在上期的“CLR 全面透徹解析”中,我強調要可靠地創建高性能的程序,您需要了解設計 初期所使用的各個組件的性能(msdn2.microsoft.com/magazine/cc424899)。這就需要用到性能數據。 因此,測量是設計過程中不可或缺的一部分。
我還在那一期中介紹了一款名為 MeasureIt 的工具,利用它可以輕松地創建新基准,從而快速地收集 制定良好設計決策所需的數據。諸如 MeasureIt 之類的工具所提供的原始數字是極為重要的,另外,使 人們能夠了解這些數字的基本含義也非常重要。在此理解的基礎上,您在實際測量之前即可預測出它的某 些性能。這就是我將在這裡討論的內容。
MeasureIt 概述
如果您尚未下載 MeasureIt 工 具,我強烈建議您立即下載。該工具位於《MSDN® 雜志》網站中本專欄的下載代碼內,由一個 EXE 文件組成。運行它將生成一個網頁,顯示運行某個基准套件的結果。安裝後,可通過運行以下命令訪問其 他文檔:
measureIt /usersGuide
MeasureIt 隨同其源代碼一起出現,使用 /edit 限 制符可以方便地將其解壓縮。這使得添加新基准就像編寫一兩行代碼(並提供要定時的代碼)一樣輕松。 有關如何執行此操作的更多詳細說明,請參閱用戶指南。
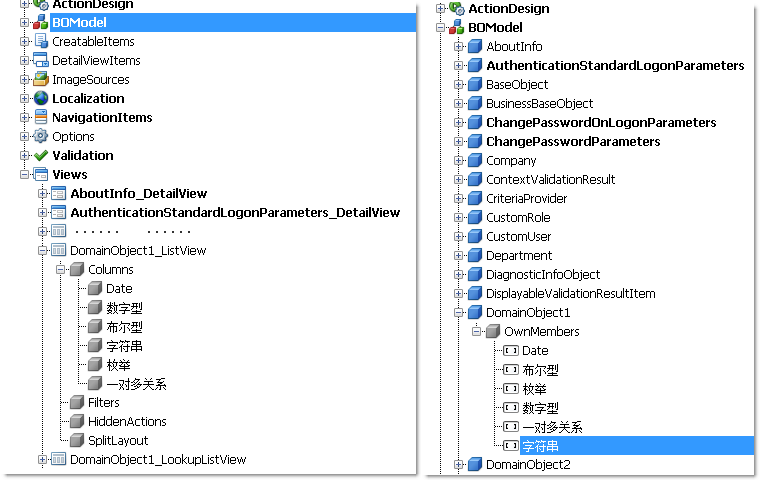
MeasureIt 基准與不同的性能區域相關 聯,當該工具啟動時會在命令行上指示出來。 默認情況下(即無命令行參數),MeasureIt 會運行一組 基准(約 50 個),其中包括各種基本的 Microsoft® .NET Framework 運行時操作。圖 1 中顯示了 簡化的示例輸出。
Figure 1 示例基准
名稱 中值 平均值 標准偏差 最小值 最大 值 示例 NOTHING [count=1,000] 0.000 0.037 0.110 0.000 0.366 10 MethodCalls:EmptyStaticFunction() [count=1000 scale=10.0] 1.000 1.103 0.496 0.857 2.577 10 ObjectOps:new Class() [count=1000 scale=10.0] 5.060 10.223 13.927 3.340 51.215 10 ObjectOps:new FinalizableClass() [count=1000 scale=10.0] 78.552 155.408 168.595 64.997 629.243 10 ObjectOps:(Class) Activator.CreateInstance(classType)] 102.510 102.949 4.076 96.876 109.819 10 Arrays:localIntPtr[i] = 1 [count=1,000 scale=10.0] 0.713 0.664 0.076 0.574 0.773 10 Arrays:string[i] = aString [count=1,000 scale=10.0] 3.402 3.405 0.012 3.397 3.442 10 Delegates:aInstanceDelegate() [count=1,000 scale=10.0] 1.235 1.205 0.111 1.094 1.475 10 MethodReflection:Method.Invoke EmptyStaticFunction() 472.283 472.744 5.409 466.291 482.094 10 P/Invoke:FullTrustCall() [count=1,000] 6.184 6.254 0.793 5.469 7.599 10 P/Invoke:10 FullTrustCall() (10 call average) 2.669 2.688 0.061 2.665 2.870 10 P/Invoke:1 PartialTrustCall [count=1,000] 27.806 30.440 8.735 26.343 56.582 10MeasureIt 將每個基准運行 10 次,並根據結果計算統計數據。這些報告值隨即被標量化 ,從而使對空方法的單個調用花費一個時間單位。例如,圖 1 顯示分配某個小對象的中值時間為 5.06, 這表示通常分配小對象僅是調用方法所花費時間的五倍多一點。但並非所有的情況都是如此。請注意,對 象分配的最長時間要超過 51 個單位。因此,它所花費時間經常要比平均情況更長。事實上,如果該基准 不幸強制收集大量碎片,則其在方法中花費的時間很可能要比此處報告的最大值多出許多。
