本文以 Visual Studio 工具的預發布版為基礎。文中的所有信息均有可能發生變更。
本文將介紹以下內容:
並行計算
並發編程
性能提高
本文使用了以下技術:
多線程
從 1986到 2002 年,微處理器的性能每年提高了 52%。這一驚人的技術進步源自晶體管成本依據摩爾 法則不斷地縮減,以及處理器廠商在工程方面的出色表現。微軟的研究員 Jim Larus 將上述兩種因素的 組合稱為“摩爾紅利”,他解釋了這一紅利如何造就了現代軟件業並使計算機得以廣泛普及(請參閱 go.microsoft.com/fwlink/?LinkId=124628)。
從軟件方面講,這一現象稱為“免費的午餐”—只需升級運行應用程序的硬件就能改進其性能。(有 關這方面的詳細信息,請參閱“面向軟件並發的基本轉變”,網址為 ddj.com/184405990。)
但如今的模式正在發生改變,處理器的增加使性能得到了改進。多核系統現在已是無處不在了。當然 ,只有軟件能同時執行多個任務,多核方式才能提高性能。如果想讓多處理器實現多處理器計算機所承諾 的性能提高,必須編寫可以使用順序技術出色完成任務的函數。
並發和並行
現在,程序員有時必須要考慮並行給編程所帶來的難題—並發。為了保證響應,需要有某種方式能從 輸入事件的處理線程卸載響應時間過長的活動。過去這類活動大部分涉及文件 I/O,但現在更多的是涉及 與 Web 服務的會話。
Microsoft .NET Framework 提供了異步編程模型和後台工作程序理念,以適應這一常用編程需要。雖 然在並行編程中平行編程的復雜性大部分相雷同,但基本模式和目標卻各異。多核處理器不會減少並發編 程需求,這種技術是用於優化後台活動和系統中的其它計算,目的是提高性能。
另一種常見的並發應用於服務器應用程序。Web 服務器這類應用程序會收到獨立請求形成的流。.這些 程序力求通過同時執行多項請求來改進系統的吞吐量,通常是對每個請求使用一個單獨的線程,但依次處 理每個請求。這種重疊可以增加每秒處理的請求數量,但對單個請求的延遲(每個請求所用的時間)並無 裨益。
這些應用程序也在享受免費午餐,並且由於多核處理在成本和吞吐量方面具備優勢,受益時間會更長 。但是,任何對延遲敏感的請求(即使是在服務器環境中)最終還是需要使用並行編程技術來取得適合的 性能。
並發編程對專家而言都是十分撓頭的。如果邏輯上獨立的請求共享多種資源(目錄、緩沖池、數據庫 連接等),程序員必須構建共享,這會帶來新的問題。這些問題(數據爭用、死鎖、活鎖等)通常是由各 種不確定性所造成的,當多項並發任務試圖操控程序中的同一對象時,就會出現這些不確定性。它們會為 測試和調試軟件帶來極大的困難,如 Rahul Patil 和 Boby George 近期在“識別並發問題的工具和方法 ”一文中所述。
並行編程與並發編程的區別在於您必須接受邏輯上的單一任務(可使用所有主要語言所支持的常用順 序結構表達)並為並發執行創造機會。(在本文後面的內容中,我將介紹實現這類機會的諸多途徑。)但 是,如果通過共享數據對象的子任務引入並發機會,必須要注意鎖定和爭用問題。因此,並行編程不但要 面對順序化程序所有的正確性和安全性難題,還要應對並行性和並發訪問共享資源所帶來的全部困難。
新的概念、新的失效模式和測試困難會讓每個開發人員均望而卻步。您確實真想領教一下它的厲害嗎 ?當然不是!但是,很多時候為了能有必要的性能又不得不如此。Microsoft 正在積極開發應對此類問題 的解決方案,但目前尚無效率很高的解決方案出台。
去年,Microsoft 發起了“平行計算管理計劃”(go.microsoft.com/fwlink/?LinkId=124050),該活 動不但是要探討如何構建並有效執行並行程序,而且旨在鼓勵創建新一代應用程序,能夠將“摩爾紅利” 轉化為客戶價值。我將很快研討一些並行性的思路。Stephen Toub 和 Hazim Shafi 在本期的文章“在下 一版本的 Visual Studio 中更好地支持並行性”介紹了一些我們用於支持這些方法的庫和工具。Joe Duffy 在本期的文章“解決多線程代碼中的 11 個可能的問題”中討論了改進並發應用程序安全的技術和 方法。
以前,我使用“並發執行機會”一詞進一步區分並行與並發編程。如開發人員使用異步編程模式或後 台工作程序,或者在服務器中處理並發請求,這裡會有一個例外,即所有不同的線程一律前行。操作系統 的任務計劃程序將確保每個線程均獲得公平的共享資源。但這一點對於並行編程並無幫助。如果您感興趣 的是編寫將用於新硬件系統的應用程序,它能發揮的作用就更為有限。
如果您想從免費午餐中受益,即通過硬件升級使軟件的性能更好,則需要讓更多現有的並行功能可以 在將來繼續發揮功效。在此,我將使用“任務”這一術語取代線程,來強調並行實施中的轉變以及我的思 路:鼓勵應對並行編程的開發人員將問題分解為更多的任務。
並行編程系統的實現應該能根據需要將這些任務映射給系統線程和處理器。只有為數不多的程序員發 現,從操作系統取得系統資源並在進程中進行管理以便有效執行並行程序的方式有了巨大的變化。它就象 一個線程池,但側重於將應用程序中的並行機會與當前硬件的可用資源相搭配,而不只是按並行程序員的 指令管理線程。
