風險的內存位置
只有當錯誤共享所帶來的低效問題在計算時間中占主導地位時, 錯誤共享才被視為一個問題。如果緩存值偶爾才出現不必要的失效,則對整體執行時間的影響可被忽略。 但是,如果某個線程將大部分時間都花在對特定內存位置的讀取和寫入上,而該內存位置的緩存副本由於 錯誤共享一直被另一線程置於失效狀態,則解決該錯誤共享問題很可能會顯著改進應用程序的性能。
由於局部性的原則,程序通常會將大部分時間花在訪問彼此鄰近的內存位置上。以某個常見的並行計算方 案為例:多個線程協作計算一個結果。每個線程都計算一個中間結果,然後將不同線程提供的多個中間結 果合並起來生成最終結果。如果每個線程將其大部分時間都花在讀取和寫入中間結果上,而來自不同線程 的中間結果在內存中非常接近並位於同一緩存行中,則錯誤共享問題可能會明顯影響運算的性能。
關 於此模式的一個簡單示例就是並行計算某個數組中的整數之和。每個線程都處理數組的一段,並將該段中 的元素添加到累加器中。如果來自不同線程的累加器都位於同一緩存行,則由於線程將大部分時間都花在 了改寫其他線程的緩存上,從而導致性能很可能會受到在緩存級序列化應用程序執行過程的影響。
在 實際操作中還會遇到的更為復雜的示例是,在處理並行 LINQ (PLINQ) 項目時遇到錯共享問題。PLINQ 是 一個與“LINQ 到對象”類似的 LINQ 提供程序,不同之處在於它會在計算機上的所有可用核之間分發查 詢計算工作。不必涉及過多細節,PLINQ 可利用一組枚舉器(實現 IEnumerator<T> 接口的類)來 表示並行計算。在迭代過程中,每個枚舉器都會遍歷輸入分區並計算相應的輸出。不同的枚舉器會由不同 的線程向前推動,從而將計算過程在多個線程間進行分配。如果可使用多核來調度線程,則很有可能會實 現並行加速。
事實證明,此情形容易受到錯誤共享的影響。我們有多個線程,每個都將讀取和修改其 自己的枚舉器上的字段。如果枚舉器的結束位置在內存中很接近 – 在常見的諸如創建枚舉器然後分發給 線程(如之前的 Random 示例)這樣的簡單實現中 – 錯誤共享會明顯抵消並行加速的效果。
避免內存的連續分配
.NET 內存分配器確實隱藏了內存布局的許多細節,但我們通常也能夠猜出該 布局的特定屬性,甚至確切知道它們的某些信息。我們假設下列事實成立:
同一類實例中的兩個實例 字段在內存位置中非常接近。
同一類型的兩個靜態字段在內存中非常接近。
數組中具有相鄰索引的 兩個元素在內存中也是相鄰的。
連續分配的對象在內存中很可能也是鄰近的,並且可能會隨著時間的 推移而更加接近。
在閉包中同時使用的局部變量很可能在實例字段中被捕獲,並且根據上面的第一條 注釋,它們很可能在內存中也是相鄰的。
在其他情況下,我們知道兩個內存位置可能是相距很遠的。 例如,不同線程所分配的對象很可能在內存中相隔很遠。
如果某個線程分配一個對象,然後分配很多 中型或大型對象,最後分配另一個對象,則第一個和最後一個對象之間的距離很可能等於分布其間的各對 象彼此之間的距離和。此行為並不確定,不過在實際中經常出現。(但是,如果中間對象過大,它們可能 會在不同的堆中終止,此時第一個和最後一個對象在內存中可能會很接近。)
如果兩個對象添加了總 大小至少等於緩存行大小的未用字段,則這兩個對象不會在同一緩存行結束。所添加的字段在內存中應最 後出現。如果我們知道了對象在內存中的出現順序,則可以只填充首先出現的字段。
根據這些假設, 我們可以設計出一個並行應用程序,並最大程度減少需要調試的錯誤共享問題的數量。
希望未來的編 程模型會將這些復雜的部分隱藏起來,不讓用戶看到。但是在近期,理解內存和緩存的工作原理對於編寫 高效的並行程序而言仍然十分重要。
請將您想詢問的問題和提出的意見發送至 [email protected]。