即便 如此,您還是應該能發現 MeasureIt 工具的價值。幾乎無需進行任何工作,您即可粗略地獲知小型分配 的開銷如何。由於工具會收集多個示例並計算統計數據,因此您還會了解到某些操作(如對象分配)可具 有相當多的變化,這才是重點。通過了解最小值、最大值和標准偏差信息,您可以確定是否足以信賴測量 的可靠性。
幾點快速觀測結論
圖 1 使您大致地了解了在 .NET Framework 中小型對象分配的開銷。您可 以由此迅速推斷出更多信息。例如,您可以猜測到與沒有終結器的對象相比,有終結器(在 C# 中聲明為 ~ClassName())的對象其開銷要多出 10 倍不止。更糟的是這些終結器會被繼承,這意味著任何子類的實 例分配都會處於類似的境遇。因此,通常應盡可能地在將具有多個實例的類中避免使用終結器。
您還可以推斷出與正常分配對象相比,使用反射(如 Activator.CreateInstance 中所示)分配對象的開 銷要多出 10 倍不止。因此使用反射 API 時,其基本原則是:它們比其靜態對等項的開銷要昂貴得多, 如性能要求特別嚴格,則不應使用它們。
此外,從數據中得出的另一個推斷是:與靜態調用方法 相比,使用反射(如 MethodInfo.Invoke 中所示)調用方法要慢 450 倍乃至更多(比值如此之高的部分 原因是常規調用方法的開銷很低)。同樣地,還可以推斷出數組訪問的開銷也會很低(少於方法調用的開 銷),但在對象引用(如 string[] 中所示)的數組中設置元素的開銷是一般數組集的 4 倍以上。您還 可以從圖 1 中看出,調用委托(指向某個方法的指針)在編譯時間上僅僅比調用其目標已知的方法慢 20%。
最後,您可以得出結論:當禁止安全檢查時,調用非托管代碼 (P/Invoke) 的開銷並不昂貴 (普通方法調用的 6 倍),如果從同一方法中多次調用會使平均開銷更為低廉(2.6 倍)。但在使用安 全檢查時(默認設置),開銷將顯著增加(普通方法調用的 27 至 30 倍)。
目前,已經能通過 內置的 MeasureIt 基准得出一些有用的觀測結論。此外,由於下載的 MeasureIt 內含源代碼,您可以獲 得所有必需的詳細信息以對數據進行更深入的研究。例如,您可能想要了解如何准確地禁止 P/Invoke 調 用的安全檢查(或了解如何首先調用本機代碼)。要執行此操作,請使用以下命令解壓縮源代碼:
measureIt /edit
然後搜索 P/Invoke 基准。您將獲得所需的確切代碼,然後根據自 己的目的進行分析、調試,甚至是修改。
驗證數據
MeasureIt 可以快速地告知您 .NET 運 行時進行某些基本操作的開銷,但無法告訴您這些數字是如何得來的。很有可能您當前測量的對象並不是 您所要測量的對象。
在上月的專欄中,我著重指出極易創建誤導基准(特別是微基准),強調了 在信任性能測量前對其進行驗證的重要性。請牢記,您還必須驗證內置基准中的數據。
這就是 .NET 運行時內部的某些專業技術很有用的原因所在。在具體地了解了運行時內的操作如何轉換為機器指 令後,我就能估計出各種操作所花費的時間。圖 2 中對此進行了總結。由於硬件自身進行了優化,指令 數並不與執行時間精確對應;盡管如此,它們提供了良好的近似預測。如果您發現指令執行時間遠超出您 根據指令數得出的預期時間,很有可能是數據不正確。最好將圖 2 中所示數據視為操作的定量法,它們 極好地佐證了 MeasureIt 的定量法。
Figure 2 MeasureIt 中的 .NET 運行時操作性能