在並發編程中(尤其是服務器),大部分困難源自使用鎖等工具協調長時間運行線程對共享變量的訪 問。如轉為具備任務的並行編程,可以使用一個新概念。例如,在任務 A 後面運行一個任務 B,並提供 基本協調元素對其加以說明。這樣程序員就可以考慮為工作制訂計劃。通常,這一計劃會從本質上配合程 序的算法結構,並從並行編程抽象的結構化使用中反映出來。程序抽象與並行算法間的良好配合能極大地 減少對傳統並發機制的需求(如鎖和事件),並可避免許多並發編程的風險(但不能完全消除)。
接下來,我將說明一些並行編程的主要方法並通過正在開發的抽象展示其使用。我還會特別使用 C# 展示 C++ 並行模式庫 (PPL) 和 .NET 並行擴展(網址為 go.microsoft.com/fwlink/?LinkId=124621) 。
結構化多線程
人們處理問題時最常用的模式是先分割再解決:使用定義良好的交互將一個大問題分解為多個小問題 ,這些問題可單獨解決,然後將結果匯總,從而解決原始問題。無論是大型公司的風險,還是鄰居的日常 瑣事,它們都使用這一技術解決問題。由這一觀念帶動的應用程序也順理成章的成為了並行編程的基礎。
結構化多線程指提供並行模式的順序語句,它的塊呈結構化。例如,一條采用順序語法的復合語句 { A; B; },原本先求 A 的值,再求 B 的值,現在成為了一個並行語句,A 和 B 可以同時求值。但整個構 造並未完成,控制繼續轉到下一個構造,直到兩項子任務全部完成為止。這是一個舊概念,一直被視為 Cobegin 語句有時也稱為“派生-聯結並行性”以突出結構。相同的基本觀點也適用於循環,其中每個迭 代均定義一個任務,該任務與其他迭代同時計算。所有迭代均完成後,並行循環即告結束。
著名的 QuickSort 算法就是“分割-解決”這一概念的常見示例。在此我使用 C++ 構造展示一下此算 法的簡易並行化。基本算法選取一個數組,使用第一個元素做為基准值,將數據分為兩部分,更新數組以 便所有小於基准值的數值在前,大於基准值的數值在後。隨後遞歸應用這一步驟對數據排序。通常還會在 中間使用一些非遞歸算法(如插入排序)來減少開銷。
圖 1 展示了 Microsoft 正在開發的兩種功能。第一個是新的 C++ lambda 語法,它為將表達式或語 句列表捕獲為函數對象帶來了極大的便利。以下語法創建了一個函數對象,調用它時會計算兩個括號之間 的代碼。
[=] { ParQuickSort(data, mid); }
圖 1 快速排序
// C++ using the Parallel Pattern Library
template<class T>
void ParQuickSort(T * data, int length, T* scratch) {
if(length < Threshold) InsertionSort(data,length)
else {
int mid = ParPartition(data[0], data,
length, scratch, /*inplace*/true);
parallel_invoke(
[=] { ParQuickSort(data, mid); },
[=] { ParQuickSort(data+mid, length-mid); });
}
}
前面的 [=] 標記 lambda 並指示將所有未在表達式中引用的變量復制到對象中,在 lambda 主體中引 用這些變量的項目將會引用這些副本。
parallel_invoke 是一個模板算法,在本例中,它獲取兩個這樣的函數對象,將每個視為單獨的任務 加以計算,從而同時運行這些任務。完成兩項任務後(在本例中,是完成兩個遞歸排序), parallel_invoke 返回,然後完成排序。
注意:示例中的並發是遞歸應用“分割-解決”並發的結果。您在每一層級只有兩項子任務,計算結束 時您完成的任務數與排序數據的數量成正比。我已闡述了並發的所有內容,這類程序有可能發展為更大的 問題,或需要更多的內核。對於固定大小問題,現實中任何有開銷的機器都有可伸縮性限制。這是著名的 Amdahl 定律所產生的結果。平台供應商一個重要的工程目標就是不斷降低這些開銷,這意味著選擇象阈 值這樣的值會很困難(圖 1 中),隨後對系統變化進行預測可能會更為困難。它們需要大小適度,既不 讓您付出過多的開銷,同時還要保證不會限制將來的擴展。
Stephen Toub 和 Hazim Shafi 在本期講述的 PPL 中有這個模板算法。除了 parallel_invoke,還有 一個與 Standard Template Library's (STL) for_each 類似的 parallel_for_each。對於 parallel_for_each,其語法為每個迭代都是單獨的任務,與其他迭代任務同時運行,parallel_for_each 在所有任務完成後返回。一些弱結構化技術還會創建與常用任務組相關的單項任務,然後等候所有這些任 務完成。這會提供與 Cilk 生產基本元素 (supertech.csail.mit.edu/cilk) 相同的基本功能,但它以標 准 C++ 功能為構建基礎。
