本文討論:
語音響應應用程序基礎知識
創建語音響應工作流
提示、關鍵字和語 法
處理用戶響應
本文使用了以下技術:
Speech Server 2007,.NET Framework
嵌入式存在、即時消息 (IM)、音頻和視頻會議以及電話均在 Microsoft® Office Communications Server (OCS) 2007 所提供的統一通信功能之列。開發人員可以構建一組 OCS API 以將 這些功能及其他功能包括到他們自己的應用程序中。但是,OCS 2007 新增了一項您可能還未聽過的以開 發人員為中心的功能—基於 Microsoft Speech Server 平台的交互式語音響應 (IVR) 工作流。
不太確定 IVR 是什麼嗎?如果您曾呼叫某個公司並聽到類似“銷售部請按 1,客戶服務部請按 2”的消息,則您已遇到過 IVR 系統。
語音應用程序基礎知識
Microsoft Speech Server 2004 僅支持通過語音應用標記語言 (Speech Application Language Tag, SALT) API 實現的 IVR 開發。新版本 OCS 2007 Speech Server(簡稱 Speech Server 2007)不僅支持 SALT 和 VoiceXML ,而且還引入了一個 Microsoft .NET Framework API 供創建 IVR 應用程序。Speech Server 2007 還包 括一個基於 Windows® Workflow Foundation (Windows WF) 的可視 IVR 應用程序設計器,名為 “Voice Response Workflow Designer”(語音響應工作流設計器)。
當前的 IVR 開 發標准(如 SALT 和 VoiceXML)主要使用依賴於 XML 標記和 JavaScript 並基於 Web 的開發模型。這 兩個標准都注重於提供 IVR 應用程序的用戶界面。然而,任何重要的 IVR 應用程序仍需執行象訪問數據 庫中的數據這類任務。對於這些任務,仍需要服務器端代碼(通常采用與 .NET 兼容的語言或 Java 來開 發)。同時,這略微消弱了 SALT 和 VoiceXML 旨在提供的主要優勢:IVR 應用程序的跨平台兼容性。
從開發人員角度而言,將 .NET Framework 用作 IVR 應用程序開發的基礎具有勝過 SALT 或 VoiceXML 的重大優勢,主要優勢是能夠使用面向對象的編程語言而不是 XML 標記。從企業角度而言,基 於 .NET Framework 的 IVR 可重復使用現有的企業和數據訪問邏輯,從而使企業可以利用其己在 Microsoft 技術方面所做的投資。
另一優勢是尋找關鍵資源。嘗試要求人事經理或招聘人員尋找 使用 VoiceXML 的開發人員和使用 .NET 的開發人員。您認為他們會先找到哪種開發人員?使用 .NET 的 開發人員顯然更多。
語音響應工作流
與 ASP.NET 頁面非常相似,語音響應工作流的邏輯 由兩個文件中的部分類組成;其中一個文件包含 Visual Studio® 生成的代碼,另一個文件包含您的 代碼(稱為 code-beside)。語音響應工作流使用“語音對話”活動和標准的 Windows WF 活 動。Visual Studio 工具箱包含這兩個活動類型。