操作 指令數 注釋 整數運算 1 不受限的簡單運算可編譯為其對應的機器指令,開銷通常小於一個機器周期。 浮點運算 1 編譯為 x87 指令(對於 32 位)。目前,運行時無法 執行向量化或充分利用較新的硬件指令 (SSE2),因此,通常最佳的非托管編譯器能較好地支持內含浮點 的應用程序。 實例字段提取或設置 1-10 大多數操作都采取 1 條 指令。但設置作為對象參照(非基元類型)的字段需要使用花費 6-10 條指令的寫屏障例程。 靜態字段提取 1-12 通常情況下,在一個 AppDomain 中運行的實 時 (JIT) 編譯代碼僅需花費 1 條指令。但諸如 ASP.NET 此類的宿主可要求運行時生成所有 AppDomain 可共享(節省了大量的內存和 JIT 時間)的代碼,開銷是花費 12 條指令提取靜態字段。JIT 編譯器會 將此類普通運算提升到循環以外,從而部分減輕這種開銷。生成用本機映像生成器 (Ngen) 預編譯的代碼 時,它不考慮所請求的代碼共享,這意味著即使在最佳情況下,Ngen 生成的代碼也將花費 6 條指令來提 取靜態字段。 非虛擬或靜態方法調用 1 編譯為單個調用指令,調 用速度最快。 虛擬方法調用 2 使用類似 C++ 的調度表。這是速度 最快的間接調用。 接口方法調用 4-20 當特定的調用點幾乎始終具 有同一目標時,接口方法通過極快(共花費 4 條指令)的存根進行調度。如將單個調用點調度到多個目 標,將花費 10-20 條指令查找哈希表以進行調度。 委托調度 4- 15 如果存在單個目標方法且其為實例(非靜態)方法,則一般會花費 4 條指令,且其速度可比 得上任何其他類型的間接調度。如果目標為靜態,則需要混排參數來移除傳遞來的“這個”無 用指針,這會耗費數條指令。如果某個委托具有多個訂閱者(事件可做到這一點),則調度必須包含一個 循環,開銷也隨之增大,但這種情況並不常見。 對象分配 10- 1,000+ 對於大多數對象,新代碼路徑將耗費 10-15 條指令;而某些對象類型(如可終結對象) 開銷會更多。無論怎樣,分配都會導致後來增加大量開銷。這其中包括清除內存的開銷(與其大小成正比 )和在對象存在時某些垃圾收集 (GC) 過程中的掃描開銷。短時間存在的對象所導致的 GC 額外開銷明顯 要比長期對象少得多,盡管如此,開銷仍然過高,對注重性能的代碼路徑應將分配降至最小。 數組訪問 1-25 數組訪問通常需要耗費兩條指令:邊界檢查和提取 。對於簡單的循環(您需要迭代數組中的所有元素),JIT 編譯器可避免邊界檢查,使其簡化為一個指令 。事實上,這種優化會導致使用不安全的指針訪問替代數組訪問,它並不會顯著提高性能。如果設置的元 素是一個對象參照,則該設置需要寫屏障和類型檢查,這會將代碼路徑的大小增加至約 25 條指令。 轉換 4-100+ 成功地將對象轉換為其確切的類型速度較快(4 條指 令);但轉換為超類的速度較慢,而轉換為接口的速度更慢。轉換數組的速度也非常慢。失敗的轉換(通 常是使用 C# 的 "is" 或 "as" 運算符的情況)也相對較慢。 鎖定 20-1,000+ 即使在最理想的情況下,進入和退出鎖(System.Monitor.Enter 或 c# lock 語句)的開銷也是較為昂貴的(一個 call-ret 的 10 到 15 倍)。如果該鎖存在爭用,則速度 顯著變慢。 P/Invoke 調用 15-1,000+ 在最理想的情況下(禁止安 全檢查且無需參數轉換),從托管代碼中調用本機代碼 (P/Invoke) 需要 15-20 條指令。當其中有字符 串傳遞(需要轉換)和/或涉及 COM 互操作時要更慢一些。 反射 1,000- 10,000+ 根據類型(例如 System.Type.GetType)調用簡單反射的開銷較低(< 10 條指令) ;但使用反射 API 執行任何其他操作(如調用方法、設置字段或創建對象)的開銷都明顯比其他非反射 替代方法更為昂貴(10 至 100 倍)。通常不應在注重性能的代碼路徑中使用反射。 泛型 任意 泛型類型的性能與其對應非泛型類型的性能相似。如果泛型類型的類型參數 為類(而非結構),則該類型的所有實例之間將共享該代碼。這種共享可節省空間,但同時意味著依賴類 型參數的操作將比預期要慢。如果在注重性能的路徑中使用泛型,則應進行測量。圖 2 中的信息對於驗證 MeasureIt 所提供的性能數字非常有用,但只能供您對程序和各種設計權衡 方法的開銷進行粗略的預測。例如,您可以預測兩種跨越托管-非托管 (P/Invoke) 邊界的頻率不同的代 碼構建設計之間的開銷權衡。還可以預測通過避免使用反射方法節約的開銷數量,或向程序中加鎖以保證 其線程安全的成本。
注意事項