使用並行循環可處理射線跟蹤。每個輸出像素都需要些許並行度,與圖 2 中所示類似的代碼可存在這 一現象。它使用 .NET 並行擴展的 Parallel.For 方法進行表達,對於托管開發人員,它包含的基本模式 與 PPL 針對 C++ 開發人員所支持的模式相同。我在此使用一個簡單的嵌套循環來說明與矩形屏幕上每個 像素對應的任務空間。此代碼假定循環主體中調用的不同方法可以安全並發執行。
圖 2 並行循環
// C# using Parallel Extensions to the .NET Framework
public void RenderParallel(Scene scene, Int32[] rgb)
{
Parallel.For(0, screenHeight, y =>
{
Parallel.For (0, screenWidth, x =>
{
Color color = TraceRay(new Ray(camera.Pos,
GetPoint(x, y, scene.Camera)), scene, 0);
rgb[x + y*screenWidth] = color.ToInt32();
});
});
}
仍請參閱 Duffy 有關並發安全的文章。在並行編程的早期,開發人員將承擔這些責任。購者自慎,買 主當心。
對於正常的數據結構(可能是遞歸或不規則),並行性可以反映這種結構,因此結構化多線程最適合 與其搭配使用,即使在問題中出現一些數據流這一結論也成立。以下示例按拓撲邏輯順序遍歷一幅圖片, 因此我必須先看到所有前置任務,然後才能訪問節點。我在每個節點保留了一個計數字段,它初始化為前 置任務的數目。訪問節點後,我減少後續任務的計數(請確保此操作的安全,因為一次可能會有多項前置 任務嘗試這一操作)。計數變為零後,我就可以訪問該節點:
// C++
void topsort(Graph * g, void (*action)(Node*)) {
g->forall_nodes([=] (Node *n) {
n->count = n->num_predecessors();
n->root = (n->count == 0);
});
g->forall_nodes([=] (Node *n) {
if(n->root) visit(n, action);
});
}
我假定圖片導出一個由函數對象參數化的方法,它並行遍歷圖片中的所有節點並應用函數。該函數在 內部使用 PPL 實現這一並發。這樣您就有兩個階段:第一階段計算前置任務的數目並確定根節點,第二 階段從每個根項開始深度優先搜索,減少計數並最終訪問後續任務。該函數與圖 3 類似。
圖 3 深度優先搜索
// C++ using the Parallel Pattern Library
// Assumes all predecessors have been visited.
void visit(Node *n, void (*action)(Node*)) {
(*action)(n);
// assume n->successors is some kind of STL container
parallel_for_each(n->successors.begin(),
n->successors.end(),
[=](Node *s) {
if(atomic_decrement(s->count) == 0) // safely does "-- s->count"
visit(s, action);
});
}
parallel_for_each 遍歷後續任務的列表,對每項任務應用函數對象,然後允許並行完成這些操作。 假定的 atomic_decrement 函數未顯示,它使用判優並發訪問的某些策略。注意,在此您會開始在我們其 他的並行算法中看到更多傳統並發問題,隨著元素操作愈發復雜(如射線跟蹤示例),這些問題會更為惡 化。
此算法的結構保證讓操作獨占訪問其參數,這樣,如果操作更新這些字段,不需要額外的鎖定。此外 ,它們還會保證所有前置任務已更新,不會發生變動,且任何後續任務均未更新,在此操作完成前也不會 有改變。在構建正確的並行算法時,能夠推論哪是穩定狀態,哪種狀態可以並發更新至關重要。
結構化多線程的長處在於並行機會(包括那些部分排序計算面臨的機會)易於表達,無須在基本算法 中攙雜過多向工作程序線程映射作業的機制。這就提供了更為強大的復合模式,如此處所示,其數據結構 可提供某些基本並行遍歷方法(如 Graph::forall_nodes),可以重復使用它們構建更為復雜的並行算法 。此外,與只為兩個或四個處理器查找足夠的並行機制相比,說明所有的並行機制要容易得多。它不只是 更為便利,還為將來的八處理器機器提供了先天擴展機會。
數據並行性
數據並行性指對數據合計應用某些常用操作,以生成新的數據合計或將合計減為標量值。並行性源自 對獨立於周邊元素的每個元素執行相同的邏輯操作。對於合計操作,現在已經有多種語言能提供多層支持 ,但至今為止最為成功的是與數據庫搭配使用的 SQL。LINQ 在 C# 和 Visual Basic 中為 SQL 樣式的運 算符提供直接支持,使用 LINQ 表達的查詢可以傳遞給數據提供程序,如 ADO.NET,或者根據內存中的對 象集合(甚至 XML 文檔)進行計算。