開發 IVR 應用程序的第一步是布置呼叫流。在 Visual Studio 中,實現此操作的方式是將“語音工作流”活動拖動到“Speech Workflow”(語音工作流)畫布上,並按照您希望執行活動的順序來排列它們(如圖 1 所示)。
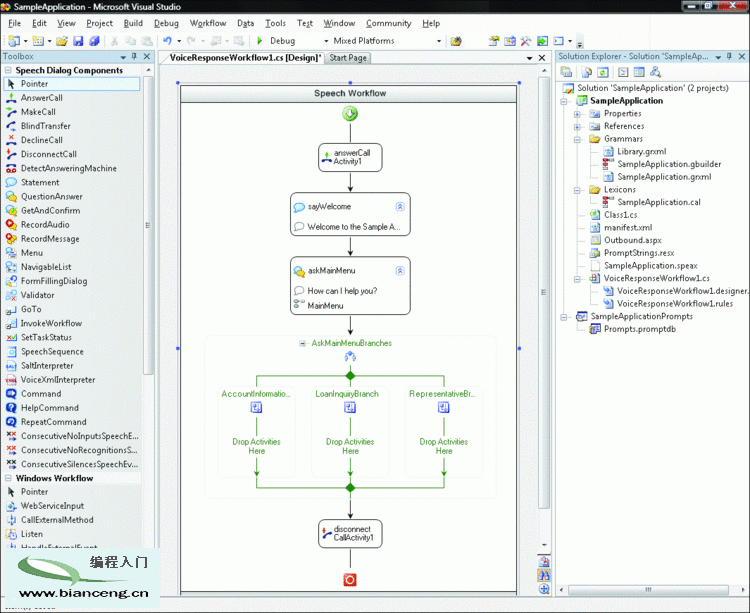
Figure 1 Voice Response Workflow Designer
對於響應入站呼叫的 IVR 應用程序,第一個活動通常是 AnswerCall,最後一個活動通常是 DisconnectCall。因此,這些活動會在創建新的“語音響應工作流”時自動添加至 “Speech Workflow”(語音工作流)。默認情況下,語音活動按從上到下的順序執行。盡管 “語音響應工作流”應用程序以 Windows WF 為基礎,但它們僅支持順序工作流,不支持狀態 機工作流。
兩個最常用的活動是 Statement 和 QuestionAnswer。僅使用這兩個活動即可輕松地 開發出相當簡單的 IVR 應用程序。這兩個活動均使用文本到語音 (TTS) 或預先錄制的提示來對用戶說話 。QuestionAnswer 活動與 Statement 活動有所不同,Statement 活動僅可對用戶說話,而 QuestionAnswer 活動讓用戶通過語音識別或按鍵音(雙音多頻或 DTMF)按鍵操作來提供響應。
構建提示
通過 TTS 或預先錄制的提示向用戶提供信息的每個活動均有一個名為 MainPrompt 的屬性,其類型為 PromptBuilder。MainPrompt 定義在首次執行活動時向用戶所說的內容。 PromptBuilder 類型提供了多種方法來微調提示的發聲方式。三種最常用的方法是 SetText、 ClearContent 和 AppendText。下面是使用 SetText 創建消息 "Thank you for calling." 的示例:
this.statementActivity.MainPrompt.SetText("Thank you for
calling.");
以下兩行使用 ClearContent 和 AppendText 來發送相同的 "Thank you for calling." 消息:
this.statementActivity.MainPrompt.ClearContent();
this.statementActivity.MainPrompt.AppendText("Thank you for calling.");
這 兩個代碼段實現的是同一目標,因此任選其一即可。我的一般做法是,如果一行代碼包含 ClearContent ,其後緊跟 AppendText 方法,則使用 SetText 方法來替換它,原因很簡單:一行代碼比兩行代碼更易 於維護。
在 Statement 活動中(請參見圖 2),有標准的一組事件,每次顯示提示時都會觸發這 些事件。在任一此類事件中設置靜態提示會導致應用程序在每次顯示提示時均寫入相同的提示值。
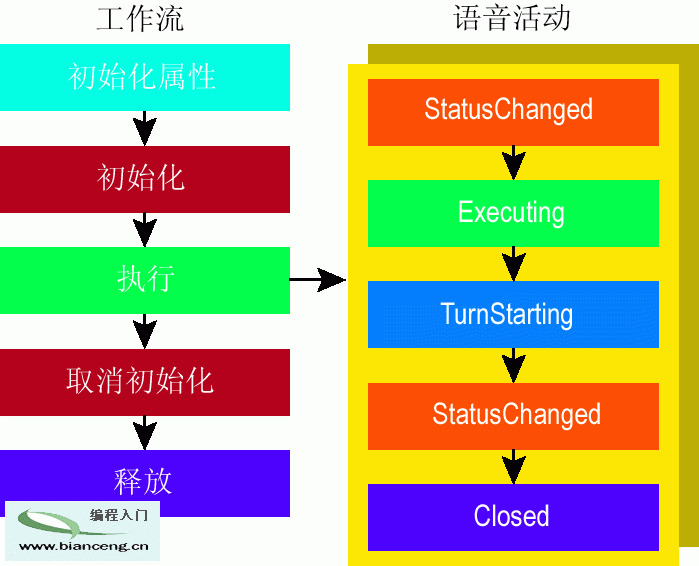
Figure 2 Statement Activity Order of Event Execution
在初始化活動之前(如在工作流而非活動的 Initialize 事件中)設置靜態提示將更為有效。如果提 示取決於某種類型的動態值,則在初始化活動之前設置該值仍然更為有效。實際上,設置靜態提示的最有 效方法是使用 Visual Studio 工具,它們將提示文本放到一個資源文件中,該文件僅在工作流的構造函 數調用 InitializeComponent 方法時加載一次。