就個人而言,我認為 MeasureIt 生成的數據對很多性能決策都非常有幫助。但內置基准的側重點卻是 許多耗費 CPU 資源的操作。如果您的應用程序的性能不受 CPU 的限制,沒有必要將重點放在 CPU 優化 上。在下列三種情況中 CPU 不是關鍵的性能因素:應用程序響應時間取決於 I/O 開銷或網絡延遲;應用 程序響應時間取決於內存緩存開銷;以及在多線程應用程序中,應用程序響應時間受線程序列化延遲的影 響。
某些應用程序的性能受它們操作磁盤和網絡 I/O 的速度的影響,會比實際指令執行時間慢很多倍。當 應用程序啟動時,如果應用程序請求內存中尚未緩存的文件,則會發生此類情況(冷啟動)。當應用程序 消耗的內存導致許多頁面錯誤時也會發生此類情況。通常,如果您的應用程序並未完全占用處理器資源, 這些其他的延遲就凸顯重要了。我在這裡提供的大多數信息與這種情況並不相關,本專欄側重的是找出與 CPU 相關的性能瓶頸。
對於其他的應用程序,響應時間取決於內存緩存的開銷。當您使用大型的內存中的數據結構時通常會 發生此情況。看上去該應用程序受到 CPU 的限制(它會占用所有處理器資源),但實際上 CPU 大多數時 間是在等待內存子系統。您可能需要使用分析器訪問內存子系統的統計數據以對此情況進行診斷,但較大 的內存消耗 (> 50MB) 以及出現大量的頁面錯誤一般表明內存問題是一個影響因素。在此情況下,您 通常應當采用的設計策略是精簡(即使這樣會增加執行指令的數量)。
在多處理器硬件上運行多線程應用程序時,發生線程延遲的情況並不罕見,因為它們需要等待進入代 碼的關鍵節-而代碼每次僅允許一個線程進行訪問。隨著並發執行線程數的增加,這些序列化延遲趨向於 更為嚴重。這種鎖競爭可表現為不受 CPU 限制(當等待時間較長,而等待線程進入休眠狀態時)或受 CPU 限制(當等待時間很短,但發生頻率極為頻繁時)。
要將這些非 CPU 問題解釋清楚以產生良好的設計直覺,可能還另外需要一個或兩個專欄。只要記住, 內存消耗很重要(特別是對於大型應用程序),當指令數適中時,您應嘗試減小大於 1MB 的數據結構的 尺寸。
但如果您的應用程序在其運行時占用所有 CPU 資源(頁面錯誤很少或沒有),在受 CPU 限制時(熱 數據結構均小於 1MB)消耗的內存不大,且並不屬於依賴於共享數據的高度並行化應用程序,則您的性能 問題很可能與所執行的指令數量相關。因此,圖 2 中的信息以及 MeasureIt 提供的數據在預測性能時將 會很有用。
不均衡性能的前景
只要有可能,.NET 運行時團隊就會盡力設法對操作進行優化。一般而言,這是件好事,但這確實預示 著一種不均衡性能,因為很多情況下無法應用優化。我們已經看到了這樣的一個示例:可終結的分配。這 裡提供了更多這樣的示例。
首先,在某些情況下,特定的調用點往往會被調度到同一目標,此時,接口調用會進行高度優化。例 如,您可以使某個例程采用 List<object> 並對每個元素調用 ICompareable.Compare。如果此操 作傳遞了某個字符串“列表”,則接口調用會始終調用 String.Compare 且速度很快。 但如果該列表內 包含多種不同的類型,則同一調用點必須調度給多個不同的目標。這後一種情況的速度會顯著變慢。
其次,當需要將基元類型(如 int)傳遞到期望獲得對象的操作中時,必須將值轉換為對象(此操作 被稱為“裝箱”)。這時需要對象分配,因此開銷會超出預期。通常,編譯器會自動插入此裝箱,由於整 個過程過於粗糙,因此可能會掉進此陷阱中。
再次,使用 C# 變量參量參數功能的方法(如 Console.WriteLine)需要為每次調用分配一個數組, 還可能要為某些參數裝箱(分配)對象。這使得該調用的開銷遠遠大於普通調用(高出 10 倍)。這樣的 示例不勝枚舉,但列出的這些已足以說明問題。
盡管了解運行時本質的人士會就上述某些事實對您提出警告,但實際情況要遠超出所列的示例。這就 是圖 2 中的信息和從 MeasureIt 中收集的數據只能用作粗略估計的原因。您永遠不會知道自己何時會遇 到性能糟糕的代碼。因此,應時刻注意:如果熱代碼路徑有可能未經優化,則您不應單獨依靠從圖 2 中 推斷出的結論,而應編寫快捷的微基准來精確表示熱代碼的路徑並親自進行測量。
請將您想詢問的問題和提出的意見發送至 clrinout@microsoft.com.
本文配套源碼:http://www.bianceng.net/dotnet/201212/758.htm