.NET 並行擴展帶有 LINQ to Objects 和 LINQ to XML 實現,它包括查詢的並行計算。此實現稱為 PLINQ,可利用它輕松與數據合計配合使用。以下示例展示了統計群集標准 K 平均算法的內核:在每一步 驟中,您在空間會有 K 個點,它們是您的備選群集中心:將每個點映射到最近的群集,然後針對映射到 相同群集的所有點,通過平均群集中的點位重新計算該群集的中心。此過程繼續執行,直到達到聚合條件 ,即群集中心的位置穩定下來。此算法說明的中央循環可以相當直接地轉化為 PLINQ,如圖 4 所示。
圖 4 查找中心
// C# using PLINQ
var q = from p in points.AsParallel()
let center = nearestCenter(p, clusters)
// "index" of nearest cluster to p
group p by center into g
select new
{
index = g.Key,
count = g.Count(),
position = g.Aggregate(new Vector(0, 0, 0),
(accumulated, element) => accumulated + element,
(accumulated1, accumulated2) =>
accumulated1 + accumulated2,
(accumulated) => accumulated
) / g.Count()
};
var newclusters = q.ToList();
LINQ 和 PLINQ 的區別在於數據集合點的 AsParallel 方法。本例還顯示 LINQ 包含核心的 map/reduce 模式,但這一模式是明確集成到主流語言中的。本例中的另一精微之處是 Aggregate 運算符 的行為。第三個參數是一個委托,它提供了一種組合部分總和的機制。有了這個方法,就可以並行實現, 即將輸入合並成塊,並行減小每個塊,然後將各個結果組合起來。
如使用結構化多線程方法,數據結構假設會變得十分混亂,與此相比,數據並行中的算法表達得更為 清晰,可讀性也更好。此外,更加精煉的說明讓系統能有更大的機會進行優化,如果手工執行這種優化, 算法將會十分晦澀。最後,這種高級表示讓執行目標更為靈活:多核 CPU、GPU 或擴大為群集。只要葉函 數(如 nearestCenter)沒有副作用,在面向線程的編程中您就不會遇到任何數據爭用或死鎖問題。
並行性開發的常用技術是使用管道。在這一模型中,數據項在管道的各個階段之間流動,在向下一階 段傳送前要接受檢查和轉換。數據流的基理是:數據值在圖形的節點間流動,並根據輸入數據的可用性觸 發計算。通過並發執行各個節點和讓一個節點針對不同的輸入數據多次激活,以此實現並行。
.NET 並行擴展支持顯式創建單個任務(類型為 Task,實現結構化多任務的底層機制),然後確定在 第一項任務完成後開始執行的第二項任務。Future 這一概念在命令編程和數據流編程之間搭建起了橋梁 。它是計算最終生成的值的名稱。這種分隔使我能在了解值之前定義它的操作。
Future 的 continueWith 方法由委托加以參數化,它將用於創建在 Future 值可用時執行的任務。調 用 continueWith 會生成一個新 Future,它會確定委托參數的結果。在命令編程中,常會因副作用計算 任務,因此 continueWith 也可做為 Task 的方法使用。
Strassen 矩陣乘法算法中的並行性就是這一類型的一個示例。它是基本矩陣乘法算法面向塊的版本。 兩個輸入矩陣均被分為四個子塊,然後用代數方法將其合並,形成輸出矩陣的子塊。(有關詳細信息,請 參閱 Wikipedia 就 Strassen 算法撰寫的文章,網址為 wikipedia.org/wiki/Strassen_algorithm。)
其中一項任務可能如下所示:
// C# using Parallel Extensions to the .NET Framework var m1 = Future.StartNew(() => (A(1,1)+B(1,1))*(A(2,2)+B(2,2));
為清晰起見,我在委托中使用數學符號而不是代碼來表達計算。A 和 B 是輸入矩陣,A(1,1) 是 A 矩 陣左上方的子塊。添加項是矩陣的標准,乘法是 Strassen 算法的遞歸應用。輸出是與此表達式結果相對 應的臨時矩陣。
前七項子任務是獨立的,但後四項子任務以前七項為輸入。基本數據流圖應如圖 5 所示。其中,標為 c11 的任務依賴於 m2 和 m3 的結果。我想讓該任務在其輸入可用時能夠執行。在 C# 中可以使用如下代 碼表達:
var c11 = Task.ContinueWhenAll(delegate { ... }, m2, m3);