至於動態提示,當您查看不僅對用戶說話而且查 找用戶輸入的活動時,情況即有所不同。一個不錯的示例是 QuestionAnswer 活動。在 QuestionAnswer 遵循同一執行順序的同時,它還接受用戶輸入。這意味著,如果用戶指出系統無法識別的內容,則會重新 觸發 TurnStarting 事件。這一方法效率很低,因為您將再次設置相同的動態提示以及重復使用動態資源 (如數據庫查找)。如果必須在活動執行時設置動態提示,則在 Executing 事件而非 TurnStarting 事 件期間設置它。這是因為,每個會話僅觸發一次 Executing 事件,而 TurnStarting 事件在每次呈現 QuestionAnswer 活動時均會觸發。
實際所說的文本取決於已向用戶播放活動的次數以及他們所提 供的響應類型。可通過為相應的提示類型指派希望敘說的話語來定義給定時間點的說話內容。
QuestionAnswer 活動比 Statement 活動多四個提示類型:Silence、Escalated Silence、No Recognition 和 Escalated No Recognition。盡管 MainPrompt 為強制設置項,但這些提示可選。當用 戶在 InitialTimeout 屬性所指定的時間之前未提供任何響應時,向用戶說出 Silence 提示。如果用戶 仍未提供響應,則播放 Escalated Silence 提示。No Recognition 和 Escalated No Recognition 提示 遵循與 Silence 和 Escalated Silence 提示相同的規則,但它們在用戶提供應用程序無法識別的響應時 使用。
在將文本資源轉換成口語時,動態提示會產生某些問題,其中最常見的兩個問題是日期和 時間。典型數據源以可讀格式(如 01/01/2008)存儲日期。但是,在播報時,您希望聽到的是“二 零零八年一月一日”。用於將此普遍理解的日期格式轉換成普遍理解的口語格式的解決方案是 AppendTextWithHint 方法。此方法接受與 AppendText 相同的字符串參數,同時還采用 SayAs 參數。 SayAs 參數是一個簡單的 Enum,其中包含用於將可讀文本轉換成口語文本的不同選項。在轉換日期的示 例中,代碼可能如下所示:
this.statementActivity.MainPrompt.AppendTextWithHint( "01/01/2008", Microsoft.SpeechServer.Synthesis.SayAs.Date);
預先錄制的 提示
默認情況下,語音響應工作流將使用 TTS 引擎的語音來閱讀提示中所定義的文本。但是,使 用 TTS 引擎需要許多處理功能,並且最終聽起來與使用 TTS 的所有其他系統相似。
還有一個選 項是使用預先錄制的提示。盡管可通過編碼提示來播放 WAV 文件(而不是指派文本),但只向解決方案 添加一個提示數據庫項目會更好。通過使用提示數據庫,您可以輕松地創建、編輯和管理應用程序中所使 用的 WAV 文件,並以壓縮格式存儲它們。此壓縮格式使提示的加載速度更快。如果使用提示數據庫,則 不必對應用程序的提示做任何編碼更改。