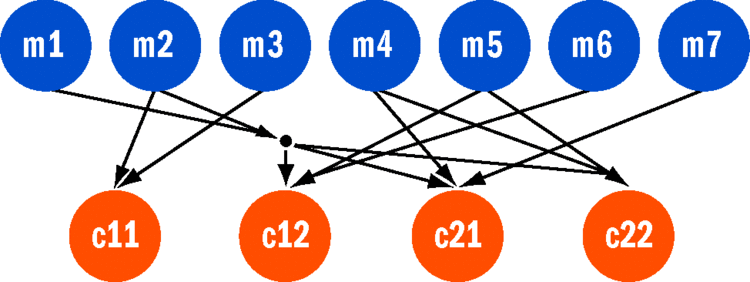
圖 5 子任務
它展示了所謂的中等粒度數據流,其計算量為幾百到幾千個操作,與之相比,精細粒度數據流中的每 個操作可以是單一算術操作。用於處理“如果全部”和“如果任何”這兩種概念的幾種便利方法可以更清 晰地表述這一點,但如 Stephen Toub 所述,它們是在基本機制之上實現的(請參閱 blogs.msdn.com/pfxteam/archive/2008/07/23/8768673.aspx)。
至於結構化多線程,我已指出了其並行機會,如果您只有一個處理器,那麼完全可以按子任務的創建 順序依次執行。但如果有其他資源,您就有機會通過捕捉子任務中的執行順序約束來從中受益。與結構化 多線程不同,您可以方便地允許一項任務枚舉數據流圖並對單個子任務隱藏其結果的使用和組合方式,這 一點不同於常用的並行算法處理機制。
數據經常要流入應用程序,我想在其流過時對其加以處理。在這種情況下,數據遍歷的路徑相當穩定 。我將任務與下一數據項的可用性關聯起來,而不是關聯其他任務的完成狀況。在機器人技術中,算法決 策要依靠以不同速率到達的多種傳感器數據流,此時這一模型的價值尤為突出。
Microsoft Robotics SDK (go.microsoft.com/fwlink/?LinkId=124622) 就采用了這一方式,其中心 概念涉及數據流(端口)和由數據到達(信息)激活的任務綁定。當然,我現在提到的這問題不是由向多 核轉換造成的,而是(如 Web 服務器)以並發為主要特征,必須視為應用程序整個體系結構的一部分加 以解決。類似的問題也適用非機器人技術領域的分布式應用程序,但那超出了本文所討論的范疇。
流式並行性
除了多核,計算機體系結構的另一個重要特征就是內存的多層次分層結構。寄存器、一或多級板上緩 存、DRAM 內存以及按需分頁磁盤。大多數程序員不熟悉(或至少是不關心)系統體系結構的這一領域, 但他們對此並無懊悔之意。因為他們的程序很小,緩存就足以容納這些程序,並且向緩存返回對內存的引 用相當快。但是,如果數據值不在板上緩存中,那就需要數以百計的循環才能從 DRAM 取得數據。提供此 類數據的延遲讓人感覺程序運行得很慢,因為處理器花費了大量時間等待數據。
有些處理器的體系結構支持一個物理處理內核有多個邏輯處理器。這通常稱為(硬件)多線程,在主 流處理器中已經有了少量應用(例如,Intel 已在它的某些產品中將這稱為超線程)。多線程的動機是允 許內存訪問延遲,一個邏輯硬件線程在等候內存時,可以從其他硬件線程發出指令。此技術也用在現代 GPU 中,但其來勢要更猛。
隨著處理內核數量的增加,向內存系統發出的請求數也在增加,這樣又出現了一個新問題:帶寬限制 。處理器每秒從 DRAM 內存傳入/傳出操作的數量有一定限制。一旦達到上限,就無法繼續利用並行取得 增益;更多的線程只會產生更多的內存請求,造成請求排隊,等候內存控制器的處理。GPU 通常有內存子 系統,支持更高的聚合帶寬(以每秒 GB 字節計),這樣就能支持(或預期)更多的並行性,並從額外的 帶寬中受益。
就當前的多核芯片體系結構而言,其內核數量的增加速度比內存帶寬提高的速度要快,因此對於大部 分數據集與內存搭配問題,使用內存分層結構是一種倍受關注的方案。這種不平衡導致了流處理編程的產 生,它側重於將數據塊放入板上緩存(或私有內存),然後在下一數據塊替換它之前對其執行盡可能多的 操作。這些操作可能在內部並行使用多個內核,或以數據流的形式送入管道內,但其重點是在數據位於緩 存時對其執行盡可能多的操作。
人們已經期望有專用語言能允許指定流算法並仔細規劃其執行,在許多情況下,也可以通過仔細規劃 時間達到這一目標。例如,您可以將些技術應用於 QuickSort 示例。如果您排序的數據集太大,緩存中 容納不下,最直接的省力方法是將最大的子問題規劃給各個內核,這些內核隨後會處理單獨的各個數據集 ,但共享板上緩存的益處不復存在。
不過,如果您修改算法,使其只對緩存中的數據集使用並行,則可以從流中受益,如圖 6 所示。在本 例中,您仍是將大問題分解為小問題(並在分區步驟中使用並行性),但如果兩個子問題不能同時放入緩 存,我們可以依次處理它們。這意味著一旦您在緩存中得到小數據集,您可以在其處於緩存中時使用所有 可用資源完成對其的完全排序,而不必在您啟動下一數據集前將其放入內存。
圖 6 對小型數據集使用並行
// C++ using the Parallel Pattern Library
template<class T>
void ParQuickSort(T * data, int length, T* scratch, int cache_size) {
if(length < Threshold) InsertionSort(data,length)
else {
int mid = ParPartition(data[0], data,
length, scratch, /*inplace*/true);
if(sizeof(*data)*length < cache_size)
parallel_invoke(
[=]{ ParQuickSort(data, mid, cache_size); },
[=]{ ParQuickSort(data+mid, length-mid, cache_size);});
else {
ParQuickSort(data, mid, cache_size);
ParQuickSort(data+mid, length-mid, cache_size);
}
}
}
注意:您必須顯式用緩存的大小參數化此代碼,這是特定於實現的特征。如果此計算與其他作業或相 同作業中的其他任務共享系統,這會不盡人意,並可能成為問題。但它指出了從復雜並行系統中取得性能 所面臨的一個難題。不是所有的問題都有這一症狀,但要想多核芯片發揮良好性能,要求開發人員在某些 情況下認真考慮並行交互和內存分層結構。
單程序,多數據
通過二十世紀八十年代的一系列努力,在高性能計算的舞台上,並行性已在技術與科學應用程序中使 用了一段時間。這類問題由對數組實施的並行循環主導,循環的主體通常有一個相當簡單的代碼結構。
更早的射線跟蹤片段就是一個例子。當時出現的主流並行性模型稱為“單程序,多數據”,通常簡稱 為 SPMD。這一術語暗指計算機體系結構典型的 Michael Flynn 分類法,它包含單指令、多數據 (SIMD) 和多指令、多數據 (MIMD)。在此模型中,程序員將每個處理器(工作程序、線程)的行為視為一組處理 器,它們從邏輯上講參與一個問題,但共享作業。作業通常是循環的單獨迭代,它們使用數組的不同部件 。
SPMD 中共享作業的概念彰顯於 OpenMP (openmp.org) 對 C、C++ 和 Fortran 擴展組的核心。並行區 域是此處一個主要概念,在該區域中,單一活動線程並入線程團隊,然後共同執行共享循環。使用屏障同 步機制來協調此團隊,以便整個團隊作為一個組從一個循環單位移至下一個循環單位,確保在團隊成員完 成計算後才能讀取數據值。在區域末端,團隊匯合在一起,原始單一線程繼續工作,直到下一並行區域。
這種並行編程還用於非共享內存系統,在這類系統中,使用構建於信息傳遞基礎上的內節點通信將周 圍的數據復制到階段邊界適宜的位置。這一技術可應用數以千計的處理器節點,從而獲得極高的性能,解 決天氣建模和醫藥設計等問題。
與結構化多線程中類似,OpenMP 並行區域可位於函數內部,這樣,該函數的調用方就無須了解實現中 並行性的使用情況。但 SPMD 模型需要認真考量問題作業如何向團隊中的工作程序做映射。
如果一個工作程序的任務時間比它的團隊成員要長,就會產生負載不均衡,這暗示著其他團隊成員可 能要閒置等待該工作程序完成任務。在與其他作業共享系統資源的環境中,也會出現類似情況,如果 OS 中斷工作程序,令其執行其他任務,這一人為不均衡會對其他工作程序產生影響。
未來的硬件系統可能有多種不同的處理器內核—耗能大但單線程運行快的大型內核,還有耗能小的小 型內核,它們經優化後用於並行操作。這類環境對於 SPMD 模型而言是個大難題,因為它使得將作業映射 給工作程序變得極為復雜。結構化多線程方法可以很好地避免這些問題,但代價是要略微增加一些規劃開 銷,並可能損失對 OpenMP 托管代碼的內存分層結構控制。
並發數據結構
前面的討論幾乎完全集中在控件並行性上—如何確定並說明單獨的任務,這些任務可映射給多個可用 內核。數據端與並行性也有關聯。如果任務是為更新數據結構,例如將值插入 Hashtable,該操作從邏輯 上可以獨立於並發執行任務。
數據結構的標准實現不支持並發訪問,它可能分解為多種模糊、不可預見且難以重現的方式。只是對 整個數據結構加一道鎖可能會在所有任務均串行化的程序中造成瓶頸,因並發使用的數據位置過少導致失 去並行性。
因此,除了並行控件抽象,還必須要創建新的並發版本通用數據結構—Hashtable、堆棧、隊列和各種 數據集表現形式。這些版本已定義了受支持方法(可並發調用)的語法,它們設計為可避免在多項任務訪 問時出現瓶頸。
例如,並行查找圖形連接元件的標准方法。基本策略是對圖形啟動一組深度優先遍歷,找出相交節點 ,然後形成簡化圖形。頂層函數的基本結構如圖 7 中所示。
圖 7 深度優先遍歷
// C++
// assign to each Node::component a representative node in
// the connected component containing that node
void components(Graph * g) {
g->forall_nodes([=] (Node * n) {
n->component = UNASSIGNED;
});
Roots roots;
EdgeTable edges;
g->forall_nodes([&roots, &edges] (Node * n) {
if(atomic_claim(n, n)) {
roots.add(n);
component_search(n,n, &edges);
}
});
// recusively combine reduced graph (roots, edges)
...