在提示數據庫中導入或創建 WAV 文件時,可指定 WAV 文件的錄音。當應用程序遇到要說的文本時, 它會在提示數據中查找匹配的錄音字段。例如,如果應用程序需要說 "Thank you for calling." 並且提示數據庫中存在 "Thank you for calling." 這段錄音,則它會播放 關聯的 WAV 文件,而非使用 TTS 再現文本。
如果應用程序包含大量提示,則創建和導入這些 WAV 文件的過程可能會非常枯燥乏味。讓我們看一看下面的提示:
"I'll transfer you to a representative."(我將為您轉接代表。)
"I'll transfer you to a loan officer."(我將為您轉接貸款主任。)
"A representative will be with your shortly."(立即為您接通代表。)
"A loan officer will be with you shortly."(立即為您接通貸款主任。)
除了創建四個不同的預先錄制提示,您還可以使用 提取技術。提取可將一個 WAV 文件中的整個或部分語句與另一 WAV 文件中的整個或部分語句合並。提取 不會自動發生;您必須在錄音字段中指定錄音的哪個部分可以使用提取。因此,只需具有帶提取方括號的 兩個 WAV 文件即可(如圖 3 所示),而不必在提示數據庫中包含四個不同的 WAV 文件。
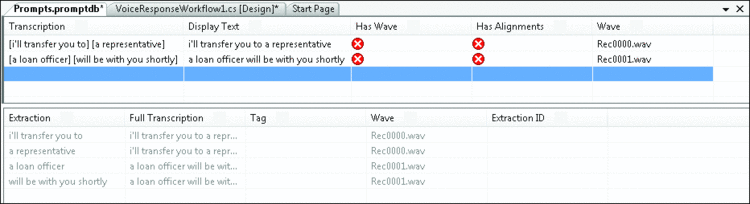
Figure 3 Prompts with Extraction Annotated
當應用程序遇到語句 "I'll transfer you to a"(我將為您轉接)時,它會自動將此 特定音頻部分與另一音頻部分合並。如果所遇到提示的有一部分在提示數據庫中找不到,它甚至可將預先 錄制的提示與 TTS 相混合。因此,如果您稍後添加另一提示 "I'll transfer you to a mortgage specialist"(我將為您轉接房貸經紀人),則語句 "I'll transfer you to a"(我將為您轉接)將使用 WAV 文件,而“mortgage specialist”(房貸經紀人)語 句可使用 TTS 引擎來呈現。
關鍵字和會話語法
既然應用程序可以進行交談,您就會希望 它能夠通過語音識別或 DTMF 來接受用戶響應。Speech Server 2007 不會自動識別用戶所說的全部內容 ,因此必須指定可接受的用戶響應。它們是在應用程序的語法中定義的。在語音識別應用程序中,有兩種 類型的語法:關鍵字和會話。關鍵字語法以在響應中使用特定詞語為基礎。關鍵字語法很適合於向用戶詢 問非常直接的問題,如 "Do you want Account Information, Loan Inquiry, or to speak with a representative?"(您需要帳戶信息、貸款查詢還是與代表通話?)。
如果用戶所講的內容 不在可接受回答列表之內,則即使用戶的響應非常類似於應用程序正在尋找的內容,應用程序仍可能會做 出類似下面的回答:"I didn't understand what you said. Please say ..."(我不太 理解您的意思。請說...)
另一方面,會話語法嘗試通過減少用戶的一些責任,轉為讓應用程序確 定用戶的意圖來解決此問題。不向用戶詢問直接問題,而是詢問一個開放性問題:"How can I help you?"(有什麼可以幫忙的嗎?)