}
我們通過讓每個節點指向代表性元素來隱式表示元件。輸入是一幅圖形,我假定它支持 forall_nodes 方法,可使用該方法和結構化多線程技術遍歷圖形。經函數對象參數化後將其用於每個節點。這一接口將 並行算法與圖形的結構細節隔離,但保留了結構化多線程的主要屬性,並發出現在方法內部,可以高度結 構化。
首先,將元件字段初始化為特殊值,然後啟動(邏輯上從每個節點)並行深度優先搜索。每個搜索都 先聲明起始節點。由於其他搜索也可以到達節點,此聲明基本上是自動測試,用於確定哪個搜索最先到達 。該函數類似如下所示:
// C++
// atomically set n->commponent to component if it is UNASSIGNED
// return true if and only this transition was made.
bool atomic_claim(Node * n, Node * component) {
n->lock();
Node * c = n->component;
if(c == UNASSINGED) n->component = n;
n->unlock();
return c == UNASSIGNED;
}
我已假設每個節點一個鎖,但在這個簡單示例中,我可能使用 Windows 基元來執行指針值的內鎖比較 和互換。這裡的主要問題是:防止多項任務並發訪問的單一全局鎖會清除數據並行性(即使我有很多控件 並行),這會造成我們的並行嘗試受阻。
您不一定每個節點都需要一把鎖。可以節點映射給鎖的一個小組,但必須小心因使用與目前處理器計 數相關的具體值而產生伸縮瓶頸。根本無須使用明確的鎖,Jim Larus 對使用“事務性內存”的研究旨在 讓開發人員只需聲明應從並發執行代碼隔離的代碼間隔,其中的實現視需要引入鎖定,以確保這些語法發 揮作用。
一旦您已確定新的根元件,將其加入共享數據結構的根項中。從邏輯上講,這是一組在算法第一步中 找到的所有根元件。此容器邏輯上僅有一個實例,您需要為並發添加項優化它的實現。做為 PPL 和 .NET 並行擴展所包含的內容,Microsoft 將提供向量、隊列和 Hashtable 的適宜實現,用於構建塊。
一個 節點的深度優先搜索在相鄰節點進行迭代,試圖在其元件內聲明每個節點。如成功,則遞歸進入該節點( 請參閱圖 8)。
圖 8 遞歸搜索
// C++ using the Parallel Pattern Library
// a depth first search from "n" through currently
// unassigned nodes which are
// set to refer to "component". Record inter-component edges in "edges"
void component_search(Node * n, Node * component, EdgeTable * edges) {
parallel_for_each(n->adjacents.begin(),
n->adjacents.end(),
[=] (Node * adj) {
if(atomic_claim(adj, component)
component_search(adj, component, edges);
else if(adj->component != component) {
edges->insert(adj->component, component);
}
});
}
如果聲明失敗,則意味著這個或其他任務先到達了這一節點,您應查看是否已將其加入別的元件。如 果是,將兩個元件記入共享的數據結構(EdgeTable)。該表使用並發 Hashtable 創建以避免信息重復。 這仍是一個邏輯上共享的數據結構,您必須確保對並發訪問有足夠支持,以避免爭奪或丟失有效並行。
這兩種結構、根項和邊緣項形成了邏輯圖形,它記錄初始元件估計值之間的連接。要完成算法,在此邏輯 圖形上找到已連接的元件,然後用最終的表示項(未顯示)更新該節點級信息。
總結
與並行編程相關的性能問題有很多,數據並發性的丟失只是其中之一。如果您初次試用這一技術時, 遇到莫明其妙地中斷(例如,因為忘記使用鎖)或實際速度比順序執行慢(任務過小、過多鎖定、緩存無 效、內存帶寬不足、數據連接等)。
隨著 Microsoft 在並行編程方面的不斷投入,抽象將會穩步得到改進,並會有工具幫助診斷和避免相 關問題。當然,您也可以期望硬件本身實現改進,加入各項功能以降低各種成本,但這需要時間。
並行轉變是軟件業面臨的一個轉折點,必須要采用新的技術。對於應用程序中那些目前對時間敏感的 內容,或預期將來會運行更大數據集的內容,開發人員必須要引入並行性。我已經說明了在應用程序中思 考和使用並行性的幾種不同的方式,並用 Microsoft 開發的新工具(大型“平行計算管理計劃”的一部 分)對其進行了演示。
深入分析:進軍下一個 100X
自 1975 起,微處理器的性能每 10 年提高 100X,這得益於時鐘頻率 (3,000X) 和晶體管數目 (300,000X) 的指數級增長。指令的力量提高了 8X-100X—8 位 ADD 與 SSE4.1 DPPS“打包-4-SP-浮點矢 量的點積”相比較—板上緩存現在的容量已趕上了早期的硬盤。做為一個行業,每個 100X 增長都為我們 帶來了新的驚喜。它為我們提供了巨大的動力。
但是,下一個 100X 增長的途徑會有所不同。按照“摩爾紅利規則”,我們仍可以期望每兩年看到每 個電路單位上晶體管數的另外四次倍增(32、22、16、11 納米的結點)。但我們發現我們已進入了幾條 增長曲線的下降點,特別是電壓調整和功耗(功率壁壘)、指令級並行性(復雜性壁壘)和內存延遲(內 存壁壘)。
功率壁壘微處理器的動態功率與 NCV2f 成正比,即晶體管開關的數量 × 開關電容 × 電壓的平方 × 頻率。隨著光刻結點的不斷減小,每電路單位的晶體管數量可能加倍 (↑N),晶體管會越來越小 (↓ C) 並使用更低的電壓開關 (↓V)。現在,供電電壓已從 15V 降至 1V,開關能量降低了 100X 還多。遺 憾的是,CMOS 最低阈值電壓是 0.7 V,所以我們最多還能期待 (1.0/0.7)2=2X 的節余。盡管有這些節余 ,但隨著我們加大了微處理器的復雜性 (↑N) 並提高了其頻率 (↑f),幾平方厘米的硅所產生的電路單 元功耗已從 1 W 增至 100 W,已達到了目前所用冷卻方案的極限。剩下的余地已經很少了,功率的發展 已進入零和游戲階段。時鐘頻率將不會再向從前一樣加快。不會再有另一個 100X 在此出現。
復雜性壁壘高性能微處理器使用出色的無序執行在線程內開拓指令級並行。不過,要從此方法取得更 大的收益,存在實際的局限性。串行代碼本身及其數據依賴性對可挖掘的並行性有所限制。在硬件中,您 有時最多要用 N2 或更多的線路才能完成 N 次並行操作。前沿設計和確認成本也隨之按比例增長。最重 要的是,假定出現並行軟件,功率壁壘決定了更為節省能源的微體系結構是更好的選擇—成果/焦耳要強 過成果/毫微秒。
內存延遲 DRAM 訪問延遲(遲滯)的改進相對較慢,因此 CPU 使用緩存完全避開 DRAM。但緩存是昂 貴的選擇—如今完全緩存缺失會占用 300 個時鐘周期。經驗法則是通過將緩存增大四倍來等分缺失率。 CPU 內核的復雜性主要集中於承受長時間不可預測的內存訪問。但是,擴大內存帶寬要更容易一些。您可 隨後應用內存級並行性—並行軟件線程同時發出多個並發內存訪問。每個線程可能仍需要等候很長時間才 能訪問,但並行計算的整體產能相當高。
串行處理器的性能在今後十年將會繼續提高,但步伐甚緩。聰明的 CPU 設計人員和編譯器編寫人員仍 能找出一些方法,四處收羅出 5% 或 10% 的性能改進。這是個不錯的結果,因為許多很有價值的軟件具 備串行特征,並受 Amdahl 定律支配。但它仍無法提供我們期望的 100X。它要求軟件開發並行性。如果 有極為出色的軟件出現,處理器供應商就能做好准備,提供具有數十個內核和高帶寬內存解決方案的並行 處理器。它們會應我們的要求進行構建。
—Jan Gray,Microsoft 並行計算平台構建團隊的軟件架構師
David Callahan 是 Visual Studio 並行計算團隊的著名工程師和首席架構師。加入 Microsoft 之前 ,他就職於超級計算機制造公司 Cray Inc,具備並行化編譯器和並行算法、體系結構和語言方面的背景 。