它是一個更自然的詢問問題的方法,您可能會從用戶那裡 得到一個更加自然且復雜的答案。“會話語法構建器”使您可以輕松地構建會話語法,從而大 大減少處理統計語言模型的工作量。
它(如圖 4 所示)分為兩個部分:“Keywords” (關鍵字)和“Answers”(答案)。在“Answers”(答案)部分中,您具有三個 選項:“Concept Answer”(概念答案)、“Keyword Answer”(關鍵字答案)和 “Command”(命令)。“Concept Answer”(概念答案)與“Keyword Answer”(關鍵字答案)的不同之處在於:“Keyword Answer”(關鍵字答案)需要呼 叫方說出觸發識別的具體語句,而“Concept Answer”(概念答案)允許用戶提供與預定義的 “Answers”(答案)語句之一類似的響應。
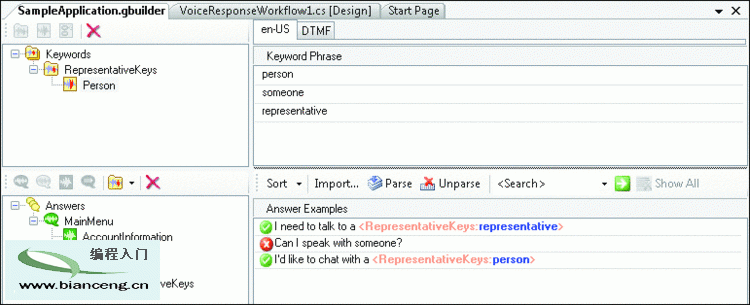
Figure 4 Conversational Grammar Builder
您可能希望為本示例的主菜單提示添加一個 “Concept Answer”(概念答案)(請參見圖 4)。“Concept Answer”(概念答 案)通常代表要求用戶提供響應的一個問題,在本示例中為主菜單問題 "How can I help you? "(有什麼可以幫忙的嗎?)
接下來,您需要針對應用程序允許該提示使用的每個可能選項,將一個概念添加至“Concept Answer ”(概念答案)。對於之前創建的主菜單 QuestionAnswer 活動,我將擁有一個名為 MainMenu 的 “Concept Answer”(概念答案),以及名為 AccountInformation、LoanInquiry 和 Representative 的三個概念。
現在考慮一下此語句:"I'd like to pay my loan."(我想還貸。)如果僅 根據關鍵字來評估該語句,則可能會將其識別為查詢新貸款,而實際上用戶是想還款,它可能是 AccountInformation 下的二級菜單選項。
“Answer Examples”(答案示例)窗格是您可以添加用戶 可能敘說的語句的位置。您將需要針對每個定義的概念提供一個示例語句。在“Representative”(代表 )節點中,您可能擁有以下語句列表:
"I need to talk to a person."(我需要與某個人 員交談。)
"Can I speak with someone?"(我是否可以與某人通話?)
"I'd like to talk with a representative."(我希望與代表交談。)
接下來,您需要考慮使用關鍵 字,不是用於識別,而是用於擴展已輸入的“Answer Examples”(答案示例)語句。請注意,詞語 “person”(人員)、“someone”(某人)和“representative”(代表)均指同一對象:代表。如果 用戶說 "I need to talk to a representative"(我需要與代表交談)該怎麼辦?不必為每 個“Answer Example”(答案示例)創建三個不同的句子,可通過創建關鍵字來使句子的動態性更強。在 會話語法中使用“Concept”(概念)節點時並非必須使用關鍵字,但它可以節省開發答案語句的時間。 圖 4 顯示了如何通過使用關鍵字來將三個語句合並成一個語句。
在“Conversational Grammar Builder”(會話語法構建器)的“Keywords”(關鍵字)區域中,您將需要一個與“Answers”(答案) 下的“Representative”(代表)節點相對應的關鍵字容器。在此示例中,我將其稱為 RepresentativeKeys。在該節點下,您可能希望“Person”(人員)有一個關鍵字,並且在“Keyword Phrase”(關鍵字語句)區域中添加屬於該主關鍵字的詞語或語句。例如,“Person”(人員)關鍵字可 能具有用戶可用來描述代表的詞語列表,包括“person”(人員)、“representative”(代表)和 “someone”(某人)。
關鍵字的目標不是區分這些詞語,而是顯示用戶可用來描述代表的詞語列表。 如果應用程序需要確定詞語“person”(人員)和“representative”(代表)之間的不同之處,則它們 將成為“Keywords”(關鍵字)下的附加關鍵字容器節點。
現在,在“Representative”(代表)概 念節點上,可引用 RepresentativeKeys 關鍵字節點,然後單擊“Parse”(分析)按鈕。這將替換在概 念語句中找到的關鍵字,並將它們替換成方括號,以表示該詞語不是靜態的,而是屬於所引用關鍵字的一 個變量。綠色復選標記表示語句中使用了關鍵字,而紅色 "x" 表示未使用任何關鍵字。對於 概念類型語法,關鍵字並非必需項,因此語句未引用任何關鍵字是可以接受的,而且是非常可能的情況。
在 QuestionAnswer 活動或接受用戶輸入的任何其他活動中,可引用完整的語法。這可通過 Visual Studio 環境或 code-beside 來實現。與提示類似,如果通過代碼而非 Visual Studio 來設置語法,請 記住事件的執行順序;不必重復設置語法。
處理響應
既然應用程序可以聽說,因此您需要獲得用戶 講話的結果。要通過代碼獲得這些結果,可利用 QuestionAnswer 活動的 RecognitionResult 屬性。您 可以通過 Text 屬性檢索用戶講述的具體語句:
this.questionAnswerActivity.RecognitionResults.Text;
如果用戶回答:"I need to talk to a person"(我需要與某個人員交談),則識別結果 的 Text 屬性會包含該語句。應用程序如何知道語句的意思是他們想與代表通話?這正是 Semantic 值的 用武之地。應用程序並不關心用戶所說的是 "I need to talk to a person"(我需要與某個 人員交談)還是 "Can I speak with someone?"(我是否可以與某人通話?),它只需要知道 他們想與代表通話。
您可以使用 SemanticResult 屬性(而不是 Text 屬性)並提供一個關鍵值。在 本例中,“Concept Answer”(概念答案)名稱 MainMenu 為關鍵值:
this.questionAnswerActivity.RecognitionResults.Semantics [
"MainMenu"].Value.ToString();
此代碼將返回“Concept”(概念)的名稱。如果用戶說:"Can I speak with someone?" (我是否可以與某人通話?),則它將返回 "Representative"(代表)。
您已檢索到結果 ,但現在您需要處理這些結果。通常情況下,在語音響應應用程序中,您最好創建分支以代表每個可能的 選項。如果您通過 Visual Studio 引用語法,則可右鍵單擊 QuestionAnswer 活動,然後選擇 “Generate Branching”(生成分支)。此操作將自動創建每個分支並創建每個分支的條件。或者,您可 以自己創建每個分支,針對根據識別結果用戶進入分支的時間設置條件。例如,在 MainMenu 中,您可能 有一個“Representative”(代表)分支,這會在識別成功時將用戶轉接至代表。
調試和測試
語音響應工作流應用程序的調試過程與您已習慣的過程相同。但是,與大多數其他應用 程序不同的是,您需要能與 IVR 應用程序進行聽說交流。 Speech Server 在 Visual Studio 中添加了 一個“Voice Response Debugging Window”(語音響應調試窗口),如圖 5 所示。
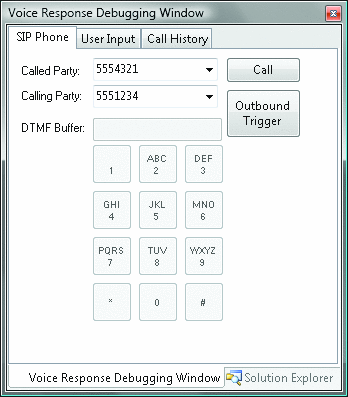
Figure 5 Debugging Window
此調試電話讓您在不實際部署甚至是未連接任何電話線的情況下測試應用程序。您可以使用麥克風來 測試語法,或只是輸入應用程序測試語法所依據的文本。盡管它看起來是個非常簡單的功能,但大多數其 他 IVR 平台都忽略了在不部署的情況下進行測試和調試這一功能。要了解有關 Speech Server 2007 的 詳細信息並下載工具,請參閱 Microsoft 語音技術網站,網址為: microsoft.com/uc/products/speechserver.mspx。